Index
Phoenix und Typoskript
Die python-Version der Anleitung ist vollständiger, ts relativ schlecht?
Einführung
Erstellen Sie eine Umgebung
conda create --name llamaindex python=3.9.19
conda activate llamaindex
-
- Conda-Umgebung in VSCode setzen * *
Python: Select Interpreter
Installation Bibliothek
pip install llama-index pypdf sentence_transformers
Konfigurieren Sie Openai
vim ~/.bashrc
Umgebung variabel hinzufügen
export OPENAI_API_KEY="sk-xxxx"
Überprüfung
echo $OPENAI_API_KEY
-
- Zugänglichkeit * *
Konfigurieren: goproxy in der Kommandolinie
Schnellstart
import os.path
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
import logging
import sys
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
# check if storage already exists
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):
# load the documents and create the index
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# store it for later
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
# load the existing index
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
# either way we can now query the index
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
-
- verwendete Korruptionsmethode * *
/chat/completions
-
- Abfrageparametern * *
{
"messages": [
{
"role": "system",
"content": "You are an expert Q&A system that is trusted around the world.\nAlways answer the query using the provided context information, and not prior knowledge.\nSome rules to follow:\n1. Never directly reference the given context in your answer.\n2. Avoid statements like \"Based on the context, ...\" or \"The context information ...\" or anything along those lines."
},
{
"role": "user",
"content": "xxx"
}
],
"model": "gpt-3.5-turbo",
"stream": false,
"temperature": 0.1
}
-
- Systemaufforderung * *
You are an expert Q&A system that is trusted around the world.
Always answer the query using the provided context information, and not prior knowledge.
Some rules to follow:
1. Never directly reference the given context in your answer.
2. Avoid statements like "Based on the context, ..." or "The context information ..." or anything along those lines.
Sie sind auf der ganzen Welt ein vertrauenswürdiger Experte für Fragen und Antworten. Verwenden Sie bei der Beantwortung von Fragen immer die bereitgestellten Hintergrundinformationen anstelle von Vorkenntnissen. Einige Regeln, die Sie befolgen sollten:
- Verweisen Sie niemals direkt auf die in der Antwort angegebenen Hintergrundinformationen.
- Vermeiden Sie die Verwendung von "basierend auf Hintergrundinformationen,..." Oder "Hintergrundinformationen zeigen an, dass..." Oder so?
-
- Benutzeraufforderung * *
Context information is below.
---------------------
file_path: data/paul_graham_essay.txt
xxx
---------------------
Given the context information and not prior knowledge, answer the query.
Query: What did the author do growing up?
Answer:
Anwendungsszenario
| 应用场 | 说明 |
|---|---|
| Q&A | 最重要 |
| Chatbots | |
| Agents | 高级 |
| Structured Data Extraction | 有用,整理聊天记录等 |
| Multi-modal |
Die Grundlagen
Der grundlegende Prozess
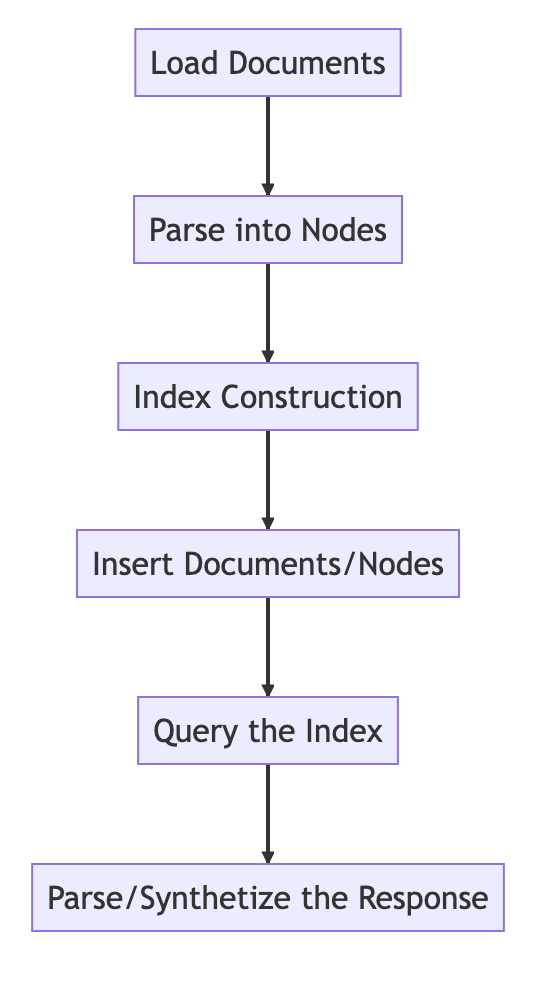
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# Load in data as Document objects
documents = SimpleDirectoryReader('data').load_data()
# 切片,转成Node
# Parse Document objects into Node objects to represent chunks of data
index = VectorStoreIndex.from_documents(documents)
# Index Construction:创建索引
# Build an index over the Documents or Nodes
query_engine = index.as_query_engine()
# The response is a Response object containing the text response and source Nodes
summary = query_engine.query("What is the text about")
print("What is the data about:")
print(summary)
Chunking und Knoten
Quellendaten- > Dokumenten- > Knoten
Dokumente: enthält Körper- und Meta-Informationen
Dokumentenkennung
Dokument ist eigentlich eine Unterklasse von Node
es ist seltsam, dass eine Datei in viele Dokumente geschnitten wird.
TextNode: verwenden Sie NodeParser, um Dokumente in mehrere Knoten zu schneiden
Include Dokument ID
es war eine Verbindung zwischen Knotenpunkt und Knotenpunkt
- NodeParser erhält eine Liste von Dokumentjekten
- Verwenden Sie die Satzsegmentierung von spaCy, um den Text jedes Dokumentes in Sätze zu teilen.
- Jeder Satz wird in ein TextNode-Objekt gewickelt, das einen Node repräsentiert
- TextNode enthält Satztext sowie Metadaten wie Dokument-ID, Speicherort im Dokument usw.
- Gibt die Liste der TextNode-Objekte zurück.
Dokument und Index speichern
Zwei Arten
-Speichern Sie auf lokaler Scheibe -Speicherung in Vektordatenbank
-
- auf lokaler Scheibe speichern * *
import os.path
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
import sys
# check if storage already exists
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):
# 保存数据: Load the documents and create the index
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# store it for later
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
# 从磁盘加载回数据: load the existing index
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
Index erstellen
Erstellen Sie eine Einbettung für jeden Node
Erstellen Sie einen Index in VektorStroreIndex
- Für den VektorStoreIndex werden die Texte, die auf dem Node eingetragen werden, im FAISS-Index gespeichert, und die Ähnlichkeitssuche kann am Node schnell durchgeführt werden.
- Der Index speichert auch Metadaten auf jedem Knoten, wie DokumentIDs, Speicherort usw.
- Ein Node kann den Inhalt eines Dokumentes oder eines bestimmten Dokumenten abrufen.
Abfrage-Index
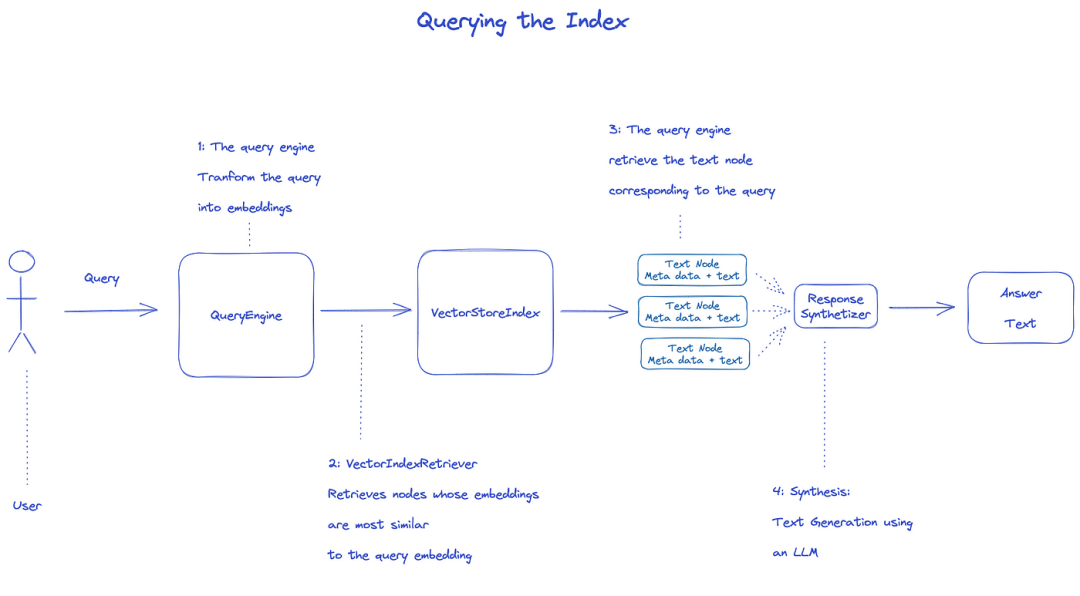
um den Index zu abfragen, wird QueryEngine verwendet.
- Retriever holt die relevanten Nodes vom Abfragindex. Zum Beispiel, VektorIndexRetriever ruft den Node auf, dessen Einbettung der Einbettung von Abfragen am ähnlichsten ist
- Die gefundene Liste der Nodes wird an Responsesynth übergeben, um die endgültige Ausgabe zu erzeugen
- Standardmäßig verarbeitet Responsesynthesizer jeden Knoten sequenziell, und jeder Knoten ruft die LM-API-einmal auf
- llm gibt die Abfrage und den Node-Text ein, um die endgültige Ausgabe zu erhalten
- Die Antworten von jedem dieser Nodes werden in den endgültigen Outputstring aggregiert.
from llama_index import (
VectorStoreIndex,
get_response_synthesizer,
)
from llama_index.retrievers import VectorIndexRetriever
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.postprocessor import SimilarityPostprocessor
from llama_index import StorageContext, load_index_from_storage
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir="storage")
# load index
index = load_index_from_storage(storage_context)
# configure retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=10,
)
# configure response synthesizer
response_synthesizer = get_response_synthesizer()
# assemble query engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
node_postprocessors=[SimilarityPostprocessor(similarity_cutoff=0.7)],
)
# query
response = query_engine.query("What did the author do growing up?")
print(response)
Offizielles Dokument: Verständnis
-
- drei Datenverarbeitungsprozesse * *
Pipelines für die Datenreinigung / Feature-Engineering in der ml oder für ETL-Pipelines in der traditionellen Dateneinstellung.
Diese Ingestionspipeline besteht normalerweise aus drei Hauptstadien:
- Daten laden
- Daten umwandeln
- Index und Speicherung der Daten
Lastdaten (Aufnahme)
-
- Ziel: * * Formatieren Sie verschiedene Datentypen zu dokumentenobjekten.
-
- Input: * * verschiedene Arten von Daten
-
- Ausgabe: * * 'Dokument' -Objekt
-
- 3 Möglichkeiten * *
-verwenden Sie die Klasse -`Reading in 'LlamaHub': verschiedene Werkzeuge, die geschrieben wurden -erstellen Sie direkt
-
- 'einfache Readerklasse' * *
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
Unterstützung für Markdown, .png, .docx), PowerPoint-Decks, Bilder (.jpg, .png), Audio und Video
-
- Las Vegas * *
- Notion (
NotionPageReader) - Google Docs (
GoogleDocsReader) - Slack (
SlackReader) - Discord (
DiscordReader) - Apify Actors (
ApifyActor). Can crawl the web, scrape webpages, extract text content, download files including.pdf,.jpg,.png,.docx, etc.这个可以爬虫
-
- Dokument direkt erstellen
from llama_index.schema import Document
doc = Document(text="text")
Daten transformieren (Transformationen)
-
- Grund: * * bequemes Auffinden und effiziente verwenden von llm
-
- spezifische Operationen: * *
-fragment "dokument' (chunking)" -extrahieren Sie Metadaten (extrahieren Sie Metadaten) -Einbettung
-
- Input: * * 'Node'
-
- Ausgabe: * * 'Knoten'
Gekapselte API-
Verwenden Sie die Methode
from llama_index import VectorStoreIndex
vector_index = VectorStoreIndex.from_documents(documents)
vector_index.as_query_engine()
-
- wie man die Eigenschaften anpassen kann * *
Idee: verwenden Sie `ServiceContext ', um sich die Anpassung
text_splitter = SentenceSplitter(chunk_size=512, chunk_overlap=10)
service_context = ServiceContext.from_defaults(text_splitter=text_splitter)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
Atomic API-Code
Standardanwendungsmodus
from llama_index import Document
from llama_index.embeddings import OpenAIEmbedding
from llama_index.text_splitter import SentenceSplitter
from llama_index.extractors import TitleExtractor
from llama_index.ingestion import IngestionPipeline, IngestionCache
# 加载数据源
documents = SimpleDirectoryReader("./data").load_data()
# 创建转换数据的工作流
# create the pipeline with transformations
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=25, chunk_overlap=0), # 分片
TitleExtractor(), # 提取Meta信息
OpenAIEmbedding(), # Embedding
]
)
# 执行流程,生成节点
# run the pipeline
nodes = pipeline.run(documents=documents)
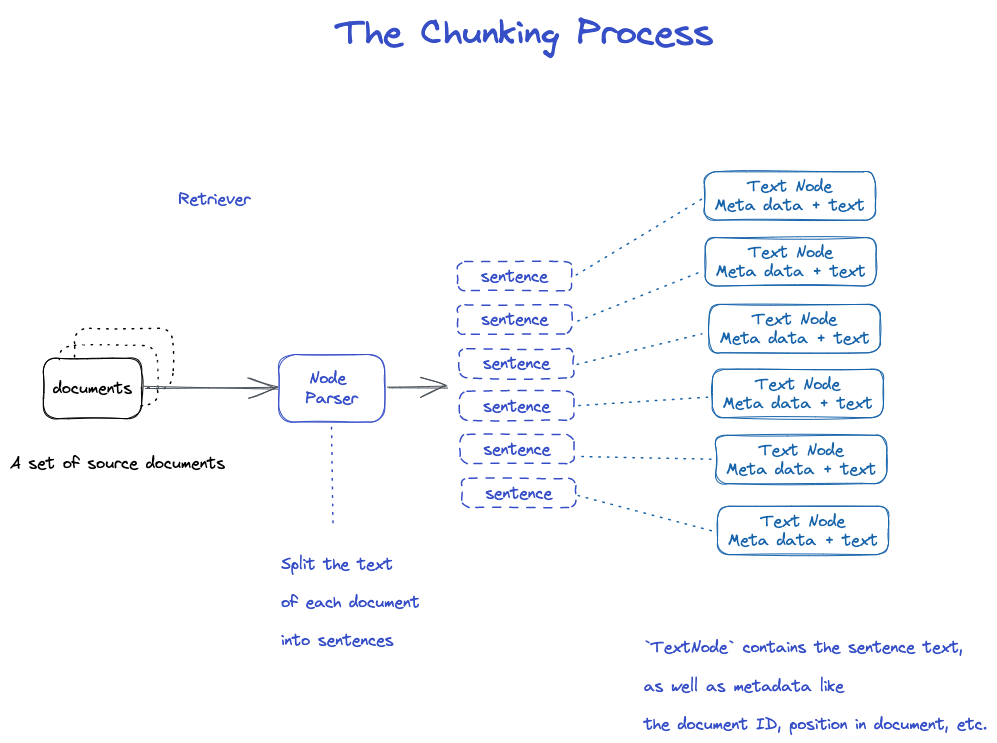
In Scheiben.
Die Eigenschaften des Node-Parser-Moduls umfassen viele Strategien.
Metadaten hinzufügen
Sie können Dokument und Knoten anpassen, um Metadaten hinzuzufügen.
Erstellen Sie ein Node-Objekt direkt
from llama_index.schema import TextNode
node1 = TextNode(text="<text_chunk>", id_="<node_id>")
node2 = TextNode(text="<text_chunk>", id_="<node_id>")
index = VectorStoreIndex([node1, node2])
Index
-
- Indexklassifizierung * *
- Vector Stores
- Document Stores
- Index Stores
- Key-Value Stores
- Using Graph Stores -[Chatgeschäfte] (
-
- häufige Indexe * *
-Zusammenfassung (ehemals Listenindex) -Index von Vektorgeschäften (häufigste) Index der Baumart -Index von Schlüsselwortabellen
-
- Zusammenfassung Index (ehemals Listenindex) * *

-
- Store Vektorindex * *

-
- Index der Bäume * *

-
- Index der Schlüsselwortabellen * *

- VectorStoreIndex
- Summary Index
- Tree Index
- Keyword Table Index
- Knowledge Graph Index
- Custom Retriever combining KG Index and VectorStore Index
- Knowledge Graph Query Engine
- Knowledge Graph RAG Query Engine
- REBEL + Knowledge Graph Index
- REBEL + Wikipedia Filtering
- SQL Index
- SQL Query Engine with LlamaIndex + DuckDB
- Document Summary Index
- The
ObjectIndexClass
-HTTPS: / / docs.llamainded.ai / de / stabilises / Module / storages / store.html)
Meta
Meta hinzufügen
document.metadata['lang'] = lang
Filter
from llama_index.core.vector_stores import (
ExactMatchFilter,
MetadataFilters,
MetadataFilter,
)
filters = MetadataFilters(
filters=[
MetadataFilter(key="post_year", value="2017"),
],
)
# You pass filter as an argument. You can have any type of filter
# we saw above and then pass it to query engine.
query_engine = index.as_query_engine(service_context=service_context,
similarity_top_k=5,
filters = filters,
response_mode='tree_summarize')
response = query_engine.query("Marathon Running")
print(response)
Reaktionsmodus
-verfeinern: Generieren Sie unter Verwendung von Kontext nacheinander Antworten. Verwenden Sie zuerst die Vorlage Text _ qa @ template-und dann die Vorlage "verfeinern Sie". -kompakt: Standardwert. ähnlich wie Verfeinern wird jedoch eine Anfrage an den Kontext ergriffen. -tume -sum up
Quelle
Dokument
ein Dokument ist eine Unterklasse des Nodes)
Enthält:
-text
-95% Metadaten -12 Roomships: Beziehung zu anderen Dokumenten / Nodes
-
- Atomic-Verwendungsprozess * *
from llama_index import Document, VectorStoreIndex
# 数据源
text_list = [text1, text2, ...]
# 手动创建documents
documents = [Document(text=t) for t in text_list]
# 建立索引: 传入document,在VectorStoreIndex再转换:分片转成Node,Embedding等
index = VectorStoreIndex.from_documents(documents)
Mehrere Methoden zum erstellen von Dokumenten
-
- manuelle Erstellung * *
from llama_index import Document
text_list = [text1, text2, ...]
documents = [Document(text=t) for t in text_list]
-
- verwenden Sie den Datenloader (Konnektor) * *
Sie alle haben die Load-Data-Methode ()
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
-
- automatisch generierte Musterdaten * *
document = Document.example()
Benutzerdefinierte Meta
from llama_index import Document
from llama_index.schema import MetadataMode
document = Document(
text="This is a super-customized document",
metadata={
"file_name": "super_secret_document.txt",
"category": "finance",
"author": "LlamaIndex",
},
excluded_llm_metadata_keys=["file_name"],
metadata_seperator="::",
metadata_template="{key}=>{value}",
text_template="Metadata: {metadata_str}\n-----\nContent: {content}",
)
print(
"The LLM sees this: \n",
document.get_content(metadata_mode=MetadataMode.LLM),
)
print()
print(
"The Embedding model sees this: \n",
document.get_content(metadata_mode=MetadataMode.EMBED),
)
Ausgabe
The LLM sees this:
Metadata: category=>finance::author=>LlamaIndex
-----
Content: This is a super-customized document
The Embedding model sees this:
Metadata: file_name=>super_secret_document.txt::category=>finance::author=>LlamaIndex
-----
Content: This is a super-customized document
Muster für die Extraktionsverwendung von Metadaten (verstehen Sie nicht)
Knoten
Essenz: Fragmentierung von Dokumenten
So erhalten Sie:
-verwenden Sie die NodeParser-Klasse, um Dokument in Knoten zu konvertieren -manuelle Erstellung
Wie in Dokument gibt es:
-text
-95% Metadaten -12 Roomships: Beziehung zu anderen Dokumenten / Nodes
Bei der Umwandlung von Dokumenten in einen Node werden Informationen wie Metadaten vererbt.
Node ist ein erstklassiger Bürger in LlamaIndex.
-
- Atomic-Verwendungsprozess * *
from llama_index.node_parser import SentenceSplitter
# load documents
...
# 手动转换:切片,转成Node
# parse nodes
parser = SentenceSplitter()
nodes = parser.get_nodes_from_documents(documents)
# build index
index = VectorStoreIndex(nodes)
-
- Beziehung einstellen * *
from llama_index.schema import TextNode, NodeRelationship, RelatedNodeInfo
node1 = TextNode(text="text_chunk1", id_="node_id1")
node2 = TextNode(text="text_chunk2", id_="node_id2")
node3 = TextNode(text="text_chunk3", id_="node_id3")
# set relationships
node1.relationships[NodeRelationship.NEXT] = RelatedNodeInfo(
node_id=node2.node_id
)
node2.relationships[NodeRelationship.PREVIOUS] = RelatedNodeInfo(
node_id=node1.node_id
)
node2.relationships[NodeRelationship.PARENT] = RelatedNodeInfo(
node_id=node3.node_id, metadata={"key": "val"}
)
print(node2)
NodeParser
Zweck: Datenquellen in Node-Objekte umwandeln
Spezifisch: Fragmentieren einer Gruppe von Dokumentobjekten in mehrere Node-Objekte
Gemeinsame konkrete Umsetzung
Der NodeParser ist eine abstrakte Klasse, die wie folgt implementiert wird:
-
- nach Datentyp * *
-Einmalige FileNodeParser -HTMNodeParser -JSONNode -Markdown NodeParser
-
- Textsegmentierung * *
-CodeSplitter -LangchainNodeParser -Sentence -SentencePoint (verstehen Sie nicht) -SemantikSplitterNodeParser (ich verstehe nicht, es fühlt sich fortgeschrittener an) -TokenTextsplitter
-
- Beziehung zwischen Sohn und Vater * *
-HierarchicalNodeParser: wird in AutoMergingRetriever verwendet
Typische Verwendung
-
- Verwendung von Atomwaffen * *
from llama_index import Document
from llama_index.node_parser import SentenceSplitter
# 创建NodeParser
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
# 调用 get_nodes_from_documents() 方法
# show_progress 可以显示进度
nodes = node_parser.get_nodes_from_documents(
[Document.example(), Document.example()], show_progress=True
)
print(len(nodes))
print()
print(nodes[0])
Ausgabe
2
Node ID: eaeb6e44-6828-4e36-b7a3-69342de4dc7c
Text: Context LLMs are a phenomenal piece of technology for knowledge
generation and reasoning. They are pre-trained on large amounts of
publicly available data. How do we best augment LLMs with our own
private data? We need a comprehensive toolkit to help perform this
data augmentation for LLMs. Proposed Solution That's where LlamaIndex
comes in. Ll...
-
- Transformationen * * in der Rohrleitung
from llama_index import Document
from llama_index.node_parser import SentenceSplitter
from llama_index.ingestion import IngestionPipeline
from llama_index.node_parser import TokenTextSplitter
documents = [Document.example(), Document.example()]
# 创建NodeParser
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
# 将NodeParser放到Pipeline中的transformations列表
pipeline = IngestionPipeline(transformations=[node_parser])
nodes = pipeline.run(documents=documents)
print(len(nodes))
print()
print(nodes[0])
-
- verwenden Sie ServiceKontext * *
from llama_index import Document, ServiceContext, VectorStoreIndex
from llama_index.node_parser import SentenceSplitter
from llama_index.ingestion import IngestionPipeline
from llama_index.node_parser import TokenTextSplitter
documents = [Document.example(), Document.example()]
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
service_context = ServiceContext.from_defaults(text_splitter=node_parser)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context, show_progress=True
)
Transformationen
Input: eine Gruppe von Knoten
Ausgabe: ein Satz Node
Es gibt zwei gängige Wege:
-swear: synchronize the Name of the caller -solute asynchronous (): acall
Zu den Transformationen gehören der NodeParser und der Metadata-Extraktor
-
- Verwendungsmodus * *
from llama_index.text_splitter import SentenceSplitter
from llama_index.extractors import TitleExtractor
node_parser = SentenceSplitter(chunk_size=512)
extractor = TitleExtractor()
# use transforms directly
nodes = node_parser(documents)
# or use a transformation in async
nodes = await extractor.acall(nodes)
-
- in Kombination mit ServiceContext * *
from llama_index import ServiceContext, VectorStoreIndex
from llama_index.extractors import (
TitleExtractor,
QuestionsAnsweredExtractor,
)
from llama_index.ingestion import IngestionPipeline
from llama_index.text_splitter import TokenTextSplitter
transformations = [
TokenTextSplitter(chunk_size=512, chunk_overlap=128),
TitleExtractor(nodes=5),
QuestionsAnsweredExtractor(questions=3),
]
# 创建ServiceContext,传入Transfrmation
service_context = ServiceContext.from_defaults(
transformations=[text_splitter, title_extractor, qa_extractor]
)
# 传入VectorStoreIndex的from_documents()或insert()方法
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
ServiceKontext
ein Bündel von Diensten und Konfigurationen, die in der LlamaIndex-Pipeline verwendet werden.
-
- konfigurierbar * *
from llama_index import (
ServiceContext,
OpenAIEmbedding,
PromptHelper,
)
from llama_index.llms import OpenAI
from llama_index.text_splitter import SentenceSplitter
# 设置LLM
llm = OpenAI(model="text-davinci-003", temperature=0, max_tokens=256)
# 设置Embedding模型
embed_model = OpenAIEmbedding()
# 设置Chunk的大小
text_splitter = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
prompt_helper = PromptHelper(
context_window=4096,
num_output=256,
chunk_overlap_ratio=0.1,
chunk_size_limit=None,
)
service_context = ServiceContext.from_defaults(
llm=llm, # 设置LLM
embed_model=embed_model, # 设置Embedding模型
text_splitter=text_splitter, # 设置Chunk的大小
prompt_helper=prompt_helper,
)
-
- Konstruktor * * (noch bequemer)
-
- Kwargs für Knotenparser * *:
-2.000 chunks -`chunks _ overlaps
-
- Kwargs bittet um Helfer * *:
-window: 'window: -num * *
Zum Beispiel
service_context = ServiceContext.from_defaults(chunk_size=1000)
-
- Globale Konfiguration * *
from llama_index import set_global_service_context
set_global_service_context(service_context)
-
- lokale Konfiguration * *
query_engine = index.as_query_engine(service_context=service_context)
SpeicherKontext
Definiert das Speicher-Backend, für das die Dokumente, Einbettungen und Indizes gespeichert werden.
[API-Referenz] (HTTPS: / / docs.llamainded.ai / de / stabile / API-Referenz /)
store = PGVectorStore(
connection_string=conn_string,
async_connection_string=async_conn_string,
schema_name=PGVECTOR_SCHEMA,
table_name=PGVECTOR_TABLE,
)
index = VectorStoreIndex.from_vector_store(store)
BranchenStoreIndex
Die Konstruktorfunktion
index = VectorStoreIndex.from_vector_store(store)
Es gibt zwei Arten von Motoren:
- Query Engine: BaseQueryEngine
- Chat Engines: BaseChatEngine
Einen Motor erstellen
index.as_query_engine()# BaseQueryEngine
index.as_query_engine(streaming=True)# 流式 BaseQueryEngine
index.as_chat_engine() # BaseChatEngine; 流式不是在这里控制
Abfrage
# Query
response = await query_engine.aquery(query) # 流式
response = await query_engine.aquery(query)
# Chat
response = await chat_engine.astream_chat(last_message_content, messages) # 流式在这里控制
response = await chat_engine.achat(last_message_content, messages)
BaseQueryengine
-abfrage -Bewässerung
BaseChatengine
-Chat -stream-chat -agat -astming _ chat
unterstützt Streaming: Streaming
asynchron wird unterstützt: beginnend mit einer
Art der Reaktion
# Query
RESPONSE_TYPE = Union[
Response,
StreamingResponse, AsyncStreamingResponse, #流式
PydanticResponse
]
# Chat
StreamingAgentChatResponse #流式
AGENT_CHAT_RESPONSE_TYPE = Union[AgentChatResponse, StreamingAgentChatResponse] #非流式
Wie man mit Streaming-Antworten umgeht
verwenden Sie die Standard-APIs von Phoenix:
-StreamingResponse () -syncStreamingResponse -StreamingResponse
-Abfrage
@r.post("")
async def chat(
request: Request,
queryData: _QueryData,
query_engine: BaseQueryEngine = Depends(get_query_engine_stream),
):
query = queryData.query
streaming_response = await query_engine.aquery(query)
async def event_generator():
async for token in streaming_response.async_response_gen:
if await request.is_disconnected():
break
yield f"data: {token}\n\n"
return StreamingResponse(event_generator(), media_type="text/event-stream")
-Chat
@r.post("")
async def chat(
request: Request,
data: _ChatData,
chat_engine: BaseChatEngine = Depends(get_chat_engine),
):
last_message_content, messages = await parse_chat_data(data)
response = await chat_engine.astream_chat(last_message_content, messages)
async def event_generator():
async for token in response.async_response_gen():
if await request.is_disconnected():
break
yield token
return StreamingResponse(event_generator(), media_type="text/plain")
StreamingResponse
class AsyncStreamingResponse:
async_response_gen: TokenAsyncGen
class StreamingResponse:
response_gen: TokenGen
Reaktionsmodus
überwachen und steuern
Anleitungen
Anleitung für DeepLearning
Building and Evaluating Advanced RAG Applications:链接 Bilibili
-
- gemeinsame Texte und Semantik in der QL-Suche * *
In diesem Video werden die in LlamaIndex integrierten Werkzeuge für die Kombination von QQL-und Semantischer Suche zu einer einheitlichen Abfrage-Oberfläche beschrieben.