RAG:检索增强生成
Der RAG
RAG: Augmented Generation Retrievals
Sie versuchen, einen komplizierten Fall zu lösen:
Die Rolle des Detektivs besteht darin, Hinweise, Beweise und historische Aufzeichnungen im Zusammenhang mit dem Fall zu sammeln. Nachdem der Detective die Informationen gesammelt hatte, fasste der Reporter die Fakten zu einer faszinierenden Geschichte zusammen und stellte eine schlüssige Geschichte vor.
Das Problem mit llm
- Halluzination: falsche Informationen ohne Antwort.
- Llm verwendet veraltete Informationen, und nach Ablauf der Wissensfrist hat sie keinen Zugang zu den neuesten und zuverlässigen Informationen.
- Darüber hinaus bezieht sich die Antwort des Unternehmens nicht auf ihre Quelle, was bedeutet, dass ihr Anspruch nicht als zutreffend oder voll vertrauenswürdig eingestuft werden kann. Dies unterstreicht die Bedeutung einer unabhängigen Überprüfung und Bewertung bei der Verwendung von durch künstlicher Intelligenz erzeugter Informationen.
您可以将大型语言模型看作是一个过于热情的新员工,他拒绝随时了解时事,但总是会绝对自信地回答每一个问题。
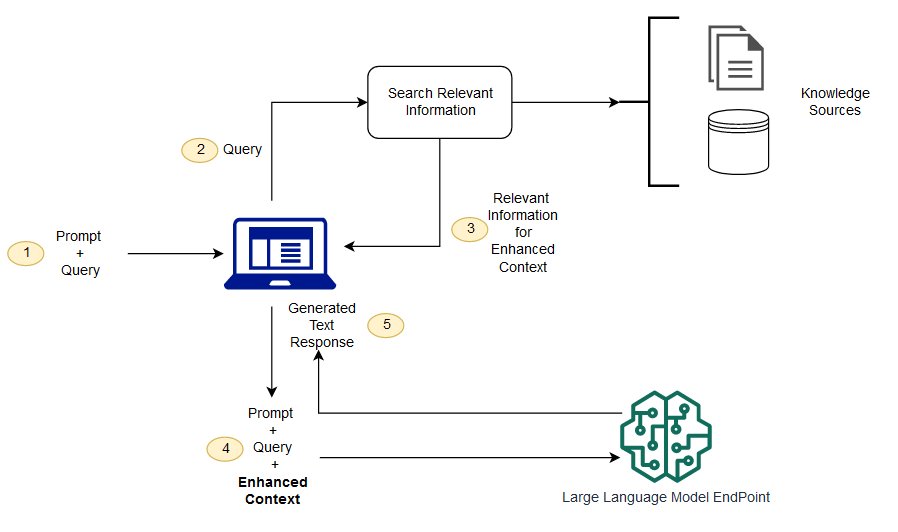
Die RAG ist ein Weg, um einige dieser Herausforderungen zu lösen. Es leitet den LMB um, um relevante Informationen aus autoritativen, vorbestimmten Quellen des Wissens abzurufen. Organisationen haben mehr Kontrolle über die generierte Textausgabe, und Benutzer können mehr darüber erfahren, wie llm Antworten erzeugt.
Der Prozess des
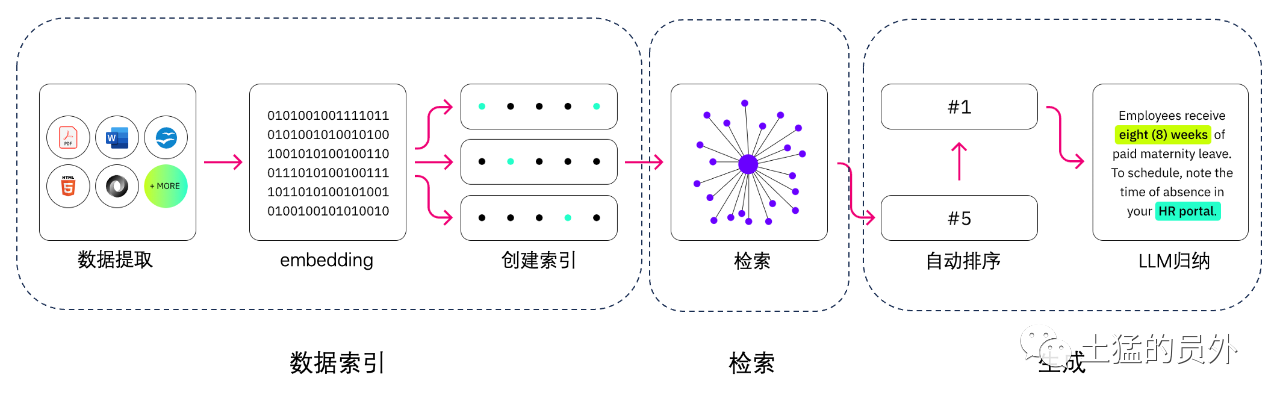
(ich verstehe nicht) was ist der Unterschied zwischen der Generation von Retrievals und der Semantik?
Die Semantische Suche kann die RAG-Ergebnisse von Unternehmen verbessern, die ihren LLM-Anwendungen eine große Anzahl externer Wissensquellen hinzufügen möchten. Moderne Unternehmen speichern eine große Menge an Informationen in einer Vielzahl von Systemen, z. B. in Handbüchern, häufig gestellten Fragen, Forschungsberichten, Kundendienstleitern und Personaldokumenten-Projektarchiven. Das kontextuelle Retrieval ist in der Größe schwierig und beeinträchtigt daher die Qualität der erstellten Ausgabe.
Semantische Suchtechnologie: sie können große Datenbanken mit verschiedenen Informationen scannen und Daten genauer abrufen Sie können beispielsweise Fragen wie * "wie viel haben Sie im vergangenen Jahr für mechanische Wartung ausgegeben?" beantwortet? Fragen wie *, indem Sie die Frage dem entsprechenden Dokument abbilden und einen bestimmten Text anstelle der Suche zurückgeben. Entwickler können dann diese Antwort verwenden, um mehr Kontext für llm bereitzustellen.
Traditionelle oder Schlüsselwortsuchlösungen in der RAG liefern begrenzte Ergebnisse für wissensintensive Aufgaben. Entwickler müssen sich auch mit der Einbettung von Wort, der Fragmentierung von Dokumenten und anderen komplexen Problemen befassen, wenn Sie die Daten Im Gegensatz dazu kann die Semantik-Suchtechnologie alle Arbeiten, auf die die Wissensbasis vorbereitet ist, erledigen. Entwickler müssen dies also nicht tun. Sie generieren auch semantisch bezogene Absätze und Markup-Wörter, sortiert nach Relevanz, um die Qualität der APG-Nutzlast zu maximieren.
Drei Kernkomponenten der RAG
Das Retrieval-Generationsmodell besteht hauptsächlich aus drei Kernkomponenten:
- Retriever: verantwortlich für das Abrufen relevanter Informationen aus externen Wissensquellen.
- Sorter (ranker): bewertet und priorisiert die Suche.
- Generator: verwenden Sie das Abrufen und Sortieren von Ergebnissen in Kombination mit der Benutzereingabe, um die endgültige Antwort oder den Inhalt zu erzeugen.
Karte des Gehirns der Lumpen
Dieses Bild ist sehr detailliert!
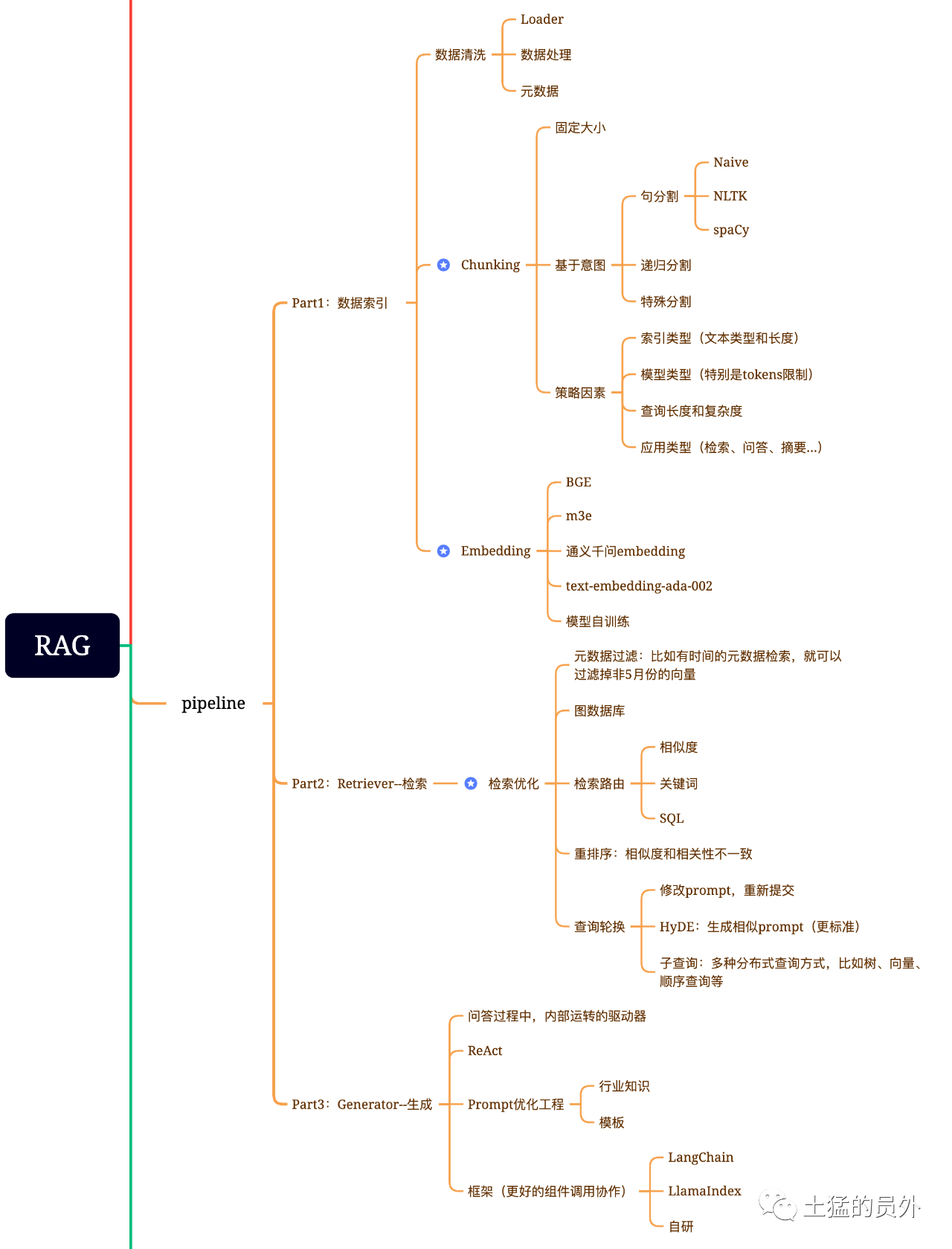
Datenindexierung
-* * Datenextraktion * *
Datenreinigung: einschließlich Datenloader, Extraktion von Text, Text, Datenbanken, API-Codes usw. -Datenverarbeitung: einschließlich der Formatverarbeitung, Beseitigung nicht identifizierbarer Inhalte, Komprimierung und Formatierung -Extraktion von Metadaten: Dateiname, Zeit, Kapiteltitel, Bild-alt und andere Informationen sind sehr wichtig.
Tools für die Datenextraktion
-Unstrukturiertio (verwendet) LlamaParse (verwendet) -Google Dokument KI -aws Text -dosf2image + pyteseract
Suchen
Die Retrieval-Optimierung ist im Allgemeinen in die folgenden fünf Teile unterteilt:
-* * Metadaten-Filterung * : wenn der Index in viele Teile unterteilt wird, wird die Retrievalwirksamkeit ein Problem sein. Wenn die Metadaten zuerst gefiltert werden können, wird die Effizienz und Relevanz erheblich verbessert. Zum Beispiel fragen wir: "helfen Sie mir, alle Verträge in der Abteilung XX im Mai dieses Jahres zu klären, die den Kauf von XX-Geräten umfassen?" . Zu diesem Zeitpunkt, wenn Metadaten vorhanden sind, können wir nach den relevanten Daten von " * XX-Abteilung + Mai 2023 * *" suchen, und die Anzahl der Abfragen kann 1 / 10.000 der Gesamtsituation auf einmal betragen.
Insbesondere bei einigen Multi-Hopp-Problemen wird die Verwendung des Graph-Datenindex das Retrieval relevanter machen.
-* * Retrieval-Technologie * *: oben erwähnt sind einige Vorverarbeitungsmethoden, und die wichtigsten Retrieval-Methoden sind wie folgt:
-
- 相似度检索:前面我已经写过那篇文章《大模型应用中大部分人真正需要去关心的核心——Embedding》中有提到六种相似度算法,包括欧氏距离、曼哈顿距离、余弦等,后面我还会再专门写一篇这方面的文章,可以关注我,yeah; -* * Schlüsselwortsuche * : dies ist eine sehr traditionelle Suchmethode, aber manchmal ist sie auch sehr wichtig. Die von uns gerade erwähnte Metadaten-Filterung ist eine solche, und eine andere besteht darin, zuerst Chunks zusammenzufassen, und dann den möglichen relevanten Chunks durch Schlüsselwort-Retrival zu finden, um die Retriev Es wird gesagt, dass Claude das gleiche getan hat. - * QL-Suche * *: dies ist traditioneller, aber für einige lokalisierte Unternehmensanwendungen ist die Sqq-Abfrage ein wesentlicher Schritt. Beispielsweise müssen die von mir erwähnten Vertriebsdaten zuerst von der QL-Suche -andere: es gibt immer noch viele Retrieval-Techniken, lassen Sie uns später darüber sprechen.
-* * Anzahl * *: in vielen Fällen sind unsere Retrieval-Ergebnisse nicht ideal, da das System eine große Anzahl von Fragmenten enthält und die Abmessungen, die wir abrufen, nicht unbedingt ideal sind und die Ergebnisse einer Suche möglicherweise nicht so ideal von Bedeutung sind. Zu diesem Zeitpunkt müssen wir einige Strategien haben, um die Retrieval-Ergebnisse neu zu sortieren, wie zum Beispiel den Einsatz von planB, um die Kombination aus Relevanz, Matching und anderen Faktoren anzupassen, um ein Ranking zu erhalten, das unserem Geschäftsszenario entspricht. Denn nach diesem Schritt werden wir das Ergebnis zur endgültigen Verarbeitung an die llm senden, daher ist das Ergebnis dieses Teils sehr wichtig. Es wird auch einen internen Richter geben, um die Korrelation zu überprüfen und die Neuordnung auszulösen.
-* * Abfragedrehung * *: dies ist eine Abfrage- und Retrievalmethode, und es gibt normalerweise mehrere Möglichkeiten:
-* * Sub-abfrage: * * Sie können verschiedene Abfragestrategien in verschiedenen Szenarien verwenden. Zum Beispiel können Sie die Abfrage-Strategie, die von Frameworks wie LlamaIndex, Baumabfrage (von Blattknoten, Schritt-Abfrage, Zusammenführen), Vektorabfragen oder die primitivsten sequentiellen Abfrage-Stück usw. verwendet werden. * *; * *
-* * Hyde: * * auf diese Weise können Sie Aufträge kopieren, um ähnliche oder mehr Standard-Prompt-Vorlagen zu erzeugen * *
Neuplatzierung
Die meisten Vektordatenbanken opfern eine gewisse Genauigkeit für die Berechnungseffektivität. Dies macht das Retrieval-Ergebnis zufällig, und das ursprünglich zurückgegebene Top-K ist nicht unbedingt das relevanteste.
使用BAAI/bge-reranker-base、BAAI/bge-reranker-large等开源模型来完成Re-Rank操作。
Und NetEase 's bce-reranker-basis unterstützt China, Großbritannien, Japan und Südkorea.
Rückruf / gemischtes Abrufen
Zwei-Wege-Abfrage:
-Semantische Retrieval (Vektorsuche) / * * der Rückruf der Vektordatenbank * * -Schlüsselwortsuche (Schlüsselwortsuche) / Rückruf der Schlüsselwortsuche
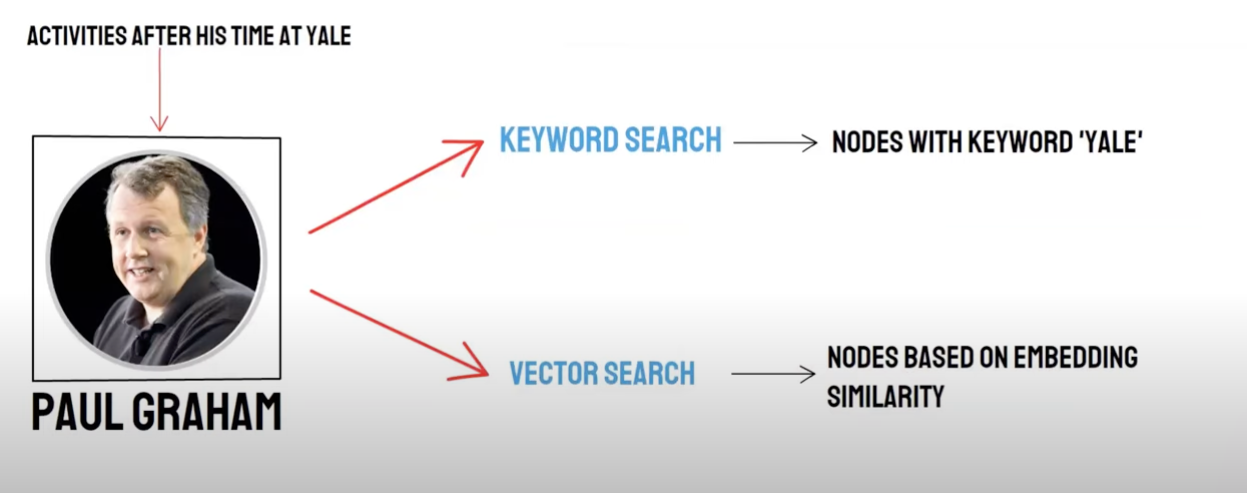
Der Rückruf von Vektordatenbanken und der Schlüsselworträtsel zum Retrieval haben seine eigenen Vor- und Nachteile. Die Kombination der Rückrufeergebnisse kann daher die Genauigkeit und Effizienz des Der Algorithmus für gegenseitige Sortenfusionen (RRK) (Reverential Ranking Fusion) berechnet die Gesamtpunktzahl nach der Fusion durch gewichtige Summierung der Rangfolge eines jeden Dokumenten mit verschiedenen Rückruf-Methoden.
Wenn Sie den Rückruf von Schlüsselworten verwenden, DH * * Schlüsselwörter * * auswählen * * Schlüsselwörter kombinieren * *, pai verwendet standardmäßig einen RRF-Algorithmus, um die Rückrufeergebnisse der Vektordatenbank und des Schlüsselwortrückrufs zu multiplexen.
Generieren
Das Frameworks hat sowohl Langchain als auch LlamaIndex.
Das Schema der Zähl- und Erntetechnologie
Rahmen
Die Schwierigkeit ist: was ist Text-to-ql?
Text-Aufteilung:
Textspaltung: das Dokument wird in kleinere Blöcke unterteilt, um die nachfolgende Texteinbettung und dann das nachfolgende Abrufen von Dokumenten zu
Im Idealfall: ordnet ordnet an, dass Semantik verwandte Texte zusammengestellt werden.
-
- Spaltmethode * *
-entsprechend der Regel (am einfachsten), um das Dokument nach einem Satz zu teilen. Das Dokument ist auf der Grundlage der gängigen chinesischen und englischen Abschlusssymbole wie Einzelzeichenbreaker, chinesischer und englischer Ellipsen, doppelter Anführungszeichen und Anführungszeichen unterteilt. Auf der Grundlage der Semantik: (1) Abl. Zunächst wird das Dokument auf der Grundlage von Regeln in Dokumentblöcke auf Sendungsebene unterteilt. 2. Integrieren Sie dann die auf der Semantik basierenden Dokumentblöcke mit dem Modell und rufen Sie schließlich die Semantik-basierten Dokumentblöcke
-
- Semantik-basiertes Textsplittermodell * *
Das vom Ali-Dama-Institut entwickelte Modell seq-model * * basiert auf dem Schiebefenster "Bert +", das die Semantik durch die Vorhersage bestimmt, ob der geteilte Satz zur Absatzgrenze gehört.
Textvektorisierung: wählen Sie Einbettungsmodell
Das BBA-Modell von Zhiyuan (bge-base-zh-Modell) oder eine Auswahl aus dem Beispiel von MTEB.
Vektorspeicherung
-FAiss: für den persönlichen Gebrauch
-Episode: Produktionsniveau
Mit Vektor können Sie relevante Wissenspunkte basierend auf Fragen abrufen.
Top _ k
Faiss: führen Sie eine erweiterte Suche in der Nähe der Ergebnisse, um ähnliche Dokumente zu erhalten,
Milvus: Topk Retrieval + bge-base-zH + Aggregationsmodell für ähnliche Absätze
Idee: Analyse der Idee des erweiterten Retrievals basierend auf dem Topk Retrievals wird festgestellt, dass das große Modell den Effekt der Antwort hauptsächlich durch die Erweiterung von Semantiksegmenten veranlasst, so viele nützliche Informationen wie möglich zu erhalten.
Denkrichtung:
- Zunächst wird das Dokument auf der Grundlage von Regeln in Dokumentblöcke auf Sendungsebene unterteilt.
- Integrieren Sie dann die auf der Semantik basierenden Dokumentblöcke mit dem Modell und rufen Sie schließlich die Semantik-basierten Dokumentblöcke
- Drittens wird für die Dokumente das Text-Einbettungsmodell sequenziell verwendet, und die Dokumente werden erneut mit der semantischen Ähnlichkeit aggregiert, die äquivalent ist, die ursprünglichen Dokumente auf Sentence-Ebene zweimal mit verschiedenen Methoden zu
Schnelligkeit erstellen
你现在是一个智能助手了,现在需要你根据已知内容回答问题
已知内容如下:
"{context}"
通过对已知内容进行总结并且列举的方式来回答问题:"{question}",在答案中不能出现问题内容,并且不允许编造内容,并且使用简体中文回答。
如果该问题和已知内容不相关,请回答 "根据已知信息无法回答该问题" 或 "没有提供足够的相关信息"。
Antwort generieren: wählen Sie llm
Testplan
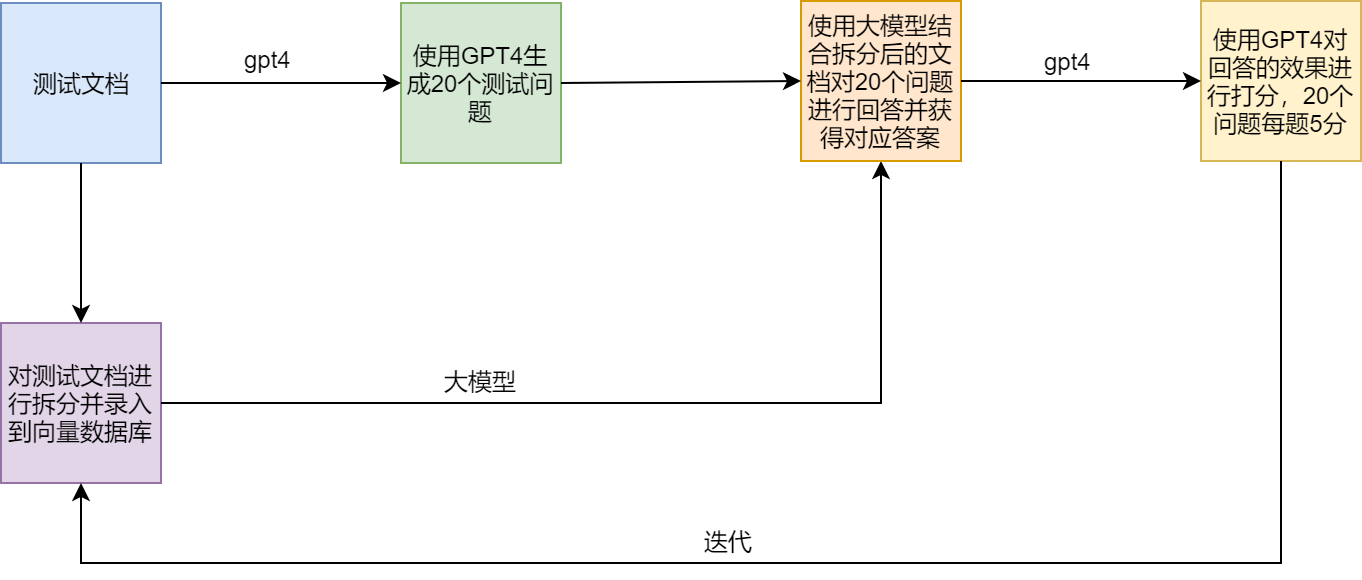
Grievige Punkte und Lösungen von RAG

Beispiel
LamaIndex官方提供了一个范例(SEC Insights),用来展示高级查询技术