Langchaîne
Lire le plan de documentation officielle
| 分类1 | 分类2 | 进展 |
|---|---|---|
| LCEL | Interface | |
| Streaming | ||
| How to | Route between multiple runnables✅ Cancelling requests✅ Use RunnableMaps✅ Add message history (memory) | |
| Cookbook | ✅Prompt + LLM ✅Multiple chains ✅Retrieval augmented generation (RAG) ✅Querying a SQL DB Adding memory ✅Using tools Agents | |
| Model I/O | Quickstart | |
| Concepts | ✅ | |
| Prompts | Quick Start Example selectors Few Shot Prompt Templates Partial prompt templates Composition | |
| LLMs | Quick Start Streaming Caching Custom chat models Tracking token usage Cancelling requests Dealing with API Errors Dealing with rate limits OpenAI Function calling Subscribing to events Adding a timeout | |
| Chat Models | ||
| Output Parsers | ✅ | |
| Retrieval | 首页/概念 | |
| Document loaders | ||
| Text Splitters | ||
| Retrievers | ||
| Text embedding models | ||
| Vector stores | ||
| Indexing | ||
| Experimental | ||
| Chains | ✅ | |
| Agents | ||
| More | ||
| Guides | ||
| User cases | SQL | |
| Chatbots | ||
| Q&A with RAG | ||
| Tool use | ||
| Interacting with APIs | ||
| Tabular Question Answering | ||
| Summarization | ||
| Agent Simulations | ||
| Autonomous Agents | ||
| Code Understanding | ||
| Extraction |
L'écologie LangChain
Avantages : Prend en charge JavaScript, ce qui est beaucoup plus fort que LllamaIndex (Bien que llama prenne en charge ts, la documentation et l'API sont nettement inférieures à la version Python)
écologique :

Concepts
LLM et le modèle Chat
Modèles : Il y a deux types de LLMs et de modèles de chat.
import { OpenAI, ChatOpenAI } from "@langchain/openai";
const llm = new OpenAI({
modelName: "gpt-3.5-turbo-instruct",
});
const chatModel = new ChatOpenAI({
modelName: "gpt-3.5-turbo",
});
Le modèle de Anthropic est le mieux adapté à XML, tandis que le modèle d'OpenAI est le mieux adapté à JSON.
Version du Typescript
Installation
npm install langchain @langchain/core @langchain/community @langchain/openai langsmith
LangChain所有第三方的库:链接
Quick Start
import { ChatOpenAI } from "@langchain/openai";
async function main() {
const chatModel = new ChatOpenAI({});
let str = await chatModel.invoke("what is LangSmith?");
console.log(str);
}
main();
Configuration
OpenAI可配置的内容:见官网
Nom du modèle / température / clé API / URL de base
import { OpenAI } from "@langchain/openai";
const model = new OpenAI({
modelName: "gpt-3.5-turbo",
temperature: 0.9,
openAIApiKey: "YOUR-API-KEY",
configuration: {
baseURL: "https://your_custom_url.com",
},
});
Modèle JSON
const jsonModeModel = new ChatOpenAI({
modelName: "gpt-4-1106-preview",
maxTokens: 128,
}).bind({
response_format: {
type: "json_object",
},
});
见定义
Appel de fonction / outils
Première : Tools
Utiliser les dernières interfaces d'outils
const llm = new ChatOpenAI();
const llmWithTools = llm.bind({
tools: [tool],
tool_choice: tool,
});
const prompt = ChatPromptTemplate.fromMessages([
["system", "You are the funniest comedian, tell the user a joke about their topic."],
["human", "Topic: {topic}"]
])
const chain = prompt.pipe(llmWithTools);
const result = await chain.invoke({ topic: "Large Language Models" });
Spécifier parser
import { JsonOutputToolsParser } from "langchain/output_parsers";
const outputParser = new JsonOutputToolsParser();
2ème : Appel de fonction
Il y a deux façons :
-
- Fonction entrante lors de l'appel * *
const result = await model.invoke([new HumanMessage("What a beautiful day!")], {
functions: [extractionFunctionSchema],
function_call: { name: "extractor" },
});
-
- Lier la fonction au modèle * *
Le même modèle peut être réutilisé en permanence
const model = new ChatOpenAI({ modelName: "gpt-4" }).bind({
functions: [extractionFunctionSchema],
function_call: { name: "extractor" },
});
Définir l'API
Il y a deux approches
const extractionFunctionSchema = {
name: "extractor",
description: "Extracts fields from the input.",
parameters: {
type: "object",
properties: {
tone: {
type: "string",
enum: ["positive", "negative"],
description: "The overall tone of the input",
},
word_count: {
type: "number",
description: "The number of words in the input",
},
chat_response: {
type: "string",
description: "A response to the human's input",
},
},
required: ["tone", "word_count", "chat_response"],
},
};
-
- Utilisation de Zod * *
import { ChatOpenAI } from "@langchain/openai";
import { z } from "zod";
import { zodToJsonSchema } from "zod-to-json-schema";
import { HumanMessage } from "@langchain/core/messages";
const extractionFunctionSchema = {
name: "extractor",
description: "Extracts fields from the input.",
parameters: zodToJsonSchema(
z.object({
tone: z
.enum(["positive", "negative"])
.describe("The overall tone of the input"),
entity: z.string().describe("The entity mentioned in the input"),
word_count: z.number().describe("The number of words in the input"),
chat_response: z.string().describe("A response to the human's input"),
final_punctuation: z
.optional(z.string())
.describe("The final punctuation mark in the input, if any."),
})
),
};
Modèle I / O
Loader
Retriever (important)
en deux catégories
- Propriété
- 第三方集成
| Retriever | 说明 |
|---|---|
| Knowledge Bases for Amazon Bedrock | |
| Chaindesk Retriever | |
| ChatGPT Plugin Retriever | |
| Dria Retriever | |
| Exa Search | |
| HyDE Retriever | |
| Amazon Kendra Retriever | |
| Metal Retriever | |
| Supabase Hybrid Search | |
| Tavily Search API | |
| Time-Weighted Retriever | |
| Vector Store | |
| Vespa Retriever | |
| Zep Retriever |
Étiquette : ScoreThreshold
Le ScoreThreshold est un pourcentage.
- 1.0 est un match complet.
- 0,95 peut être similaire.
import { MemoryVectorStore } from "langchain/vectorstores/memory";
import { OpenAIEmbeddings } from "@langchain/openai";
import { ScoreThresholdRetriever } from "langchain/retrievers/score_threshold";
async function main() {
const vectorStore = await MemoryVectorStore.fromTexts(
[
"Buildings are made out of brick",
"Buildings are made out of wood",
"Buildings are made out of stone",
"Buildings are made out of atoms",
"Buildings are made out of building materials",
"Cars are made out of metal",
"Cars are made out of plastic",
],
[{ id: 1 }, { id: 2 }, { id: 3 }, { id: 4 }, { id: 5 }],
new OpenAIEmbeddings()
);
const retriever = ScoreThresholdRetriever.fromVectorStore(vectorStore, {
minSimilarityScore: 0.95, // Finds results with at least this similarity score
maxK: 100, // The maximum K value to use. Use it based to your chunk size to make sure you don't run out of tokens
kIncrement: 2, // How much to increase K by each time. It'll fetch N results, then N + kIncrement, then N + kIncrement * 2, etc.
});
const result = await retriever.getRelevantDocuments(
"building is made out of atom"
);
console.log(result);
};
main();
// [
// Document {
// pageContent: 'Buildings are made out of atoms',
// metadata: { id: 4 }
// }
// ]
-
- Self-Querying (excellent pour les requêtes de données structurées) * *
Supabasse
Parser
| 解析器 | 说明 | |
|---|---|---|
| 常见 | String output parser | |
| 格式化 | Structured output parser | 方便自定义 |
| OpenAI Tools | 常用 | |
| 标准格式 | JSON Output Functions Parser | 常用 |
| HTTP Response Output Parser | ||
| XML output parser | ||
| 列表 | List parser | 常用 |
| Custom list parser | 常用 | |
| 其它 | Datetime parser | 有用 |
| Auto-fixing parser |
Chaîne multiple
Série
De deux manières
- «. pip »
RunnableSequence.from([])
Utilisation du. pip
const prompt = ChatPromptTemplate.fromMessages([
["human", "Tell me a short joke about {topic}"],
]);
const model = new ChatOpenAI({});
const outputParser = new StringOutputParser();
const chain = prompt.pipe(model).pipe(outputParser);
const response = await chain.invoke({
topic: "ice cream",
});
Utilisation de RunnableSequence.from
const model = new ChatOpenAI({});
const promptTemplate = PromptTemplate.fromTemplate(
"Tell me a joke about {topic}"
);
const chain = RunnableSequence.from([
promptTemplate,
model
]);
const result = await chain.invoke({ topic: "bears" });
Batch et Parallel
Le LCEL lui-même soutient
const chain = promptTemplate.pipe(model);
await chain.batch([{ topic: "bears" }, { topic: "cats" }])
Utilisation de RunnableMap
const model = new ChatAnthropic({});
const jokeChain = PromptTemplate.fromTemplate(
"Tell me a joke about {topic}"
).pipe(model);
const poemChain = PromptTemplate.fromTemplate(
"write a 2-line poem about {topic}"
).pipe(model);
const mapChain = RunnableMap.from({
joke: jokeChain,
poem: poemChain,
});
const result = await mapChain.invoke({ topic: "bear" });
Branche
De deux manières
- RunnableBranch
- Fonction de Custom Factory
Avortement, retry, fallback
N / A
Exemple typique : série
import { PromptTemplate } from "@langchain/core/prompts";
import { RunnableSequence } from "@langchain/core/runnables";
import { StringOutputParser } from "@langchain/core/output_parsers";
import { ChatOpenAI } from "@langchain/openai";
async function main() {
const prompt1 = PromptTemplate.fromTemplate(
`What is the city {person} is from? Only respond with the name of the city.`
);
const prompt2 = PromptTemplate.fromTemplate(
`What country is the city {city} in? Respond in {language}.`
);
const model = new ChatOpenAI({});
const chain1 = prompt1.pipe(model).pipe(new StringOutputParser());
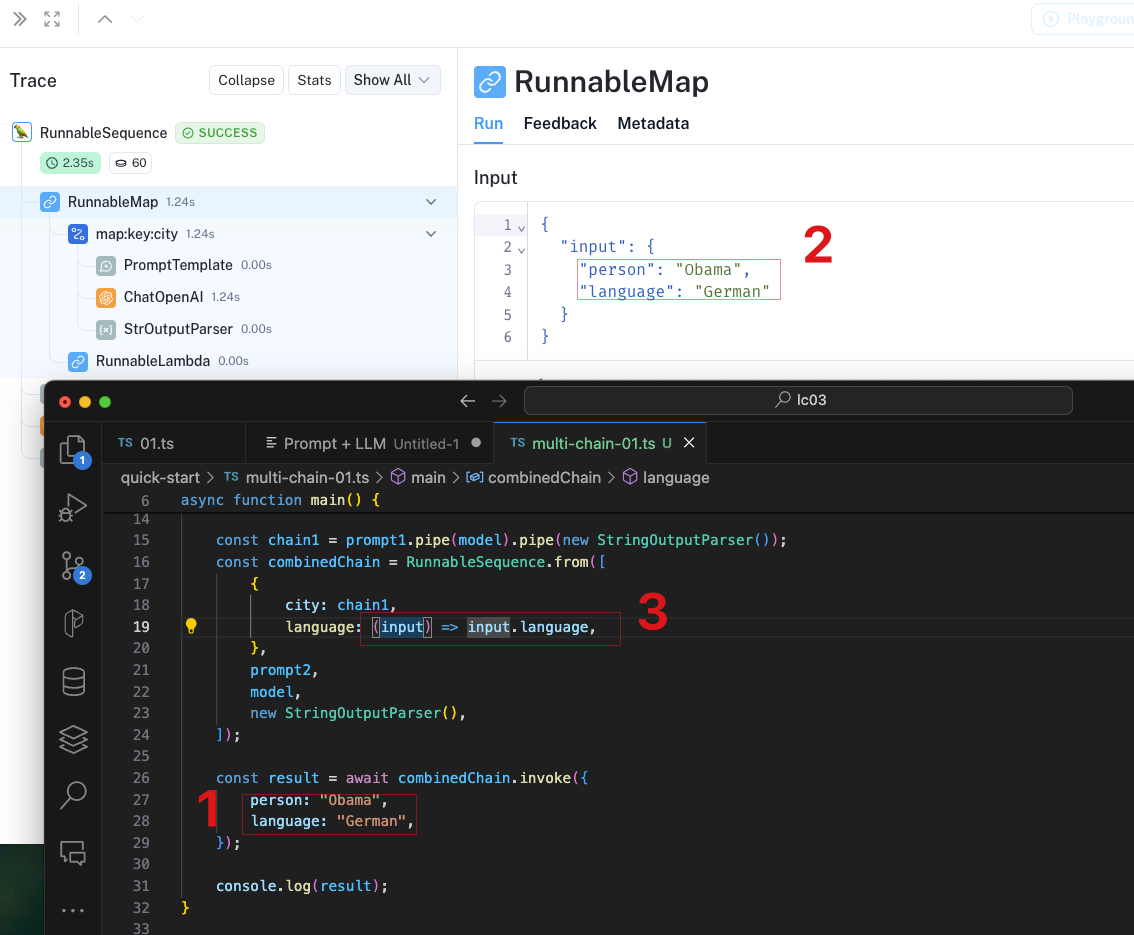
const combinedChain = RunnableSequence.from([
{
city: chain1,
language: (input) => input.language,
},
prompt2,
model,
new StringOutputParser(),
]);
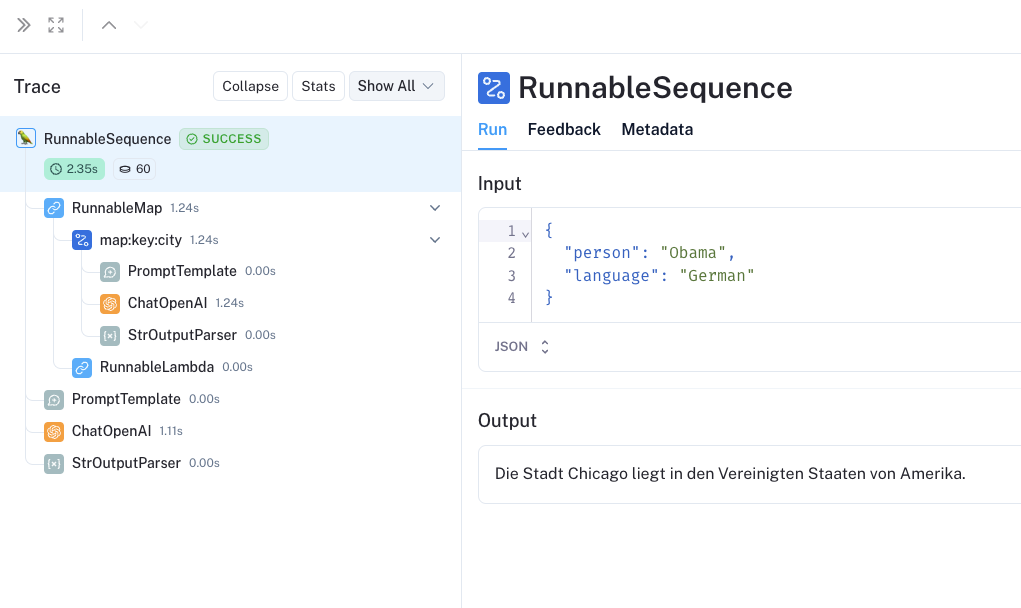
const result = await combinedChain.invoke({
person: "Obama",
language: "German",
});
console.log(result);
}
main();
结果见这里
le RAG
Chargement / Loader / ETL
| 分类 | 项目 | |
|---|---|---|
| 本地资源 | Folders with multiple files ChatGPT files CSV files Docx files EPUB files JSON files JSONLines files Notion markdown export Open AI Whisper Audio PDF files PPTX files Subtitles Text files Unstructured | |
| Web资源 | Cheerio Puppeteer Playwright Apify Dataset AssemblyAI Audio Transcript Azure Blob Storage Container Azure Blob Storage File College Confidential Confluence Couchbase Figma GitBook GitHub Hacker News IMSDB Notion API PDF files Recursive URL Loader S3 File SearchApi Loader SerpAPI Loader Sitemap Loader Sonix Audio Blockchain Data YouTube transcripts |
更通用的ELT工具:unstructured
Splitter
Version de Python
安装LangChain全家桶
pip install langchain langchain-community langchain-core "langserve[all]" langchain-cli langsmith langchain-openai
最新版本号:0.2.6(截止到2024年7月3日)
hub
Il y a un Hub sur LangSmith, similaire à Github.
例如RLM
import { UnstructuredDirectoryLoader } from "langchain/document_loaders/fs/unstructured";
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
import { MemoryVectorStore } from "langchain/vectorstores/memory"
import { OpenAIEmbeddings, ChatOpenAI } from "@langchain/openai";
import { pull } from "langchain/hub";
import { ChatPromptTemplate } from "@langchain/core/prompts";
import { StringOutputParser } from "@langchain/core/output_parsers";
import { createStuffDocumentsChain } from "langchain/chains/combine_documents";
async function main() {
const options = {
apiUrl: "http://localhost:8000/general/v0/general",
};
const loader = new UnstructuredDirectoryLoader(
"sample-docs",
options
);
const docs = await loader.load();
// console.log(docs);
const vectorStore = await MemoryVectorStore.fromDocuments(docs, new OpenAIEmbeddings());
const retriever = vectorStore.asRetriever();
const prompt = await pull<ChatPromptTemplate>("rlm/rag-prompt");
const llm = new ChatOpenAI({ modelName: "gpt-3.5-turbo", temperature: 0 });
const ragChain = await createStuffDocumentsChain({
llm,
prompt,
outputParser: new StringOutputParser(),
})
const retrievedDocs = await retriever.getRelevantDocuments("what is task decomposition")
const r = await ragChain.invoke({
question: "列出名字和联系方式",
context: retrievedDocs,
})
console.log(r);
}
main();