LlamaIndex
Versione Python e typescript
La versione Python della documentazione è più completa, ts è relativamente scarsa?
Introduzione
Crea un ambiente
conda create --name llamaindex python=3.9.19
conda activate llamaindex
-
- Impostare l'ambiente CONDA in VSCode * *
Python: Select Interpreter
Libreria di installazione
pip install llama-index pypdf sentence_transformers
Configura OpenAI
vim ~/.bashrc
Aggiungere il variabl dell'ambiente
export OPENAI_API_KEY="sk-xxxx"
Verifica
echo $OPENAI_API_KEY
-
- Accessibilità * *
Configura: goproxy sulla riga di comando
Avvio veloce
import os.path
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
import logging
import sys
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
# check if storage already exists
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):
# load the documents and create the index
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# store it for later
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
# load the existing index
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
# either way we can now query the index
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
-
- Metodo di completamento utilizzato * *
/chat/completions
-
- Parametri di query * *
{
"messages": [
{
"role": "system",
"content": "You are an expert Q&A system that is trusted around the world.\nAlways answer the query using the provided context information, and not prior knowledge.\nSome rules to follow:\n1. Never directly reference the given context in your answer.\n2. Avoid statements like \"Based on the context, ...\" or \"The context information ...\" or anything along those lines."
},
{
"role": "user",
"content": "xxx"
}
],
"model": "gpt-3.5-turbo",
"stream": false,
"temperature": 0.1
}
-
- Prompt di sistema * *
You are an expert Q&A system that is trusted around the world.
Always answer the query using the provided context information, and not prior knowledge.
Some rules to follow:
1. Never directly reference the given context in your answer.
2. Avoid statements like "Based on the context, ..." or "The context information ..." or anything along those lines.
Lei è un fidato sistema di domande e risposte di esperti in tutto il mondo. Quando si risponde alle domande, utilizzare sempre le informazioni di base fornite, piuttosto che le conoscenze precedenti. Alcune regole da seguire:
- Non fare mai riferimento direttamente alle informazioni di base contenute nella risposta.
- Evitare di utilizzare "sulla base di informazioni di base", O "informazioni di base indicano che"... O qualcosa del genere.
-
- Prompt utente * *
Context information is below.
---------------------
file_path: data/paul_graham_essay.txt
xxx
---------------------
Given the context information and not prior knowledge, answer the query.
Query: What did the author do growing up?
Answer:
Scenario di applicazione
| 应用场 | 说明 |
|---|---|
| Q&A | 最重要 |
| Chatbots | |
| Agents | 高级 |
| Structured Data Extraction | 有用,整理聊天记录等 |
| Multi-modal |
Principi di base
Processo di base
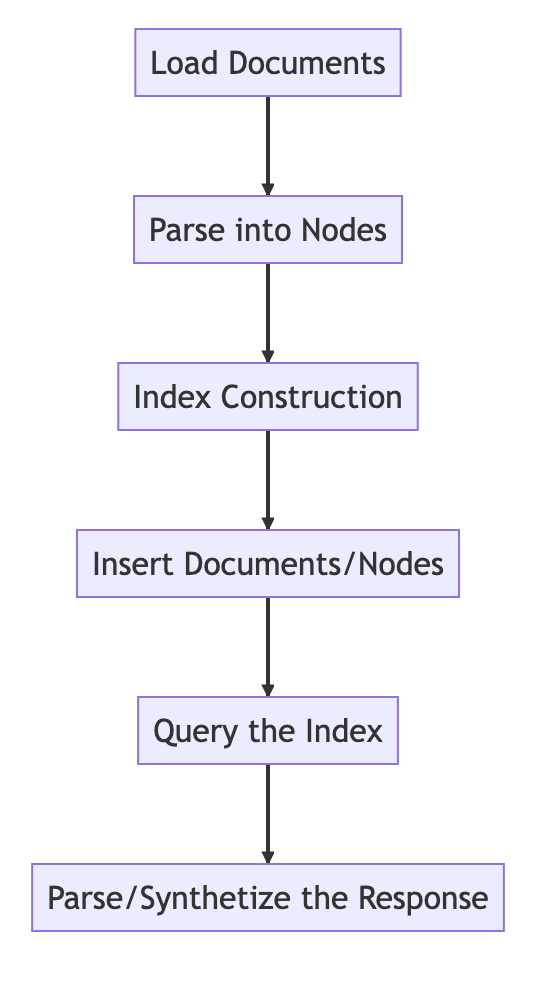
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# Load in data as Document objects
documents = SimpleDirectoryReader('data').load_data()
# 切片,转成Node
# Parse Document objects into Node objects to represent chunks of data
index = VectorStoreIndex.from_documents(documents)
# Index Construction:创建索引
# Build an index over the Documents or Nodes
query_engine = index.as_query_engine()
# The response is a Response object containing the text response and source Nodes
summary = query_engine.query("What is the text about")
print("What is the data about:")
print(summary)
Chunking e Node
Dati di origine - > Documenti - - > Nodi
Documenti: contiene informazioni sul corpo e sulle meta
ID del documento
Il documento è in realtà una sottoclasse di Nodo
È strano che un file sarà tagliato in molti documenti.
TextNode: Utilizzare NodeParser per tagliare il documento in Nodo multiplo
Includere l'ID del documento
C'era una connessione tra Nodo e Nodo
- NodeParser riceve un elenco di oggetti di documento
- Utilizzando la segmentazione della frase di Spacy, il testo di ogni documento è suddiviso in frasi.
- Ogni frase è avvolta in un oggetto TextNode che rappresenta un nodo
- TextNode contiene il testo delle frasi, così come i metadati, come l'ID del documento, la posizione nel documento, ecc.
- Restituisce un elenco di oggetti TextNode.
Salvare documento e indice
Due modi
- Salva su disco locale
- Storage to Vector database
-
- Salva su disco locale * *
import os.path
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
import sys
# check if storage already exists
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):
# 保存数据: Load the documents and create the index
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# store it for later
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
# 从磁盘加载回数据: load the existing index
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
Costruisci un indice
Crea un embedding per ogni nodo
Crea un indice in VectorStroreIndex
- Per VectorStoreIndex, il testo che incorpora sul nodo viene memorizzato nell'indice Faiss, e la ricerca di somiglianza può essere fatta rapidamente sul nodo.
- L'indice memorizza anche i metadati su ogni nodo, come l'ID del documento, la posizione, ecc.
- Un nodo può recuperare il contenuto di un documento o di un documento specifico.
Indice di query
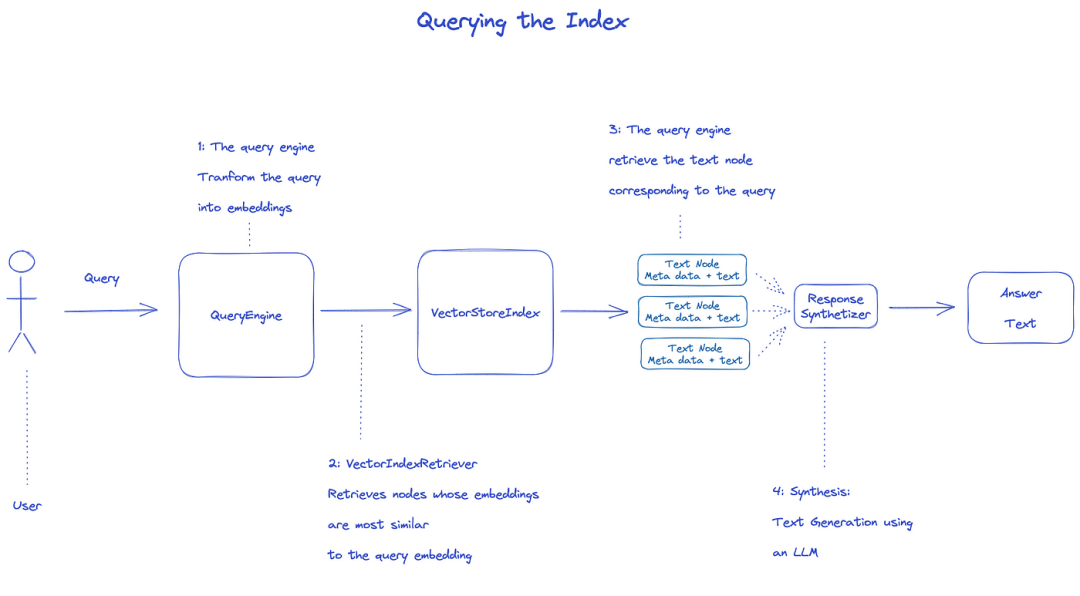
Per interrogare l'indice, verrà utilizzato QueryEngine.
- Retriever ottiene i nodi rilevanti dall'indice della query. Per esempio, VectorIndexRetriever recupera il nodo la cui incorporazione è più simile alla query che incorpora
- L'elenco recuperato dei nodi viene passato a ResponseSynthesizer per generare l'output finale
- Per impostazione predefinita, ResponseSynchesizer elabora ogni nodo in sequenza, e ogni nodo chiama API LLM una volta
- Query di input LLM e testo del nodo per ottenere l'output finale
- Le risposte di ciascuno di questi nodi sono aggregate nella stringa di output finale.
from llama_index import (
VectorStoreIndex,
get_response_synthesizer,
)
from llama_index.retrievers import VectorIndexRetriever
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.postprocessor import SimilarityPostprocessor
from llama_index import StorageContext, load_index_from_storage
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir="storage")
# load index
index = load_index_from_storage(storage_context)
# configure retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=10,
)
# configure response synthesizer
response_synthesizer = get_response_synthesizer()
# assemble query engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
node_postprocessors=[SimilarityPostprocessor(similarity_cutoff=0.7)],
)
# query
response = query_engine.query("What did the author do growing up?")
print(response)
Documento ufficiale: comprensione
-
- Tre processi di trattamento dei dati * *
Condotte di pulizia dei dati / funzionalità ingegneristiche nel mondo ML, o condotte ETL nella tradizionale impostazione dei dati.
Questo gasdotto di ingestione è tipicamente costituito da tre fasi principali:
- Carica i dati
- Trasforma i dati
- Indice e memorizza i dati
Dati di carico (ingestione)
-
- Obiettivo: * * Formare vari tipi di dati in oggetti documentali.
-
- Input: * * Vari tipi di dati
-
- Uscita: * Oggetto
-
- 3 modi * *
- Utilizzare la classe SimpleDirectoryReaderer: la più conveniente
- LlamaHubŸ: vari strumenti che sono stati scritti
- Creazione diretta di documenti
- Classe SimpleDirectoryReaderer * *
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
Supporto Markdown, PDF, documenti Word (.docx), ponti PowerPoint, immagini (.jpg, .png), audio e video
-
- Llamahub * *
- Notion (
NotionPageReader) - Google Docs (
GoogleDocsReader) - Slack (
SlackReader) - Discord (
DiscordReader) - Apify Actors (
ApifyActor). Can crawl the web, scrape webpages, extract text content, download files including.pdf,.jpg,.png,.docx, etc.这个可以爬虫
-
- Crea documento * * Direttamente
from llama_index.schema import Document
doc = Document(text="text")
Trasforma i dati (trasformazioni)
-
- Motivo: * * Recupero conveniente e uso efficiente di LLM
-
- Operazioni specifiche: * *
- Frammento di documenti (chunking)
- Estrarre metadati (estrazione di metadati)
- Embedding
-
- Ingresso: * * NodeŸ
-
- Uscita: * * NodeŸ
API incapsulate
Utilizzare il metodo VectorStoreIndexŸFrom _ documentsŸ()
from llama_index import VectorStoreIndex
vector_index = VectorStoreIndex.from_documents(documents)
vector_index.as_query_engine()
-
- Come personalizzare i parametri * *
Idea: Utilizzare ServiceContextŸper personalizzare
text_splitter = SentenceSplitter(chunk_size=512, chunk_overlap=10)
service_context = ServiceContext.from_defaults(text_splitter=text_splitter)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
API atomiche
Modalità di utilizzo standard
from llama_index import Document
from llama_index.embeddings import OpenAIEmbedding
from llama_index.text_splitter import SentenceSplitter
from llama_index.extractors import TitleExtractor
from llama_index.ingestion import IngestionPipeline, IngestionCache
# 加载数据源
documents = SimpleDirectoryReader("./data").load_data()
# 创建转换数据的工作流
# create the pipeline with transformations
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=25, chunk_overlap=0), # 分片
TitleExtractor(), # 提取Meta信息
OpenAIEmbedding(), # Embedding
]
)
# 执行流程,生成节点
# run the pipeline
nodes = pipeline.run(documents=documents)
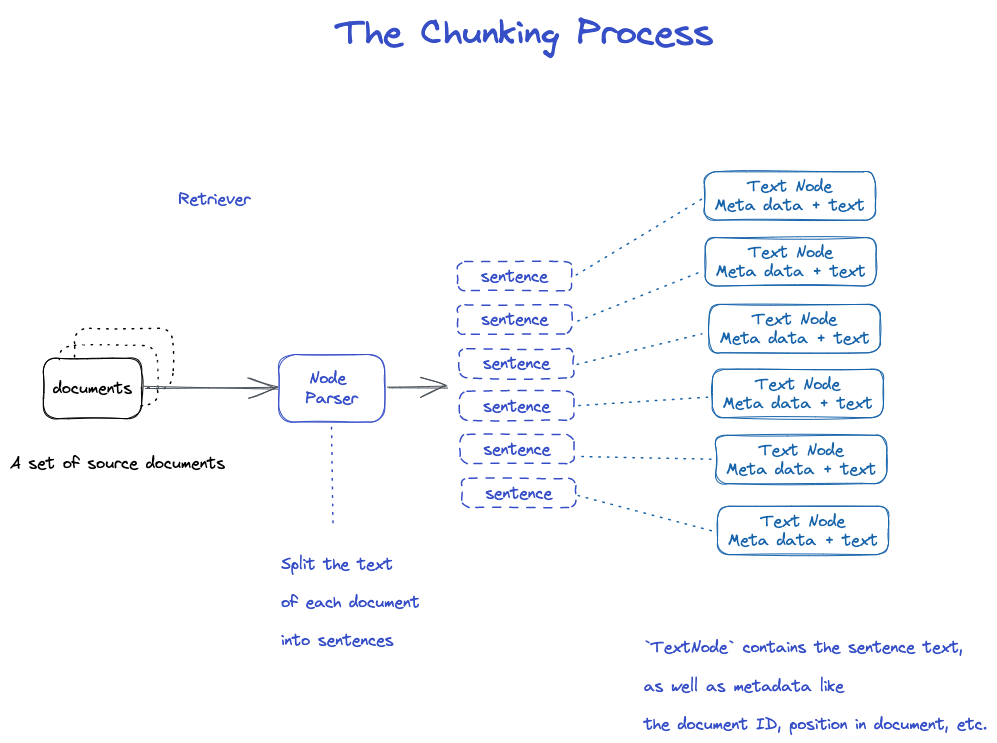
Fetta
Ci sono molte strategie, come specificato nel modulo Node Parser.
Aggiungere metadati
È possibile personalizzare documento e Nodo per aggiungere metadati.
Crea direttamente un oggetto Nodo
from llama_index.schema import TextNode
node1 = TextNode(text="<text_chunk>", id_="<node_id>")
node2 = TextNode(text="<text_chunk>", id_="<node_id>")
index = VectorStoreIndex([node1, node2])
Indice
-
- Classificazione degli indici * *
- Vector Stores
- Document Stores
- Index Stores
- Key-Value Stores
- Using Graph Stores
- [Chat Stores] (
-
- Indici comuni * *
- Indice di sintesi (ex indice di elenco)
- Indice Vector Store (più comune)
- Indice dell'albero
- Indice della tabella delle parole chiave
-
- Indice di sintesi (ex indice di elenco) * *

-
- Indice Vector Store * *

-
- Indice degli alberi * *

-
- Indice della tabella delle parole chiave * *

-
https: / / docs.llamaindex.ai / it / stable / module _ guides / memorizzazione / chat _ stores.html)
Meta
Aggiungere meta
document.metadata['lang'] = lang
Filtro
from llama_index.core.vector_stores import (
ExactMatchFilter,
MetadataFilters,
MetadataFilter,
)
filters = MetadataFilters(
filters=[
MetadataFilter(key="post_year", value="2017"),
],
)
# You pass filter as an argument. You can have any type of filter
# we saw above and then pass it to query engine.
query_engine = index.as_query_engine(service_context=service_context,
similarity_top_k=5,
filters = filters,
response_mode='tree_summarize')
response = query_engine.query("Marathon Running")
print(response)
Modalità di risposta
- Affina: Genera le risposte una ad una con il contesto; usa prima il modello text _ qa _ template, e poi usa il modello refine _ template.
- Compatto: predefinito. Simile a perfezionare, tuttavia, il contesto è pieno di una richiesta.
- tree _ summarize
- Simple _ Summarize
Codice sorgente
Documento
a Documentè una sottoclasse di un NodeŸ)
Contiene:
-
testo
-
"Metadati"
-
· roomshipse: rapporto con altri documenti / nodi
-
- Processo di utilizzo atomico * *
from llama_index import Document, VectorStoreIndex
# 数据源
text_list = [text1, text2, ...]
# 手动创建documents
documents = [Document(text=t) for t in text_list]
# 建立索引: 传入document,在VectorStoreIndex再转换:分片转成Node,Embedding等
index = VectorStoreIndex.from_documents(documents)
Diversi metodi di creazione del documento
-
- Crea manualmente * *
from llama_index import Document
text_list = [text1, text2, ...]
documents = [Document(text=t) for t in text_list]
-
- Utilizzare il caricatore dati (connettore) * *
Hanno tutti un metodo LOAD _ DATA ()
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
-
- Dati del campione generati automaticamente * *
document = Document.example()
Meta personalizzata
from llama_index import Document
from llama_index.schema import MetadataMode
document = Document(
text="This is a super-customized document",
metadata={
"file_name": "super_secret_document.txt",
"category": "finance",
"author": "LlamaIndex",
},
excluded_llm_metadata_keys=["file_name"],
metadata_seperator="::",
metadata_template="{key}=>{value}",
text_template="Metadata: {metadata_str}\n-----\nContent: {content}",
)
print(
"The LLM sees this: \n",
document.get_content(metadata_mode=MetadataMode.LLM),
)
print()
print(
"The Embedding model sees this: \n",
document.get_content(metadata_mode=MetadataMode.EMBED),
)
Uscita
The LLM sees this:
Metadata: category=>finance::author=>LlamaIndex
-----
Content: This is a super-customized document
The Embedding model sees this:
Metadata: file_name=>super_secret_document.txt::category=>finance::author=>LlamaIndex
-----
Content: This is a super-customized document
Modello di utilizzo dell'estrazione dei metadati (non capisco)
Nodo
Essenza: frammentazione del documento
Come ottenere:
- Utilizzare la classe NodeParser per convertire il documento in Nodo
- Crea manualmente
Come il documento, ci sono:
-
testo
-
"Metadati"
-
· roomshipse: rapporto con altri documenti / nodi
Quando si converte dal documento al nodo, vengono ereditate informazioni come i metadati.
Node è un cittadino di prima classe a LlamaIndex.
-
- Processo di utilizzo atomico * *
from llama_index.node_parser import SentenceSplitter
# load documents
...
# 手动转换:切片,转成Node
# parse nodes
parser = SentenceSplitter()
nodes = parser.get_nodes_from_documents(documents)
# build index
index = VectorStoreIndex(nodes)
-
- Imposta la relazione * *
from llama_index.schema import TextNode, NodeRelationship, RelatedNodeInfo
node1 = TextNode(text="text_chunk1", id_="node_id1")
node2 = TextNode(text="text_chunk2", id_="node_id2")
node3 = TextNode(text="text_chunk3", id_="node_id3")
# set relationships
node1.relationships[NodeRelationship.NEXT] = RelatedNodeInfo(
node_id=node2.node_id
)
node2.relationships[NodeRelationship.PREVIOUS] = RelatedNodeInfo(
node_id=node1.node_id
)
node2.relationships[NodeRelationship.PARENT] = RelatedNodeInfo(
node_id=node3.node_id, metadata={"key": "val"}
)
print(node2)
NodeParser
Scopo: Convertire le fonti di dati in oggetti Nodi
Specifico: Frammento di un gruppo di oggetti di documento in più oggetti di nodo
Attuazione concreta comune
NodeParser è una classe astratta, che è implementata come segue:
-
- Per tipo di file * *
- SimpleFileNodeParser
- HTMLNodeParser
- JSONNodeParser
- MarkdownNodeParser
-
- Segmentazione di testo * *
- CodeSplitter
- LangchainNodeParser
- SentenceSplitter
- SentenceWindowNodeParser (non capire)
- SemanticSplitterNodeParser (non capisco, si sente più avanzato)
- TokenTextSplitter
-
- Padre - relazione figlio * *
- HierarchicalNodeParser: utilizzato in AutoMergingRetriever
Uso tipico
-
- Uso atomico * *
from llama_index import Document
from llama_index.node_parser import SentenceSplitter
# 创建NodeParser
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
# 调用 get_nodes_from_documents() 方法
# show_progress 可以显示进度
nodes = node_parser.get_nodes_from_documents(
[Document.example(), Document.example()], show_progress=True
)
print(len(nodes))
print()
print(nodes[0])
Uscita
2
Node ID: eaeb6e44-6828-4e36-b7a3-69342de4dc7c
Text: Context LLMs are a phenomenal piece of technology for knowledge
generation and reasoning. They are pre-trained on large amounts of
publicly available data. How do we best augment LLMs with our own
private data? We need a comprehensive toolkit to help perform this
data augmentation for LLMs. Proposed Solution That's where LlamaIndex
comes in. Ll...
-
- Trasformazioni * * in piplina
from llama_index import Document
from llama_index.node_parser import SentenceSplitter
from llama_index.ingestion import IngestionPipeline
from llama_index.node_parser import TokenTextSplitter
documents = [Document.example(), Document.example()]
# 创建NodeParser
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
# 将NodeParser放到Pipeline中的transformations列表
pipeline = IngestionPipeline(transformations=[node_parser])
nodes = pipeline.run(documents=documents)
print(len(nodes))
print()
print(nodes[0])
-
- Utilizzare ServiceContext * *
from llama_index import Document, ServiceContext, VectorStoreIndex
from llama_index.node_parser import SentenceSplitter
from llama_index.ingestion import IngestionPipeline
from llama_index.node_parser import TokenTextSplitter
documents = [Document.example(), Document.example()]
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
service_context = ServiceContext.from_defaults(text_splitter=node_parser)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context, show_progress=True
)
Trasformazioni
Ingresso: un insieme di Nodi
Uscita: un insieme di Nodi
Ci sono due modi comuni:
- _ call _ _ (): sincronizzare
- Asyncronous (): acall
NodeParser e MetadataExtractores appartengono a trasformazioni
-
- Modalità di utilizzo * *
from llama_index.text_splitter import SentenceSplitter
from llama_index.extractors import TitleExtractor
node_parser = SentenceSplitter(chunk_size=512)
extractor = TitleExtractor()
# use transforms directly
nodes = node_parser(documents)
# or use a transformation in async
nodes = await extractor.acall(nodes)
-
- Combinato con ServiceContext * *
from llama_index import ServiceContext, VectorStoreIndex
from llama_index.extractors import (
TitleExtractor,
QuestionsAnsweredExtractor,
)
from llama_index.ingestion import IngestionPipeline
from llama_index.text_splitter import TokenTextSplitter
transformations = [
TokenTextSplitter(chunk_size=512, chunk_overlap=128),
TitleExtractor(nodes=5),
QuestionsAnsweredExtractor(questions=3),
]
# 创建ServiceContext,传入Transfrmation
service_context = ServiceContext.from_defaults(
transformations=[text_splitter, title_extractor, qa_extractor]
)
# 传入VectorStoreIndex的from_documents()或insert()方法
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
ServiceContext
un pacchetto di servizi e configurazioni utilizzati in un gasdotto LlamaIndex.
-
- Può essere configurato * *
from llama_index import (
ServiceContext,
OpenAIEmbedding,
PromptHelper,
)
from llama_index.llms import OpenAI
from llama_index.text_splitter import SentenceSplitter
# 设置LLM
llm = OpenAI(model="text-davinci-003", temperature=0, max_tokens=256)
# 设置Embedding模型
embed_model = OpenAIEmbedding()
# 设置Chunk的大小
text_splitter = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
prompt_helper = PromptHelper(
context_window=4096,
num_output=256,
chunk_overlap_ratio=0.1,
chunk_size_limit=None,
)
service_context = ServiceContext.from_defaults(
llm=llm, # 设置LLM
embed_model=embed_model, # 设置Embedding模型
text_splitter=text_splitter, # 设置Chunk的大小
prompt_helper=prompt_helper,
)
-
- Parametri di costruzione * * (più conveniente)
-
- Kwargs per nodo parser * *:
- "chunk _ sizeť
- "chunk _ sovrapposti"
-
- Kwargs per il prompt helper * *:
- Finestra:
- Ÿnum _ outputŸ
Per esempio,
service_context = ServiceContext.from_defaults(chunk_size=1000)
-
- Configurazione globale * *
from llama_index import set_global_service_context
set_global_service_context(service_context)
-
- Configurazione locale * *
query_engine = index.as_query_engine(service_context=service_context)
StorageContext
Definisce il backend di memorizzazione per il luogo in cui sono memorizzati i documenti, le embedding e gli indici.
[Riferimento API] (https: / / docs.llamaindex.ai / it / stable / api _ reference /)
store = PGVectorStore(
connection_string=conn_string,
async_connection_string=async_conn_string,
schema_name=PGVECTOR_SCHEMA,
table_name=PGVECTOR_TABLE,
)
index = VectorStoreIndex.from_vector_store(store)
VectorStoreIndex
Funzione costruttore
index = VectorStoreIndex.from_vector_store(store)
Ci sono due tipi di motore:
- Query Engine: BaseQueryEngine
- Chat Engines: BaseChatEngine
Crea motore
index.as_query_engine()# BaseQueryEngine
index.as_query_engine(streaming=True)# 流式 BaseQueryEngine
index.as_chat_engine() # BaseChatEngine; 流式不是在这里控制
Query
# Query
response = await query_engine.aquery(query) # 流式
response = await query_engine.aquery(query)
# Chat
response = await chat_engine.astream_chat(last_message_content, messages) # 流式在这里控制
response = await chat_engine.achat(last_message_content, messages)
BaseQueryEngine
query
acquario
BaseChatEngine
- Chat
- stream _ chat
- achat
- astream _ chat
Supporta lo streaming: flusso
È supportato Asyncronous: a partire da un
Tipo di risposta
# Query
RESPONSE_TYPE = Union[
Response,
StreamingResponse, AsyncStreamingResponse, #流式
PydanticResponse
]
# Chat
StreamingAgentChatResponse #流式
AGENT_CHAT_RESPONSE_TYPE = Union[AgentChatResponse, StreamingAgentChatResponse] #非流式
Come affrontare la risposta in streaming
Utilizzare le API standard di Python:
- StreamingResponse ()
- AsyncStreamingResponse
- StreamingResponse
- Query
@r.post("")
async def chat(
request: Request,
queryData: _QueryData,
query_engine: BaseQueryEngine = Depends(get_query_engine_stream),
):
query = queryData.query
streaming_response = await query_engine.aquery(query)
async def event_generator():
async for token in streaming_response.async_response_gen:
if await request.is_disconnected():
break
yield f"data: {token}\n\n"
return StreamingResponse(event_generator(), media_type="text/event-stream")
- Chat
@r.post("")
async def chat(
request: Request,
data: _ChatData,
chat_engine: BaseChatEngine = Depends(get_chat_engine),
):
last_message_content, messages = await parse_chat_data(data)
response = await chat_engine.astream_chat(last_message_content, messages)
async def event_generator():
async for token in response.async_response_gen():
if await request.is_disconnected():
break
yield token
return StreamingResponse(event_generator(), media_type="text/plain")
StreamingResponse
class AsyncStreamingResponse:
async_response_gen: TokenAsyncGen
class StreamingResponse:
response_gen: TokenGen
Modalità di risposta
Monitoraggio e controllo
Tutoriali
Deeplear tutorial
Building and Evaluating Advanced RAG Applications:链接 Bilibili
-
- Testo comune a SQL e ricerca semantica * *
Questo video copre gli strumenti incorporati in LlamaIndex per combinare SQL e ricerca semantica in un'unica interfaccia di query unificata.