LlamaIndex
Python 및 Typescript 버전
Python 버전의 문서는 더 정교하고 ts는 비교적 불량한 편인가요?
입문
환경 만들기
conda create --name llamaindex python=3.9.19
conda activate llamaindex
VSCode에서 Conda 환경 설정
Python: Select Interpreter
라이브러리 설치
pip install llama-index pypdf sentence_transformers
OpenAI 구성
vim ~/.bashrc
환경 변수 추가
export OPENAI_API_KEY="sk-xxxx"
검증
echo $OPENAI_API_KEY
접근성
명령줄에서 구성: goproxy
빠른 시작
import os.path
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
import logging
import sys
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
# check if storage already exists
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):
# load the documents and create the index
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# store it for later
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
# load the existing index
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
# either way we can now query the index
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
사용하는 completions 메소드
/chat/completions
쿼리 매개변수
{
"messages": [
{
"role": "system",
"content": "You are an expert Q&A system that is trusted around the world.\nAlways answer the query using the provided context information, and not prior knowledge.\nSome rules to follow:\n1. Never directly reference the given context in your answer.\n2. Avoid statements like \"Based on the context, ...\" or \"The context information ...\" or anything along those lines."
},
{
"role": "user",
"content": "xxx"
}
],
"model": "gpt-3.5-turbo",
"stream": false,
"temperature": 0.1
}
System Prompt
You are an expert Q&A system that is trusted around the world.
Always answer the query using the provided context information, and not prior knowledge.
Some rules to follow:
1. Never directly reference the given context in your answer.
2. Avoid statements like "Based on the context, ..." or "The context information ..." or anything along those lines.
전 세계적으로 신뢰할 수 있는 전문가 Q&A 시스템입니다.질문에 대답할 때 이전 지식 대신 제공된 배경 정보를 항상 사용합니다.따라야 할 몇 가지 규칙:
1.절대 답변에서 주어진 배경 정보를 직접 참조하지 마십시오. 2."배경 정보에 따라..."를 사용하지 않도록 합니다.또는 "배경 정보에서 알 수 있듯이..."또는 그와 비슷한 표현도 할 수 있습니다.
User Prompt
Context information is below.
---------------------
file_path: data/paul_graham_essay.txt
xxx
---------------------
Given the context information and not prior knowledge, answer the query.
Query: What did the author do growing up?
Answer:
장면 적용
| 应用场 | 说明 |
|---|---|
| Q&A | 最重要 |
| Chatbots | |
| Agents | 高级 |
| Structured Data Extraction | 有用,整理聊天记录等 |
| Multi-modal |
기본 원리
기본 프로세스
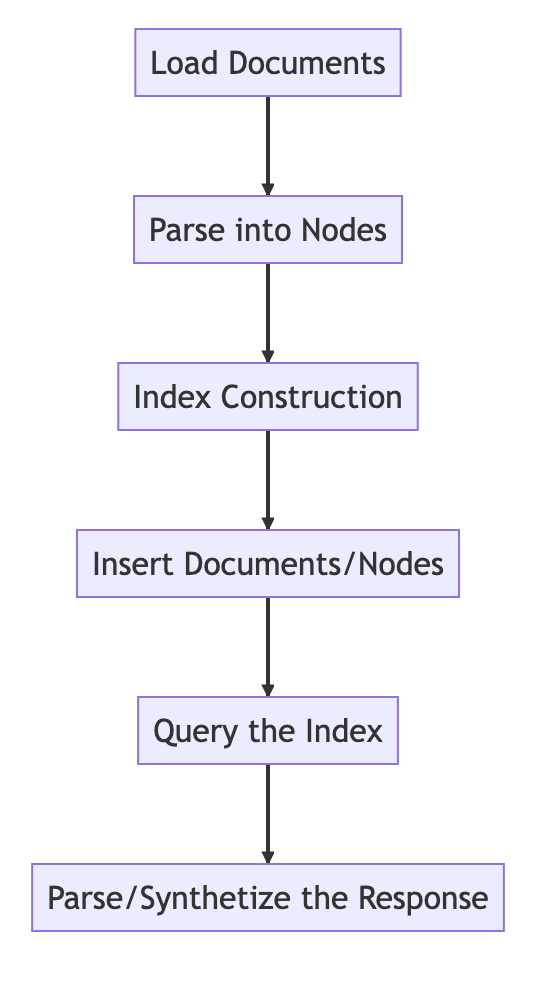
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# Load in data as Document objects
documents = SimpleDirectoryReader('data').load_data()
# 切片,转成Node
# Parse Document objects into Node objects to represent chunks of data
index = VectorStoreIndex.from_documents(documents)
# Index Construction:创建索引
# Build an index over the Documents or Nodes
query_engine = index.as_query_engine()
# The response is a Response object containing the text response and source Nodes
summary = query_engine.query("What is the text about")
print("What is the data about:")
print(summary)
Chunking과 Node
소스 데이터 --->documents-->Nodes
Documents: 본문 및 meta 정보 포함
Document ID
document는 사실 Node의 하위 클래스입니다.
이상하게 문서 한 개는 여러 개의 문서로 잘라집니다.
TextNode: NodeParser를 사용하여 document를 여러 개의 Node로 자릅니다.
Document ID 포함
Node는 Node 이전과 연결됨
- NodeParser는 문서 객체 목록을 수신합니다. 2.Spacy의 문장 분할을 사용하여 각 문서의 텍스트를 문장으로 분할합니다. 3.각 문장은 노드를 나타내는 TextNode 객체에 래핑됩니다.
- TextNode는 문서 ID, 문서의 위치 등과 같은 메타데이터와 함께 문장 텍스트를 포함합니다. 5.TextNode 객체의 목록을 반환합니다.
문서 및 index 저장
두 가지 방법
- 로컬 디스크에 저장
- 벡터 데이터베이스에 저장
로컬 디스크에 저장
import os.path
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
import sys
# check if storage already exists
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):
# 保存数据: Load the documents and create the index
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# store it for later
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
# 从磁盘加载回数据: load the existing index
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
색인화
각 Node에 대해 Embedding 작성
VectorStroreIndex에 색인 작성
1.VectorStoreIndex의 경우 노드의 텍스트 embedding은 FISS 인덱스에 저장되므로 노드에서 유사성 검색을 빠르게 수행할 수 있습니다. 2.인덱스는 각 노드의 메타데이터(예: document ID, 위치 등)도 저장합니다. 3.노드는 문서의 내용을 검색하거나 특정 문서를 검색할 수 있습니다.
조회 색인
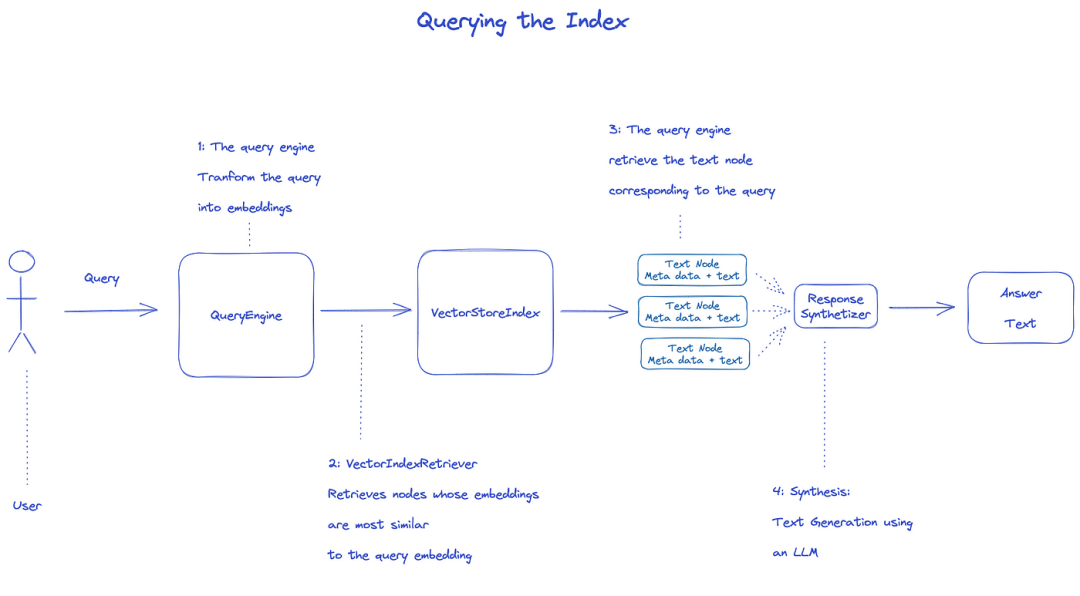
색인을 질의하려면 QueryEngine을 사용합니다.
- Retriever는 질의 인덱스에서 관련 노드를 가져옵니다.예를 들어 VectorIndexRetriever는 embedding 쿼리와 가장 유사한 노드를 검색합니다. 2.검색된 노드 목록이 ResponseSynthesizer에 전달되어 최종 출력을 생성합니다. 3.기본적으로 ResponseSynthesizer는 각 노드를 순서대로 처리하며, 각 노드는 LLM API를 한 번 호출합니다.
- LLM은 최종 출력을 위해 질의 및 노드 텍스트를 입력합니다. 5.이러한 각 노드의 응답은 최종 출력 문자열로 집계됩니다.
from llama_index import (
VectorStoreIndex,
get_response_synthesizer,
)
from llama_index.retrievers import VectorIndexRetriever
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.postprocessor import SimilarityPostprocessor
from llama_index import StorageContext, load_index_from_storage
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir="storage")
# load index
index = load_index_from_storage(storage_context)
# configure retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=10,
)
# configure response synthesizer
response_synthesizer = get_response_synthesizer()
# assemble query engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
node_postprocessors=[SimilarityPostprocessor(similarity_cutoff=0.7)],
)
# query
response = query_engine.query("What did the author do growing up?")
print(response)
공식 문서: Understanding
데이터 처리를 위한 세 가지 프로세스
Data cleaning/feature engineering pipelines in the ML world, or ETL pipelines in the traditional data setting.
This ingestion pipeline typically consits of three main stages:
- 로드 더 데이타
- 데이터 전송
- Index and store the data
데이터 로드
**대상: **다양한 유형의 데이터를 document 개체로 포맷합니다.
**입력:**다양한 유형의 데이터
출력:document 개체
3가지 방법
SimpleDirectoryReader클래스 사용: 가장 편리함LlamaHub의Reader: 이미 쓰여진 다양한 도구들- 직접
document만들기
SimpleDirectoryReader 클래스
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
지원 Markdown, PDFs, Word documents(.docx), PowerPoint decks, images(.jpg, .png), audio and video
Llamahub
- Notion (
NotionPageReader) - Google Docs (
GoogleDocsReader) - Slack (
SlackReader) - Discord (
DiscordReader) - Apify Actors (
ApifyActor). Can crawl the web, scrape webpages, extract text content, download files including.pdf,.jpg,.png,.docx, etc.这个可以爬虫
직접 document 만들기
from llama_index.schema import Document
doc = Document(text="text")
데이터 변환
**이유: **편리한 검색 및 LLM 효율적인 사용
** 특정 작업: **
document를 조각화(chunking)- 메타데이터 추출
- 엠베딩
입력:Node
출력:Node
캡슐화된 API
VectorStoreIndex를 이용한 from_documents() 메서드
from llama_index import VectorStoreIndex
vector_index = VectorStoreIndex.from_documents(documents)
vector_index.as_query_engine()
매개변수 사용자 정의 방법
아이디어: ServiceContext를 사용하여 사용자 정의
text_splitter = SentenceSplitter(chunk_size=512, chunk_overlap=10)
service_context = ServiceContext.from_defaults(text_splitter=text_splitter)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
원자 API
표준 사용 모드
from llama_index import Document
from llama_index.embeddings import OpenAIEmbedding
from llama_index.text_splitter import SentenceSplitter
from llama_index.extractors import TitleExtractor
from llama_index.ingestion import IngestionPipeline, IngestionCache
# 加载数据源
documents = SimpleDirectoryReader("./data").load_data()
# 创建转换数据的工作流
# create the pipeline with transformations
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=25, chunk_overlap=0), # 分片
TitleExtractor(), # 提取Meta信息
OpenAIEmbedding(), # Embedding
]
)
# 执行流程,生成节点
# run the pipeline
nodes = pipeline.run(documents=documents)
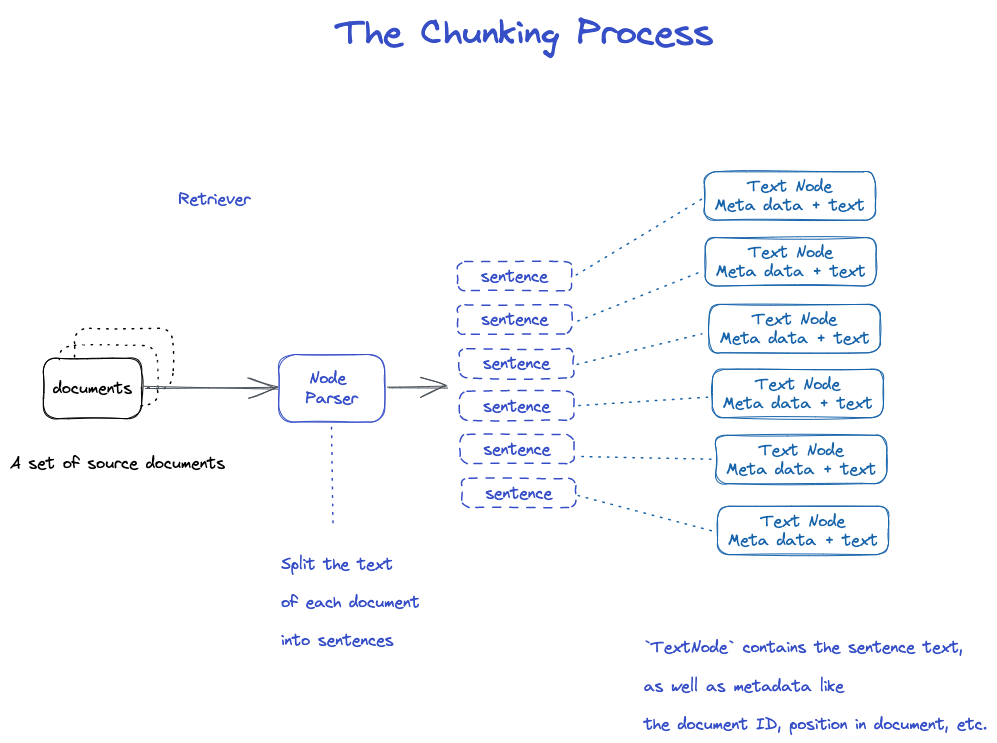
분판
Node Parser 모듈을 구체적으로 볼 수 있는 많은 전략들이 있다.
메타데이터 추가
Document 및 Node를 사용자 정의하고 메타데이터를 추가할 수 있습니다.
Node 객체 직접 작성
from llama_index.schema import TextNode
node1 = TextNode(text="<text_chunk>", id_="<node_id>")
node2 = TextNode(text="<text_chunk>", id_="<node_id>")
index = VectorStoreIndex([node1, node2])
인덱싱
인덱스 분류
일반 인덱스
- Summary Index (formerly List Index)
- Vector Store Index(가장 흔함) Tree Index
- Keyword Table Index
Summary Index (formerly List Index)

Vector Store Index

Tree Index

Keyword Table Index

메타
Meta 추가
document.metadata['lang'] = lang
필터링
from llama_index.core.vector_stores import (
ExactMatchFilter,
MetadataFilters,
MetadataFilter,
)
filters = MetadataFilters(
filters=[
MetadataFilter(key="post_year", value="2017"),
],
)
# You pass filter as an argument. You can have any type of filter
# we saw above and then pass it to query engine.
query_engine = index.as_query_engine(service_context=service_context,
similarity_top_k=5,
filters = filters,
response_mode='tree_summarize')
response = query_engine.query("Marathon Running")
print(response)
Response Modes
- refine: context와 한 번에 하나씩 답을 생성합니다. text_qa_template 템플릿을 사용한 다음 refine_template 템플릿을 사용합니다.
- compact: 기본값입니다.Refine과 유사하지만 context는 한 번의 요청으로 채워집니다.
- tree_summarize
- simple_summarize
소스 코드
문서
a
Documentis a subclass of aNode)
다음을 포함합니다.
-
text
-
metadata -
relationships: 다른 Documents/Nodes와의 관계
원자 사용 절차
from llama_index import Document, VectorStoreIndex
# 数据源
text_list = [text1, text2, ...]
# 手动创建documents
documents = [Document(text=t) for t in text_list]
# 建立索引: 传入document,在VectorStoreIndex再转换:分片转成Node,Embedding等
index = VectorStoreIndex.from_documents(documents)
Document를 만드는 여러 방법
수동 생성
from llama_index import Document
text_list = [text1, text2, ...]
documents = [Document(text=t) for t in text_list]
** data loader(connector) 사용**
Load_data() 메서드가 있습니다.
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
자동으로 생성된 샘플 데이터
document = Document.example()
사용자 정의 메타
from llama_index import Document
from llama_index.schema import MetadataMode
document = Document(
text="This is a super-customized document",
metadata={
"file_name": "super_secret_document.txt",
"category": "finance",
"author": "LlamaIndex",
},
excluded_llm_metadata_keys=["file_name"],
metadata_seperator="::",
metadata_template="{key}=>{value}",
text_template="Metadata: {metadata_str}\n-----\nContent: {content}",
)
print(
"The LLM sees this: \n",
document.get_content(metadata_mode=MetadataMode.LLM),
)
print()
print(
"The Embedding model sees this: \n",
document.get_content(metadata_mode=MetadataMode.EMBED),
)
수출
The LLM sees this:
Metadata: category=>finance::author=>LlamaIndex
-----
Content: This is a super-customized document
The Embedding model sees this:
Metadata: file_name=>super_secret_document.txt::category=>finance::author=>LlamaIndex
-----
Content: This is a super-customized document
Metadata Extraction Usage Pattern(이해되지 않음)
Node
본질 : document의 분판
얻을 수 있는 방법:
- NodeParser 클래스를 사용하여 document를 Node로 전환
- 수동 생성
Document와 마찬가지로 다음과 같은 기능이 있습니다.
-
text
-
metadata -
relationships: 다른 Documents/Nodes와의 관계
Document에서 Node로 변환하면 metadata와 같은 정보가 상속됩니다.
Node는 LlamaIndex에서 일등 시민이다.
원자 사용 절차
from llama_index.node_parser import SentenceSplitter
# load documents
...
# 手动转换:切片,转成Node
# parse nodes
parser = SentenceSplitter()
nodes = parser.get_nodes_from_documents(documents)
# build index
index = VectorStoreIndex(nodes)
관계 설정
from llama_index.schema import TextNode, NodeRelationship, RelatedNodeInfo
node1 = TextNode(text="text_chunk1", id_="node_id1")
node2 = TextNode(text="text_chunk2", id_="node_id2")
node3 = TextNode(text="text_chunk3", id_="node_id3")
# set relationships
node1.relationships[NodeRelationship.NEXT] = RelatedNodeInfo(
node_id=node2.node_id
)
node2.relationships[NodeRelationship.PREVIOUS] = RelatedNodeInfo(
node_id=node1.node_id
)
node2.relationships[NodeRelationship.PARENT] = RelatedNodeInfo(
node_id=node3.node_id, metadata={"key": "val"}
)
print(node2)
노드파서
용도:데이터 소스를 노드 객체로 변환
특정: document 객체 세트를 여러 Node 객체로 분할
일반적인 구체적인 구현
NodeParser는 다음과 같은 추상 클래스입니다.
파일 유형별
- SimpleFileNodeParser
- HTMLNodeParser
- JSONNodeParser
- 마크다운노데Parser
텍스트 분할
- CodeSplitter
- LangchainNodeParser
- SentenceSplitter
- SentenceWindowNodeParser (이해되지 않음)
- SemanticSplitterNodeParser (이해하지 못하고 고급스럽게 느껴짐)
- TokenTextSplitter
상/하위 관계
- HierarchicalNodeParser: AutoMergingRetriever에서 사용
일반적인 용법
원자 사용
from llama_index import Document
from llama_index.node_parser import SentenceSplitter
# 创建NodeParser
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
# 调用 get_nodes_from_documents() 方法
# show_progress 可以显示进度
nodes = node_parser.get_nodes_from_documents(
[Document.example(), Document.example()], show_progress=True
)
print(len(nodes))
print()
print(nodes[0])
수출
2
Node ID: eaeb6e44-6828-4e36-b7a3-69342de4dc7c
Text: Context LLMs are a phenomenal piece of technology for knowledge
generation and reasoning. They are pre-trained on large amounts of
publicly available data. How do we best augment LLMs with our own
private data? We need a comprehensive toolkit to help perform this
data augmentation for LLMs. Proposed Solution That's where LlamaIndex
comes in. Ll...
Pipline의 Transformations
from llama_index import Document
from llama_index.node_parser import SentenceSplitter
from llama_index.ingestion import IngestionPipeline
from llama_index.node_parser import TokenTextSplitter
documents = [Document.example(), Document.example()]
# 创建NodeParser
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
# 将NodeParser放到Pipeline中的transformations列表
pipeline = IngestionPipeline(transformations=[node_parser])
nodes = pipeline.run(documents=documents)
print(len(nodes))
print()
print(nodes[0])
ServiceContext 사용
from llama_index import Document, ServiceContext, VectorStoreIndex
from llama_index.node_parser import SentenceSplitter
from llama_index.ingestion import IngestionPipeline
from llama_index.node_parser import TokenTextSplitter
documents = [Document.example(), Document.example()]
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
service_context = ServiceContext.from_defaults(text_splitter=node_parser)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context, show_progress=True
)
변환
가져오기:Node 세트
내보내기:Node 세트
두 가지 공통적인 방법이 있습니다.
__call__(): 동기화acall(): 비동기식
NodeParser와 MetadataExtractor는 Transformations에 속함
사용 모드
from llama_index.text_splitter import SentenceSplitter
from llama_index.extractors import TitleExtractor
node_parser = SentenceSplitter(chunk_size=512)
extractor = TitleExtractor()
# use transforms directly
nodes = node_parser(documents)
# or use a transformation in async
nodes = await extractor.acall(nodes)
ServiceContext와 함께 사용
from llama_index import ServiceContext, VectorStoreIndex
from llama_index.extractors import (
TitleExtractor,
QuestionsAnsweredExtractor,
)
from llama_index.ingestion import IngestionPipeline
from llama_index.text_splitter import TokenTextSplitter
transformations = [
TokenTextSplitter(chunk_size=512, chunk_overlap=128),
TitleExtractor(nodes=5),
QuestionsAnsweredExtractor(questions=3),
]
# 创建ServiceContext,传入Transfrmation
service_context = ServiceContext.from_defaults(
transformations=[text_splitter, title_extractor, qa_extractor]
)
# 传入VectorStoreIndex的from_documents()或insert()方法
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
ServiceContext
a bundle of services and configurations used across a LlamaIndex pipeline.
구성 가능
from llama_index import (
ServiceContext,
OpenAIEmbedding,
PromptHelper,
)
from llama_index.llms import OpenAI
from llama_index.text_splitter import SentenceSplitter
# 设置LLM
llm = OpenAI(model="text-davinci-003", temperature=0, max_tokens=256)
# 设置Embedding模型
embed_model = OpenAIEmbedding()
# 设置Chunk的大小
text_splitter = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
prompt_helper = PromptHelper(
context_window=4096,
num_output=256,
chunk_overlap_ratio=0.1,
chunk_size_limit=None,
)
service_context = ServiceContext.from_defaults(
llm=llm, # 设置LLM
embed_model=embed_model, # 设置Embedding模型
text_splitter=text_splitter, # 设置Chunk的大小
prompt_helper=prompt_helper,
)
** 생성자 전삼 ** (더 편리함)
Kwargs for node parser:
chunk_sizechunk_overlap
Kwargs for prompt helper:
context_window:num_output
예를 들면,
service_context = ServiceContext.from_defaults(chunk_size=1000)
전역 구성
from llama_index import set_global_service_context
set_global_service_context(service_context)
로컬 구성
query_engine = index.as_query_engine(service_context=service_context)
StorageContext
defines the storage backend for where the documents, embeddings, and indexes are stored
[API Reference] (https://docs.llamaindex.ai/en/stable/api_reference/)
store = PGVectorStore(
connection_string=conn_string,
async_connection_string=async_conn_string,
schema_name=PGVECTOR_SCHEMA,
table_name=PGVECTOR_TABLE,
)
index = VectorStoreIndex.from_vector_store(store)
VectorStoreIndex
생성자
index = VectorStoreIndex.from_vector_store(store)
Engine에는 다음과 같은 두 가지 유형이 있습니다.
- Query Engine: BaseQueryEngine
- Chat Engines: BaseChatEngine
Engine 작성
index.as_query_engine()# BaseQueryEngine
index.as_query_engine(streaming=True)# 流式 BaseQueryEngine
index.as_chat_engine() # BaseChatEngine; 流式不是在这里控制
조회
# Query
response = await query_engine.aquery(query) # 流式
response = await query_engine.aquery(query)
# Chat
response = await chat_engine.astream_chat(last_message_content, messages) # 流式在这里控制
response = await chat_engine.achat(last_message_content, messages)
BaseQueryEngine
-query
aquery
BaseChatEngine
- chat
- stream_chat
- achat
- astream_chat
스트리밍 지원: stream
비동기식 지원: a 시작
응답 유형
# Query
RESPONSE_TYPE = Union[
Response,
StreamingResponse, AsyncStreamingResponse, #流式
PydanticResponse
]
# Chat
StreamingAgentChatResponse #流式
AGENT_CHAT_RESPONSE_TYPE = Union[AgentChatResponse, StreamingAgentChatResponse] #非流式
스트리밍 응답 처리 방법
Python 표준 인터페이스 사용:
- StreamingResponse()
- AsyncStreamingResponse
- StreamingResponse
- 쿼리
@r.post("")
async def chat(
request: Request,
queryData: _QueryData,
query_engine: BaseQueryEngine = Depends(get_query_engine_stream),
):
query = queryData.query
streaming_response = await query_engine.aquery(query)
async def event_generator():
async for token in streaming_response.async_response_gen:
if await request.is_disconnected():
break
yield f"data: {token}\n\n"
return StreamingResponse(event_generator(), media_type="text/event-stream")
- 챗
@r.post("")
async def chat(
request: Request,
data: _ChatData,
chat_engine: BaseChatEngine = Depends(get_chat_engine),
):
last_message_content, messages = await parse_chat_data(data)
response = await chat_engine.astream_chat(last_message_content, messages)
async def event_generator():
async for token in response.async_response_gen():
if await request.is_disconnected():
break
yield token
return StreamingResponse(event_generator(), media_type="text/plain")
StreamingResponse
class AsyncStreamingResponse:
async_response_gen: TokenAsyncGen
class StreamingResponse:
response_gen: TokenGen
Response Modes
감시
자습서
Deeplear 튜토리얼
Building and Evaluating Advanced RAG Applications:链接 Bilibili
Joint Text to SQL and Semantic Search
This video covers the tools built into LlamaIndex for combining SQL and semantic search into a single unified query interface.