RAG:检索增强生成
Rage
RAG: Geração aumentada de recuperação
Estás a tentar resolver um caso complicado.
O papel de um detective é recolher pistas, provas e registos históricos relacionados com o caso. Depois que o detetive recolheu a informação, o repórter resumiu os fatos em uma história fascinante e apresentou uma narrativa coerente.
O problema com a LLM
- Alucinação: fornecer informações falsas sem resposta.
- O LLM utiliza informações desactualizadas e não tem acesso às informações mais recentes e fiáveis após o seu prazo de conhecimento.
- Além disso, a resposta dada pela LLM não se refere à sua fonte, o que significa que a sua alegação não pode ser verificada pelo utilizador como sendo exata ou totalmente confiável. Este facto realça a importância da verificação e da avaliação independentes na utilização de dados gerados pela inteligência artificial.
您可以将大型语言模型看作是一个过于热情的新员工,他拒绝随时了解时事,但总是会绝对自信地回答每一个问题。
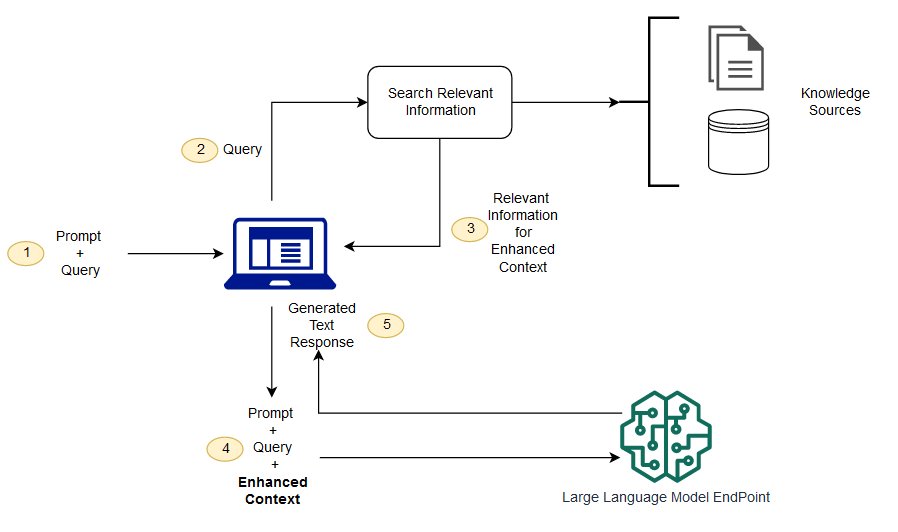
A RAG é uma forma de resolver alguns destes desafios. Ele redireciona a LLM para obter informações relevantes de fontes de conhecimento autorizadas e predeterminadas. Organizações têm mais controle sobre a saída de texto gerada, e os usuários podem aprender mais sobre como LLM gera respostas.
O processo da LLM
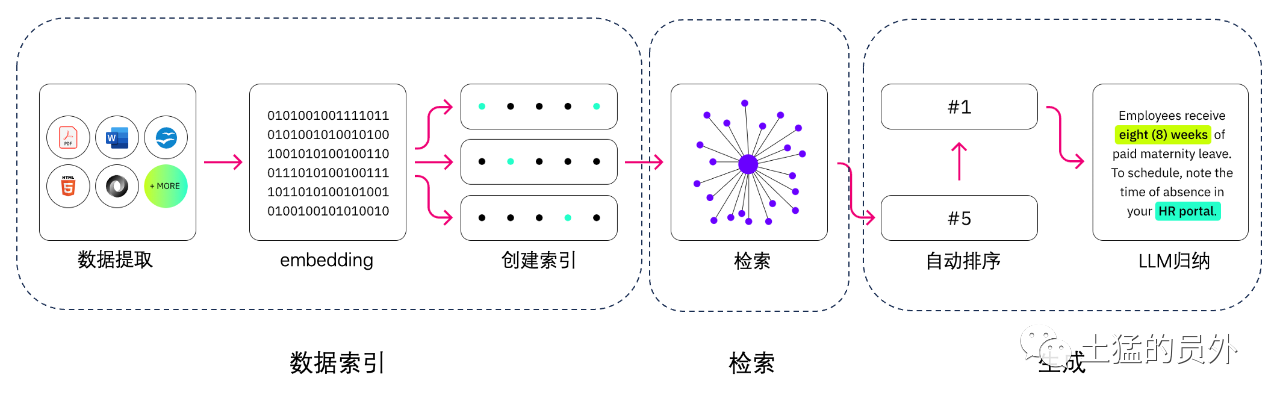
Qual é a diferença entre a geração de recuperação melhorada e a pesquisa semântica?
Pesquisa semântica pode melhorar os resultados de rag para organizações que querem adicionar um grande número de fontes de conhecimento externo para suas aplicações LLM. As empresas modernas armazenam uma grande quantidade de informação em uma variedade de sistemas, tais como manuais, FAQ, relatórios de pesquisa, guias de serviço ao cliente e repositórios de documentos de recursos humanos. A recuperação contextual é um desafio em escala e, portanto, degrada a qualidade da produção gerada.
Tecnologia de pesquisa semântica: poderá procurar grandes bases de dados que contenham informações diferentes e obter dados com maior precisão. Por exemplo, eles podem responder perguntas como: "Quanto você gastou em manutenção mecânica no ano passado?" Questões como * mapeando a questão para o documento relevante e devolvendo texto específico em vez de resultados de pesquisa. Os desenvolvedores podem então usar esta resposta para fornecer mais contexto para o LLM.
Soluções de pesquisa tradicionais ou de palavras-chave nas RAG produzem resultados limitados para o conhecimento - tarefas intensivas. Os desenvolvedores também têm que lidar com a incorporação de palavras, fragmentação de documentos, e outras questões complexas ao preparar dados manualmente. Em contraste, a tecnologia de pesquisa semântica pode fazer todo o trabalho para o qual a base de conhecimento está preparada, para que os desenvolvedores não tenham que fazer isso. Eles também geram parágrafos relacionados semânticamente e palavras de marcação ordenadas pela relevância para maximizar a qualidade da carga útil da RAG.
Três componentes principais das OAR
O modelo de geração melhorada de recuperação é composto principalmente por três componentes principais:
- Recuperação: Responsável pela obtenção de informações relevantes de fontes externas de conhecimento.
- Sorter (Ranker): Avalia e prioriza os resultados da pesquisa.
- Gerador: utilizar os resultados da recuperação e da triagem, combinados com a entrada do utilizador, para gerar a resposta final ou o conteúdo.
Mapa do cérebro de trapos
Esta foto é muito detalhada!
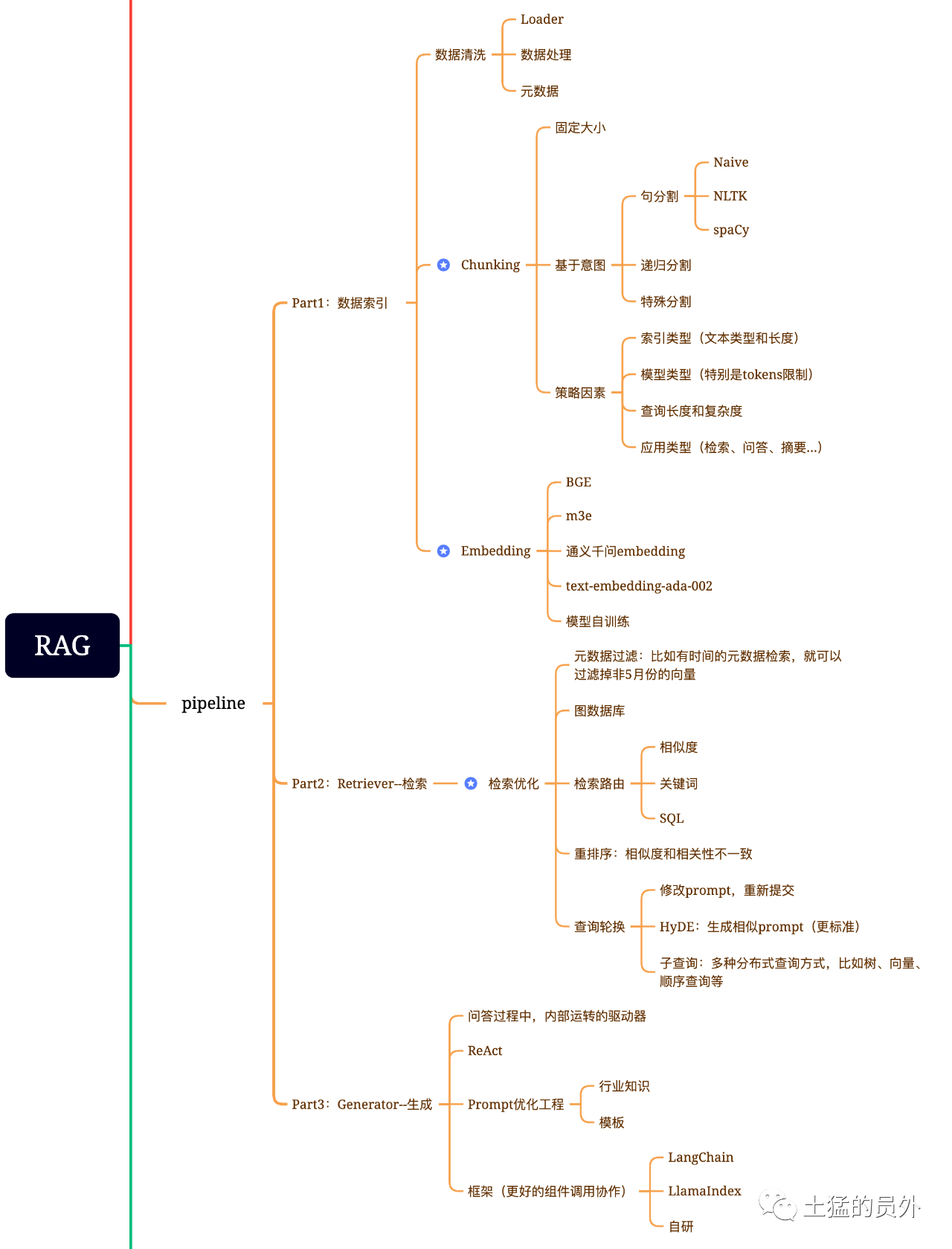
Índice de dados
- *** Extracção de dados **
Limpeza de dados: incluindo o Loader de Dados, extração de PDF, Word, Markdown, base de dados e API, etc.
- tratamento de dados: incluindo o tratamento de formatos de dados, a eliminação do conteúdo não identificável, a compressão e a formatação, etc. Extracção de metadados: é fundamental extrair o nome do ficheiro, a hora, o título do capítulo, a imagem alt e outras informações.
Ferramentas para a extracção de dados
- Unstructurados (utilizados)
- LlamaParse (utilizada)
- Google document IA
- extrato de AWS
- pdf2image + pytesseract
Procurar
A otimização de recuperação é geralmente dividida em cinco partes:
-** Filtragem de metadados**: Quando dividirmos o índice em muitos pedaços, a eficiência de recuperação será um problema. Neste momento, se os metadados podem ser filtrados primeiro, a eficiência e relevância serão muito melhoradas. Por exemplo, perguntamos: "Ajudem-me a resolver todos os contratos no departamento XX, em Maio deste ano, que incluem a aquisição de equipamento XX?" . Neste momento, se houver metadados, podemos procurar os dados relevantes de "XX Department + Maio de 2023", e a quantidade de recuperação pode tornar-se 1/10000 da situação global de uma só vez.
-** Recuperação da relação Grafo **: Se você pode transformar muitas entidades em nós e a relação entre elas em relação, você pode usar a relação entre conhecimento para fazer respostas mais precisas. Especialmente no que se refere a alguns problemas relacionados com o lúpulo, a utilização do índice de dados gráficos tornará a recuperação mais relevante.
-
** Tecnologia Retrieval ** : Mencionam-se alguns métodos de pré-processamento, e os principais métodos de recuperação são os seguintes:
-
- 相似度检索:前面我已经写过那篇文章《大模型应用中大部分人真正需要去关心的核心——Embedding》中有提到六种相似度算法,包括欧氏距离、曼哈顿距离、余弦等,后面我还会再专门写一篇这方面的文章,可以关注我,yeah;
-
*** Procura por palavras-chave ** : Este é um método de pesquisa muito tradicional, mas às vezes também é muito importante. A filtragem de metadados que mencionamos agora é um tipo, e outro é fazer um resumo do Chunk primeiro, e então encontrar o possível pedaço relevante através da recuperação de palavras-chave para aumentar a eficiência de recuperação. Diz-se que Claude.ai fez o mesmo.
-
*** Pesquisa SQL ** : Isto é mais tradicional, mas para algumas aplicações empresariais localizadas, a consulta SQL é um passo essencial. Por exemplo, os dados de vendas que mencionei anteriormente precisam de ser pesquisados pelo SQL primeiro.
-
Outras: ainda há muitas técnicas de recuperação, por isso vamos falar sobre isso mais tarde.
Em muitos casos, os nossos resultados de recuperação não são ideais porque há um grande número de partes no sistema, e as dimensões que recuperamos não são necessariamente óptimas, e os resultados de uma pesquisa podem não ser tão ideais em termos de relevância. Neste momento, precisamos de ter algumas estratégias para reordenar os resultados da recuperação, como o uso de planb para reordenar, ou para ajustar a relevância combinada, a adequação e outros fatores para obter uma classificação que está mais em consonância com o nosso cenário de negócio. Porque depois deste passo, enviaremos o resultado para a LLM para processamento final, por isso o resultado desta parte é muito importante. Haverá também um juiz interno para rever a correlação e desencadear a reordenação.
-
** Rotação de consultas ** : Esta é uma forma de consulta e recuperação, e normalmente existem várias formas:
-
** Sub - Questionário: ** Poderá usar várias estratégias de consulta em diferentes cenários. Por exemplo, poderá usar o questionário fornecido por frameworks tais como LlamaIndex, Tree Query (a partir de nós de folhas, consulta passo a passo, merge), consulta vetorial, ou os blocos de consulta sequenciais mais primitivos, etc.**;
-** Hyde:** Esta é uma forma de copiar empregos para gerar modelos semelhantes ou mais padrão. ***
Re - Rank -
A maioria dos bancos de dados vetoriais sacrificam um certo grau de precisão para eficiência computacional. Isto faz com que os resultados da recuperação sejam aleatórios, e o top K original devolvido não é necessariamente o mais relevante.
使用BAAI/bge-reranker-base、BAAI/bge-reranker-large等开源模型来完成Re-Rank操作。
E a base da NetEase - Reranker - apoia a China, a Grã-Bretanha, o Japão e a Coreia do Sul.
Retirar/ Obter a Mistura
Duas, uma pergunta à maneira:
- Recuperação semântica (Pesquisa Vector) / ** Recolha da base de dados vetorial **
- Procura por palavras- chave (busca de palavras- chave) / Procura por palavras- chave Recordação
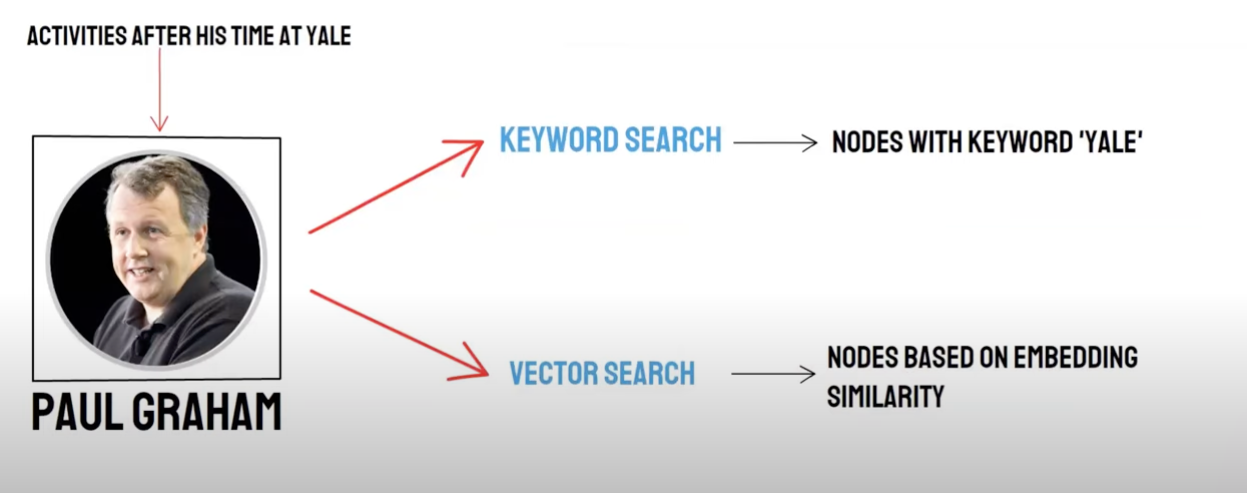
A recolha de dados vetoriais e a recuperação de palavras-chave têm as suas próprias vantagens e desvantagens, pelo que a combinação dos resultados da recolha dos dois pode melhorar a precisão e eficiência de recuperação geral. O algoritmo de fusão de ordenação recíproca (Rank Fusion recíproco, RRF) calcula a pontuação total após a fusão através da soma ponderada da classificação de cada documento em diferentes métodos de recolha.
Quando você escolhe usar a recuperação de palavras-chave, isto é, ** Palavra-chave Retrieval** selecionar as palavras-chave em conjunto **, PAI usará algoritmo RRF por padrão para multiplexar os resultados de retirada de banco de dados vetorial e recuperação de palavras-chave.
Gerar o que é
O quadro tem Langchain e LlamaIndex
Regime da tecnologia de contagem e colheita
A estrutura da imagem
A dificuldade é: o que é texto - para - SQL?
Repartição do texto:
Repartição de texto: o documento está dividido em blocos mais pequenos para facilitar a incorporação de textos subsequentes e, em seguida, facilitar a posterior recuperação do documento.
Idealmente: Juntar peças de texto relacionadas semânticamente por ordem.
*** Método de divisão ***
- De acordo com a regra: (a forma mais fácil) dividir o documento por frase. O documento é dividido de acordo com os símbolos de terminação comuns em chinês e inglês, como quebra-caracteres simples, elipse chinesa e inglesa, aspas duplas e assim por diante.
- Com base na semântica: 1 . 1 . Em primeiro lugar, o documento está dividido em frase - blocos de documentos de nível baseados em regras. 2 . 2 . Então use o modelo para integrar os blocos de documentos baseados na semântica, e finalmente obter os blocos de documento baseados na semântica.
** Modelo de divisão de texto baseado em semântica **
O SEQ_Model**, modelo desenvolvido pelo Ali Dama Institute é baseado na janela de deslizamento Bert+, que determina a segmentação semântica ao prever se a sentença dividida pertence ao limite do parágrafo.
Vectorização de texto: seleccionar o modelo embutido
Modelo de Zhiyuan BBA (BGE - base - modelo zh) ou escolha do exemplo MTEB.
Armazenamento de vectores
-
Faiss: para uso pessoal
-
Milvus: nível de produção
Usa o vector para recuperar pontos de conhecimento correspondentes de acordo com as perguntas.
Top_ k Op_ k
Faiss: Faça uma pesquisa extendida perto dos resultados da pesquisa para obter documentos semelhantes que sejam inferiores ao chunk_ size (normalmente 500 palavras)
Milvus: TOPK Retrieval + BGE - base - zh + Parágrafo Modelo de Agregação de Similitude
IDEA: Analisar a ideia de recuperação alargada baseada na recuperação TOPK, descobrimos que é principalmente através da expansão de segmentos semânticos para fazer com que o grande modelo obtenha o máximo de informação útil possível para melhorar o efeito da resposta.
O comboio do pensamento:
- Em primeiro lugar, o documento está dividido em frase - blocos de documentos de nível baseados em regras.
- Então use o modelo para integrar os blocos de documentos baseados na semântica, e finalmente obter os blocos de documento baseados na semântica.
- Em terceiro lugar, o modelo de incorporação de texto é usado para os documentos sequencialmente, e os documentos são agregados novamente de acordo com a similaridade semântica, que é equivalente à agregação da sentença original - documentos de nível duas vezes com métodos diferentes.
Compilar a linha de comandos
你现在是一个智能助手了,现在需要你根据已知内容回答问题
已知内容如下:
"{context}"
通过对已知内容进行总结并且列举的方式来回答问题:"{question}",在答案中不能出现问题内容,并且不允许编造内容,并且使用简体中文回答。
如果该问题和已知内容不相关,请回答 "根据已知信息无法回答该问题" 或 "没有提供足够的相关信息"。
Gerar a Resposta: Seleccione o LLM
ESQUEMA DE ENSAIO
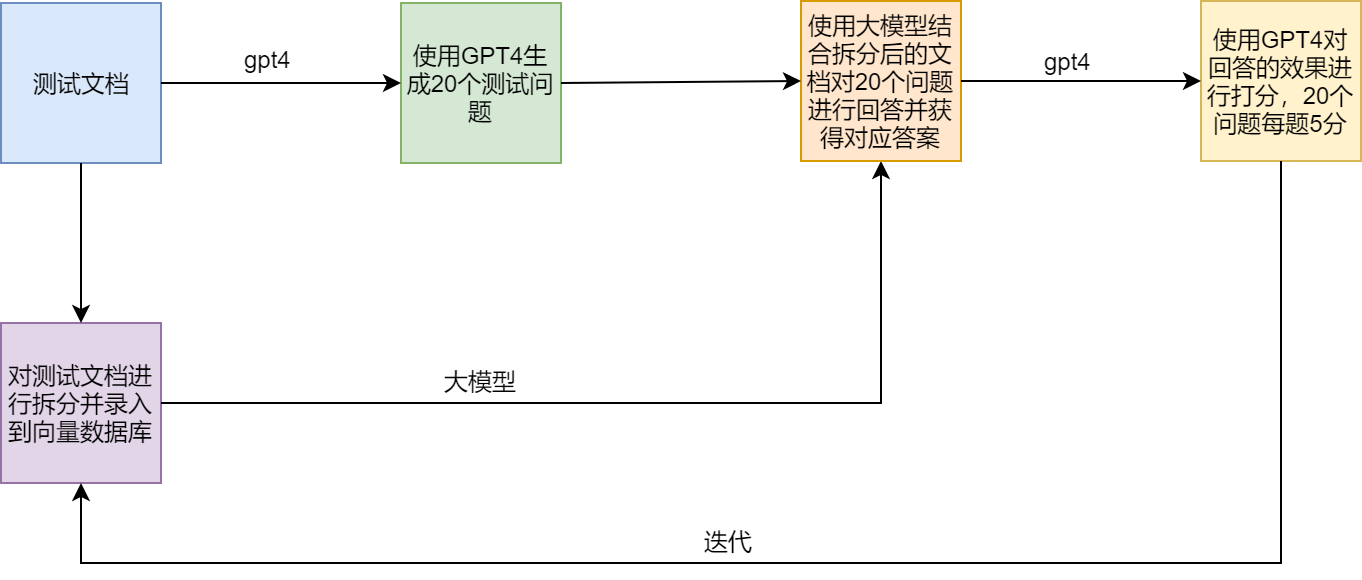
Pontos de dor e soluções das OAR

Exemplos
LamaIndex官方提供了一个范例(SEC Insights),用来展示高级查询技术