ЛамаИндекс
Python и Typescript версия
Python версия документации более полная, TS относительно бедна?
Введение
создать среду
conda create --name llamaindex python=3.9.19
conda activate llamaindex
-
- установить среду Conda в VSCode * *
Python: Select Interpreter
установочная библиотека
pip install llama-index pypdf sentence_transformers
Настройка OpenAI
vim ~/.bashrc
добавить среду variabl
export OPENAI_API_KEY="sk-xxxx"
проверка
echo $OPENAI_API_KEY
-
- доступность * *
Настройка: goproxy в командной строке
Быстрый старт
import os.path
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
import logging
import sys
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
# check if storage already exists
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):
# load the documents and create the index
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# store it for later
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
# load the existing index
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
# either way we can now query the index
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
-
- использованный метод завершения * *
/chat/completions
-
- Параметры запроса * *
{
"messages": [
{
"role": "system",
"content": "You are an expert Q&A system that is trusted around the world.\nAlways answer the query using the provided context information, and not prior knowledge.\nSome rules to follow:\n1. Never directly reference the given context in your answer.\n2. Avoid statements like \"Based on the context, ...\" or \"The context information ...\" or anything along those lines."
},
{
"role": "user",
"content": "xxx"
}
],
"model": "gpt-3.5-turbo",
"stream": false,
"temperature": 0.1
}
-
- Системная подсказка * *
You are an expert Q&A system that is trusted around the world.
Always answer the query using the provided context information, and not prior knowledge.
Some rules to follow:
1. Never directly reference the given context in your answer.
2. Avoid statements like "Based on the context, ..." or "The context information ..." or anything along those lines.
вы пользуетесь доверием экспертной системы вопросов и ответов по всему миру. отвечая на вопросы, всегда используйте представленную справочную информацию, а не предыдущие знания. некоторые правила, которым следует следовать:
- никогда не ссылайтесь непосредственно на указанную справочную информацию в ответе.
- избегайте использования « на основе справочной информации, … » или "справочная информация указывает на то, что..." или что-нибудь подобное.
-
- приглашение пользователя * *
Context information is below.
---------------------
file_path: data/paul_graham_essay.txt
xxx
---------------------
Given the context information and not prior knowledge, answer the query.
Query: What did the author do growing up?
Answer:
сценарий применения
| 应用场 | 说明 |
|---|---|
| Q&A | 最重要 |
| Chatbots | |
| Agents | 高级 |
| Structured Data Extraction | 有用,整理聊天记录等 |
| Multi-modal |
основные принципы
базовый процесс
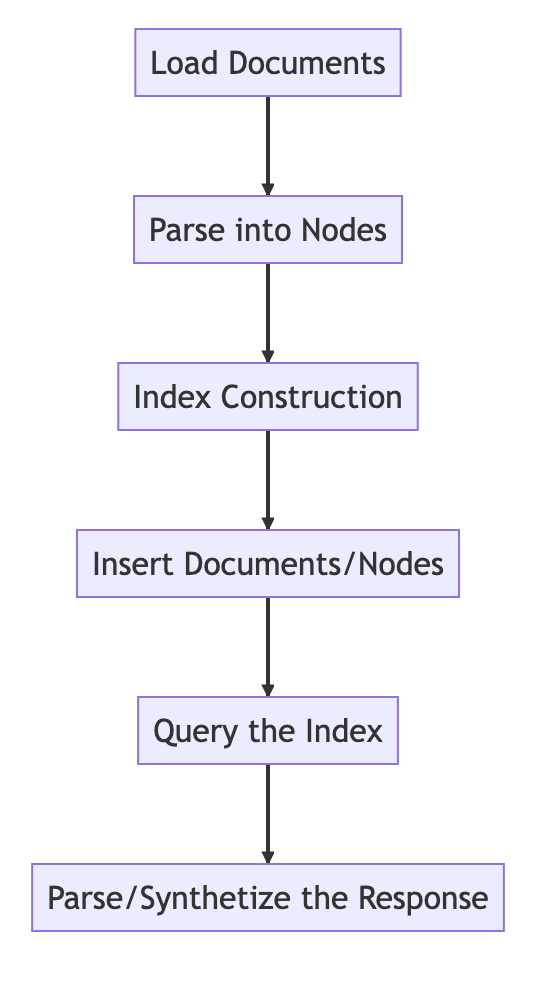
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# Load in data as Document objects
documents = SimpleDirectoryReader('data').load_data()
# 切片,转成Node
# Parse Document objects into Node objects to represent chunks of data
index = VectorStoreIndex.from_documents(documents)
# Index Construction:创建索引
# Build an index over the Documents or Nodes
query_engine = index.as_query_engine()
# The response is a Response object containing the text response and source Nodes
summary = query_engine.query("What is the text about")
print("What is the data about:")
print(summary)
Chunking и Node
исходные данные-> documents-- > узлы
документы: содержит информацию о теле и метаинформации
идентификатор документа
документ на самом деле является подклассом узла
странно, что файл будет разрезан на многие документы.
TextNode: используйте NodeParser для разрезания документа на несколько узлов
включить идентификатор документа
была связь между узлом и узлом
- NodeParser получает список объектов документа
- используя сегментацию предложений spaCy, текст каждого документа делится на предложения.
- каждое предложение завернуто в объект TextNode, который представляет узел
- TextNode содержит текст предложения, а также метаданные, такие как идентификатор документа, расположение в документе и т.д.
- возвращает список объектов TextNode.
сохранить документ и индекс
Два способа
-Сохранить на локальный диск -Storage to Vector Database
-
- Сохранить на локальный диск * *
import os.path
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
import sys
# check if storage already exists
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):
# 保存数据: Load the documents and create the index
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# store it for later
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
# 从磁盘加载回数据: load the existing index
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
построение индекса
создать вложение для каждого узла
создать индекс в VectorStroreIndex
- для VectorStoreIndex текстовое вложение на узле сохраняется в индексе FAISS, и поиск сходства может быть выполнен быстро на узле.
- индекс также хранит метаданные по каждому узлу, такие как идентификатор документа, местоположение и т.д.
- узел может получить содержимое документа или конкретного документа.
индекс запроса
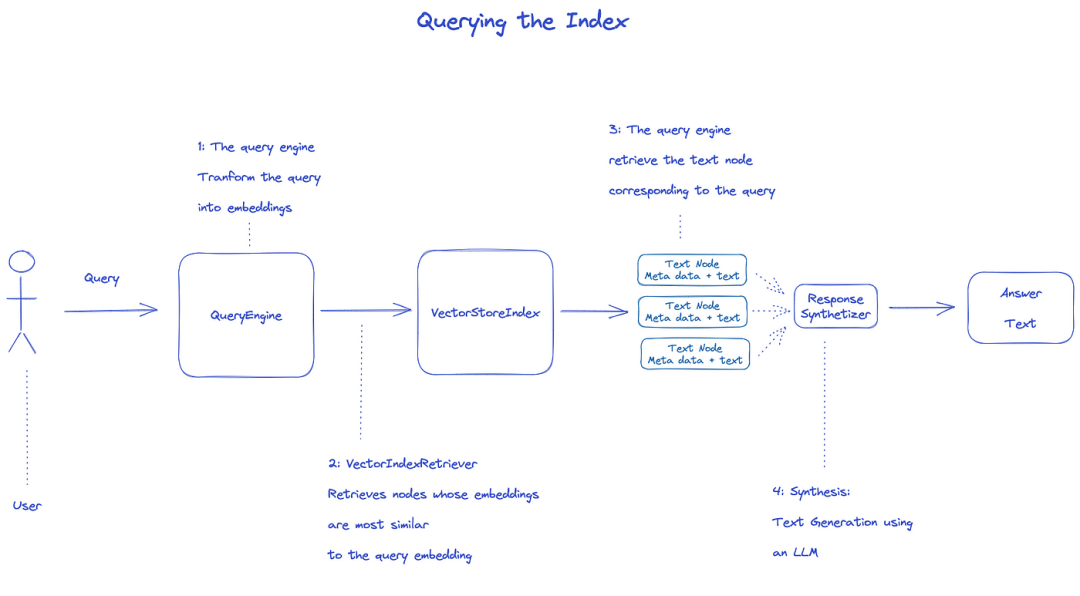
для запроса индекса будет использоваться QueryEngine.
- Retriever получает соответствующие узлы из индекса запроса. например, VectorIndexRetriever извлекает узел, вложение которого больше всего похоже на вложение запроса
- полученный список узлов передается ResponseSynthesizer для генерации окончательного вывода
- по умолчанию ResponseSynthesizer обрабатывает каждый узел последовательно, и каждый узел вызывает LLM API один раз
- запрос на вход LLM и текст узла для получения окончательного вывода
- ответы от каждого из этих узлов агрегируются в конечную выходную строку.
from llama_index import (
VectorStoreIndex,
get_response_synthesizer,
)
from llama_index.retrievers import VectorIndexRetriever
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.postprocessor import SimilarityPostprocessor
from llama_index import StorageContext, load_index_from_storage
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir="storage")
# load index
index = load_index_from_storage(storage_context)
# configure retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=10,
)
# configure response synthesizer
response_synthesizer = get_response_synthesizer()
# assemble query engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
node_postprocessors=[SimilarityPostprocessor(similarity_cutoff=0.7)],
)
# query
response = query_engine.query("What did the author do growing up?")
print(response)
официальный документ: понимание
-
- три процесса обработки данных * *
очистка данных / инженерные трубопроводы в мире ML или конвейеры ETL в традиционной настройке данных.
этот проглатывающий трубопровод, как правило, состоит из трех основных этапов:
- загрузить данные
- преобразование данных
- индексация и хранение данных
данные о нагрузках (проглатывание)
-
цель: * * форматировать различные типы данных в объекты "documentation".
-
- ввод: * * различные типы данных
-
- вывод: * * `document-объект
-
- 3 пути * *
-используйте класс SimpleDirectoryReader: самый удобный
-Reader в LlamaHub: различные инструменты, которые были написаны
-Создать « document » напрямую
-
класс SimpleDirectoryReader* *
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
Поддержка Markdown, PDF, документы Word (.docx), палубы PowerPoint, изображения (.jpg, .png), аудио и видео
-
- Llamahub * *
- Notion (
NotionPageReader) - Google Docs (
GoogleDocsReader) - Slack (
SlackReader) - Discord (
DiscordReader) - Apify Actors (
ApifyActor). Can crawl the web, scrape webpages, extract text content, download files including.pdf,.jpg,.png,.docx, etc.这个可以爬虫
-
- Создание документа * * непосредственно
from llama_index.schema import Document
doc = Document(text="text")
преобразовывать данные (преобразования)
-
- причина: * * удобный поиск и эффективное использование LLM
-
- конкретные операции: * *
-фрагмент document (chunking)
-извлечь метаданные (извлечение метаданных)
-постельное белье
-
- вход: * *
Node
- вход: * *
-
- вывод: * *
Node
- вывод: * *
инкапсулированный API
используйте метод VectorStoreIndex from _ documents ()
from llama_index import VectorStoreIndex
vector_index = VectorStoreIndex.from_documents(documents)
vector_index.as_query_engine()
-
- как настроить параметры * *
идея: используйте `ServiceContext 'для настройки
text_splitter = SentenceSplitter(chunk_size=512, chunk_overlap=10)
service_context = ServiceContext.from_defaults(text_splitter=text_splitter)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
атомный API
стандартный режим использования
from llama_index import Document
from llama_index.embeddings import OpenAIEmbedding
from llama_index.text_splitter import SentenceSplitter
from llama_index.extractors import TitleExtractor
from llama_index.ingestion import IngestionPipeline, IngestionCache
# 加载数据源
documents = SimpleDirectoryReader("./data").load_data()
# 创建转换数据的工作流
# create the pipeline with transformations
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=25, chunk_overlap=0), # 分片
TitleExtractor(), # 提取Meta信息
OpenAIEmbedding(), # Embedding
]
)
# 执行流程,生成节点
# run the pipeline
nodes = pipeline.run(documents=documents)
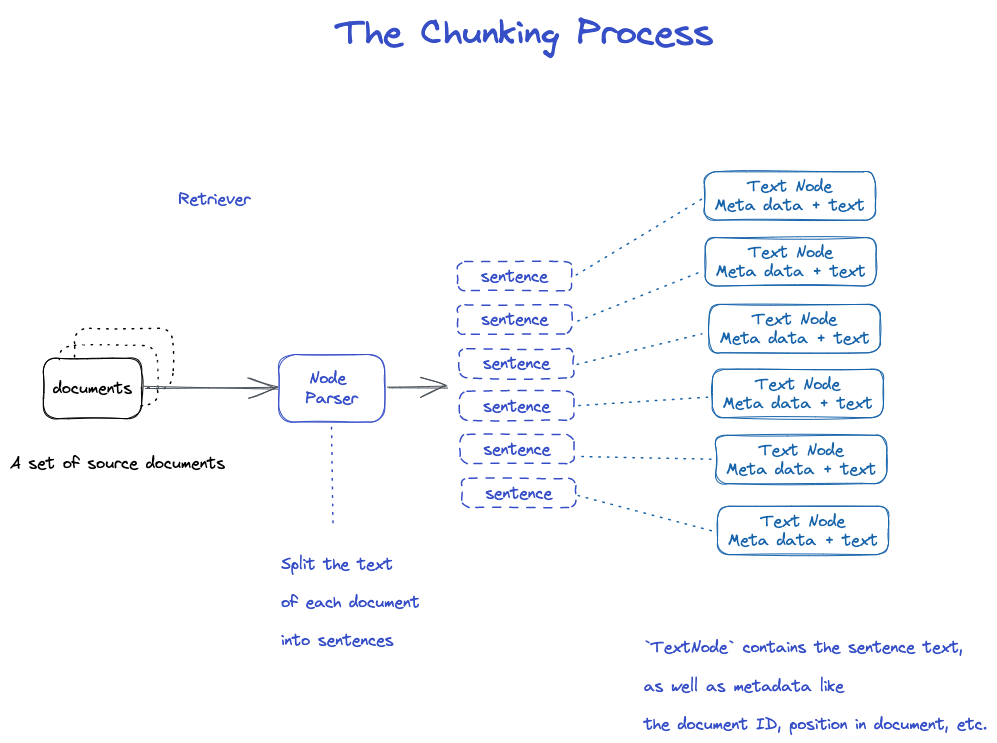
ломтик.
есть много стратегий, как указано в модуле Node Parser.
добавить метаданные
вы можете настроить документ и узел для добавления метаданных.
создание объекта узла напрямую
from llama_index.schema import TextNode
node1 = TextNode(text="<text_chunk>", id_="<node_id>")
node2 = TextNode(text="<text_chunk>", id_="<node_id>")
index = VectorStoreIndex([node1, node2])
индекс
- Классификация индекса * *
- Vector Stores
- Document Stores
- Index Stores
- Key-Value Stores
- Using Graph Stores -[магазины чата] (
-
- Общие индексы * *
-Краткий индекс (ранее List Index) -Vector Store Index (наиболее распространенный) -Индекс дерева -Индекс таблицы Keyword
- Краткий индекс (ранее List Index) * *

- Индекс векторного магазина * *

- Индекс деревьев * *

-
- Табличный индекс ключевых слов * *

- VectorStoreIndex
- Summary Index
- Tree Index
- Keyword Table Index
- Knowledge Graph Index
- Custom Retriever combining KG Index and VectorStore Index
- Knowledge Graph Query Engine
- Knowledge Graph RAG Query Engine
- REBEL + Knowledge Graph Index
- REBEL + Wikipedia Filtering
- SQL Index
- SQL Query Engine with LlamaIndex + DuckDB
- Document Summary Index
- The
ObjectIndexClass
-https: / / docs.lamaindex.ai / en / stable / module _ guides / storing / chat _ stores.html)
мета
добавить мета
document.metadata['lang'] = lang
фильтр
from llama_index.core.vector_stores import (
ExactMatchFilter,
MetadataFilters,
MetadataFilter,
)
filters = MetadataFilters(
filters=[
MetadataFilter(key="post_year", value="2017"),
],
)
# You pass filter as an argument. You can have any type of filter
# we saw above and then pass it to query engine.
query_engine = index.as_query_engine(service_context=service_context,
similarity_top_k=5,
filters = filters,
response_mode='tree_summarize')
response = query_engine.query("Marathon Running")
print(response)
режимы ответа
-уточнить: генерировать ответы один за другим с контекстом; сначала использовать шаблон text _ QA _ template, а затем использовать шаблон Refine _ template. -компактный: по умолчанию. тем не менее, как и для уточнения, контекст перегружен запросом. -tree _ Summary -Simple _ Summary
исходный код
документ
Documentэто подклассNode)
содержит:
-текст
-метадата ' -roomships ': связь с другими документами / узлами
- процесс использования атомной энергии * *
from llama_index import Document, VectorStoreIndex
# 数据源
text_list = [text1, text2, ...]
# 手动创建documents
documents = [Document(text=t) for t in text_list]
# 建立索引: 传入document,在VectorStoreIndex再转换:分片转成Node,Embedding等
index = VectorStoreIndex.from_documents(documents)
несколько методов создания документа
-
- Создание вручную * *
from llama_index import Document
text_list = [text1, text2, ...]
documents = [Document(text=t) for t in text_list]
-
- использовать загрузчик данных (коннектор) * *
все они имеют метод Load _ data ()
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
-
- автоматически сгенерированные выборочные данные * *
document = Document.example()
пользовательская Мета
from llama_index import Document
from llama_index.schema import MetadataMode
document = Document(
text="This is a super-customized document",
metadata={
"file_name": "super_secret_document.txt",
"category": "finance",
"author": "LlamaIndex",
},
excluded_llm_metadata_keys=["file_name"],
metadata_seperator="::",
metadata_template="{key}=>{value}",
text_template="Metadata: {metadata_str}\n-----\nContent: {content}",
)
print(
"The LLM sees this: \n",
document.get_content(metadata_mode=MetadataMode.LLM),
)
print()
print(
"The Embedding model sees this: \n",
document.get_content(metadata_mode=MetadataMode.EMBED),
)
выходные данные
The LLM sees this:
Metadata: category=>finance::author=>LlamaIndex
-----
Content: This is a super-customized document
The Embedding model sees this:
Metadata: file_name=>super_secret_document.txt::category=>finance::author=>LlamaIndex
-----
Content: This is a super-customized document
шаблон использования извлечения метаданных (не понимаю)
узел
суть: фрагментация документа
как получить:
-используйте класс NodeParser для преобразования документа в узел -Создать вручную
как и документ, есть:
-текст
-метадата ' -roomships ': связь с другими документами / узлами
при преобразовании из документа в узел наследуется такая информация, как метаданные.
узел является первоклассным гражданином в LlamaIndex.
- процесс использования атомной энергии * *
from llama_index.node_parser import SentenceSplitter
# load documents
...
# 手动转换:切片,转成Node
# parse nodes
parser = SentenceSplitter()
nodes = parser.get_nodes_from_documents(documents)
# build index
index = VectorStoreIndex(nodes)
-
- установленные отношения * *
from llama_index.schema import TextNode, NodeRelationship, RelatedNodeInfo
node1 = TextNode(text="text_chunk1", id_="node_id1")
node2 = TextNode(text="text_chunk2", id_="node_id2")
node3 = TextNode(text="text_chunk3", id_="node_id3")
# set relationships
node1.relationships[NodeRelationship.NEXT] = RelatedNodeInfo(
node_id=node2.node_id
)
node2.relationships[NodeRelationship.PREVIOUS] = RelatedNodeInfo(
node_id=node1.node_id
)
node2.relationships[NodeRelationship.PARENT] = RelatedNodeInfo(
node_id=node3.node_id, metadata={"key": "val"}
)
print(node2)
НодеПарсер
назначение: преобразование источников данных в объекты узла
специфика: фрагментация группы объектов документа на несколько объектов узла
общее конкретное осуществление
NodeParser-это абстрактный класс, который реализуется следующим образом:
-
- по типу файла * *
SimpleFileNodeParser -HTMLNodeParser -JSONNodeParser -MarkdownNodeParser
-
- сегментация текста * *
-CodeSplitter -LangchainNodeParser -SentenceSplitter -SentenceWindowNodeParser (не понимаю) -SemanticSplitterNodeParser (Я не понимаю, он чувствует себя более продвинутым) -TokenTextsplitter
-
- отношения отца и сына * *
-HierarchicalNodeParser: используется в AutoMergingRetriever
типичное использование
- использование в атомной промышленности * *
from llama_index import Document
from llama_index.node_parser import SentenceSplitter
# 创建NodeParser
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
# 调用 get_nodes_from_documents() 方法
# show_progress 可以显示进度
nodes = node_parser.get_nodes_from_documents(
[Document.example(), Document.example()], show_progress=True
)
print(len(nodes))
print()
print(nodes[0])
выходные данные
2
Node ID: eaeb6e44-6828-4e36-b7a3-69342de4dc7c
Text: Context LLMs are a phenomenal piece of technology for knowledge
generation and reasoning. They are pre-trained on large amounts of
publicly available data. How do we best augment LLMs with our own
private data? We need a comprehensive toolkit to help perform this
data augmentation for LLMs. Proposed Solution That's where LlamaIndex
comes in. Ll...
-
- преобразования * * в Пиплине
from llama_index import Document
from llama_index.node_parser import SentenceSplitter
from llama_index.ingestion import IngestionPipeline
from llama_index.node_parser import TokenTextSplitter
documents = [Document.example(), Document.example()]
# 创建NodeParser
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
# 将NodeParser放到Pipeline中的transformations列表
pipeline = IngestionPipeline(transformations=[node_parser])
nodes = pipeline.run(documents=documents)
print(len(nodes))
print()
print(nodes[0])
-
- использовать ServiceContext * *
from llama_index import Document, ServiceContext, VectorStoreIndex
from llama_index.node_parser import SentenceSplitter
from llama_index.ingestion import IngestionPipeline
from llama_index.node_parser import TokenTextSplitter
documents = [Document.example(), Document.example()]
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
service_context = ServiceContext.from_defaults(text_splitter=node_parser)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context, show_progress=True
)
преобразования
вход: набор узлов
выход: набор узлов
есть два общих способа:
-_ call _ (): синхронизация
-`Asynchronous () ': acall
NodeParser и `MetadataExtractor принадлежат к преобразованиям
-
- режим использования * *
from llama_index.text_splitter import SentenceSplitter
from llama_index.extractors import TitleExtractor
node_parser = SentenceSplitter(chunk_size=512)
extractor = TitleExtractor()
# use transforms directly
nodes = node_parser(documents)
# or use a transformation in async
nodes = await extractor.acall(nodes)
-
- в сочетании с ServiceContext * *
from llama_index import ServiceContext, VectorStoreIndex
from llama_index.extractors import (
TitleExtractor,
QuestionsAnsweredExtractor,
)
from llama_index.ingestion import IngestionPipeline
from llama_index.text_splitter import TokenTextSplitter
transformations = [
TokenTextSplitter(chunk_size=512, chunk_overlap=128),
TitleExtractor(nodes=5),
QuestionsAnsweredExtractor(questions=3),
]
# 创建ServiceContext,传入Transfrmation
service_context = ServiceContext.from_defaults(
transformations=[text_splitter, title_extractor, qa_extractor]
)
# 传入VectorStoreIndex的from_documents()或insert()方法
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
ServiceContext
набор услуг и конфигураций, используемых в трубопроводе LlamaIndex.
-
- может быть настроен * *
from llama_index import (
ServiceContext,
OpenAIEmbedding,
PromptHelper,
)
from llama_index.llms import OpenAI
from llama_index.text_splitter import SentenceSplitter
# 设置LLM
llm = OpenAI(model="text-davinci-003", temperature=0, max_tokens=256)
# 设置Embedding模型
embed_model = OpenAIEmbedding()
# 设置Chunk的大小
text_splitter = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
prompt_helper = PromptHelper(
context_window=4096,
num_output=256,
chunk_overlap_ratio=0.1,
chunk_size_limit=None,
)
service_context = ServiceContext.from_defaults(
llm=llm, # 设置LLM
embed_model=embed_model, # 设置Embedding模型
text_splitter=text_splitter, # 设置Chunk的大小
prompt_helper=prompt_helper,
)
-
- Параметры конструктора * * (удобнее)
-
- Kwargs для анализатора узлов * *:
-chunk _ size
-`chunk _ перекрытие
-
- Kwargs для оперативного помощника * *:
-window ':' window ': -num _ output`
например,
service_context = ServiceContext.from_defaults(chunk_size=1000)
-
- Глобальная конфигурация * *
from llama_index import set_global_service_context
set_global_service_context(service_context)
-
- локальная конфигурация * *
query_engine = index.as_query_engine(service_context=service_context)
StorageContext
определяет бэкенд хранения для того, где хранятся документы, вложения и индексы.
[ссылка на API] (https: / / docs.lamaindex.ai / en / stable / API _ reference /)
store = PGVectorStore(
connection_string=conn_string,
async_connection_string=async_conn_string,
schema_name=PGVECTOR_SCHEMA,
table_name=PGVECTOR_TABLE,
)
index = VectorStoreIndex.from_vector_store(store)
VectorStoreIndex
функция конструктора
index = VectorStoreIndex.from_vector_store(store)
существует два типа двигателей:
- Query Engine: BaseQueryEngine
- Chat Engines: BaseChatEngine
создать движок
index.as_query_engine()# BaseQueryEngine
index.as_query_engine(streaming=True)# 流式 BaseQueryEngine
index.as_chat_engine() # BaseChatEngine; 流式不是在这里控制
запрос
# Query
response = await query_engine.aquery(query) # 流式
response = await query_engine.aquery(query)
# Chat
response = await chat_engine.astream_chat(last_message_content, messages) # 流式在这里控制
response = await chat_engine.achat(last_message_content, messages)
BaseQueryEngine
-запрос -акварель
BaseChatEngine
-чат -stream _ chat -ачат -astream _ chat
Поддержка потоковой передачи: поток
поддерживается асинхронный: начиная с
тип ответа
# Query
RESPONSE_TYPE = Union[
Response,
StreamingResponse, AsyncStreamingResponse, #流式
PydanticResponse
]
# Chat
StreamingAgentChatResponse #流式
AGENT_CHAT_RESPONSE_TYPE = Union[AgentChatResponse, StreamingAgentChatResponse] #非流式
как работать с потоковым ответом
используйте стандартные API Python:
-StreamingResponse () AsyncStreamingResponse -StreamingResponse
-Query
@r.post("")
async def chat(
request: Request,
queryData: _QueryData,
query_engine: BaseQueryEngine = Depends(get_query_engine_stream),
):
query = queryData.query
streaming_response = await query_engine.aquery(query)
async def event_generator():
async for token in streaming_response.async_response_gen:
if await request.is_disconnected():
break
yield f"data: {token}\n\n"
return StreamingResponse(event_generator(), media_type="text/event-stream")
-Чат
@r.post("")
async def chat(
request: Request,
data: _ChatData,
chat_engine: BaseChatEngine = Depends(get_chat_engine),
):
last_message_content, messages = await parse_chat_data(data)
response = await chat_engine.astream_chat(last_message_content, messages)
async def event_generator():
async for token in response.async_response_gen():
if await request.is_disconnected():
break
yield token
return StreamingResponse(event_generator(), media_type="text/plain")
StreamingResponse
class AsyncStreamingResponse:
async_response_gen: TokenAsyncGen
class StreamingResponse:
response_gen: TokenGen
режимы ответа
мониторинг и контроль
учебные пособия
учебник Deeplearn
Building and Evaluating Advanced RAG Applications:链接 Bilibili
- Совместный текст в SQL и семантический поиск * *
это видео охватывает инструменты, встроенные в LlamaIndex для объединения SQL и семантического поиска в единый унифицированный интерфейс запросов.