RAG:检索增强生成
RAG
тряпка: извлечение дополненного поколения
вы пытаетесь решить сложный случай:
роль детектива заключается в сборе улик, доказательств и исторических записей, связанных с делом. после того, как детектив собрал информацию, репортер подытожил факты в увлекательную историю и представил связное повествование.
проблема с LLM
- галлюцинация: предоставление ложной информации без ответа.
- LLM использует устаревшую информацию и не имеет доступа к последней и надежной информации после истечения срока знания.
- кроме того, ответ, предоставленный LLM, не относится к его источнику, что означает, что его утверждение не может быть проверено пользователем как точное или полностью доверенное. это подчеркивает важность независимой проверки и оценки при использовании информации, генерируемой искусственным интеллектом.
您可以将大型语言模型看作是一个过于热情的新员工,他拒绝随时了解时事,但总是会绝对自信地回答每一个问题。
тряпка является одним из способов решения некоторых из этих проблем. он перенаправляет LLM на получение соответствующей информации из авторитетных, заранее определенных источников знаний. Организации имеют больший контроль над генерируемым текстовым выводом, и пользователи могут узнать больше о том, как LLM генерирует ответы.
процесс LLM
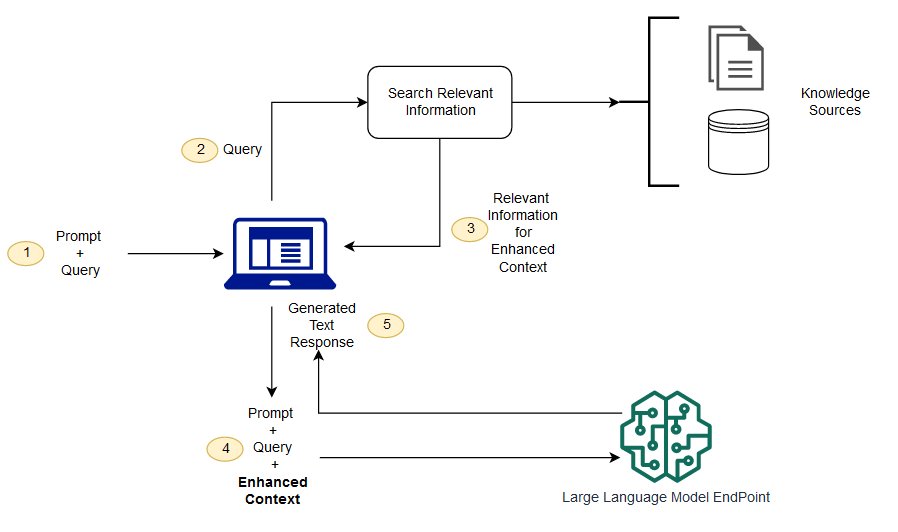
(я не понимаю) в чем разница между генерацией улучшения поиска и семантическим поиском?
семантический поиск может улучшить результаты тряпок для организаций, которые хотят добавить большое количество внешних источников знаний в свои приложения LLM. современные предприятия хранят большой объем информации в различных системах, таких как руководства, часто задаваемые вопросы, отчеты об исследованиях, руководства по обслуживанию клиентов и хранилища документов по людским ресурсам. контекстное извлечение является сложным по масштабу и, следовательно, ухудшает качество генерируемых результатов.
технология семантического поиска: вы можете сканировать большие базы данных, содержащие различную информацию, и получать данные более точно. например, они могут ответить на такие вопросы, как * « сколько вы потратили на механическое обслуживание в прошлом году? » такие вопросы, как * путем привязки вопроса к соответствующему документу и возвращения конкретного текста вместо результатов поиска. затем разработчики могут использовать этот ответ, чтобы предоставить больше контекста для LLM.
традиционные решения поиска по ключевым словам в тряпке дают ограниченные результаты для наукоемких задач. разработчикам также приходится иметь дело с вложением слов, фрагментацией документов и другими сложными вопросами при подготовке данных вручную. в отличие от этого, технология семантического поиска может выполнять всю работу, к которой подготовлена база знаний, поэтому разработчикам это не нужно. они также генерируют семантически связанные пункты и слова разметки, отсортированные по релевантности, чтобы максимизировать качество полезной нагрузки тряпки.
три ключевых компонента тряпки
расширенная модель генерации состоит в основном из трех ключевых компонентов:
- Retriever: отвечает за поиск соответствующей информации из внешних источников знаний.
- Сортер (Ranker): оценивает и приоритизирует результаты поиска.
- генератор: используйте результаты поиска и сортировки в сочетании с вводом пользователя, чтобы генерировать окончательный ответ или содержание.
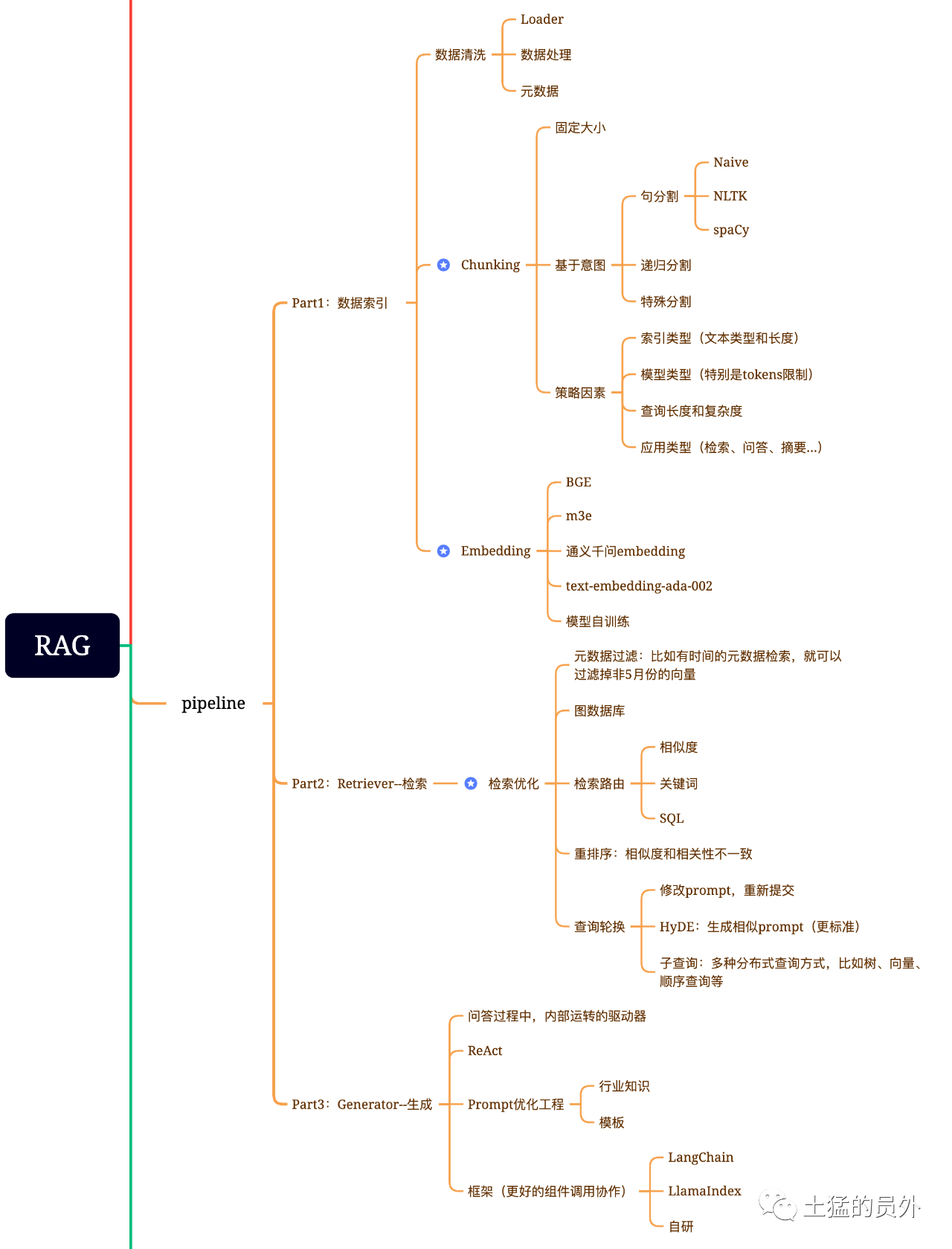
карта мозга тряпки
эта картина очень детализирована!
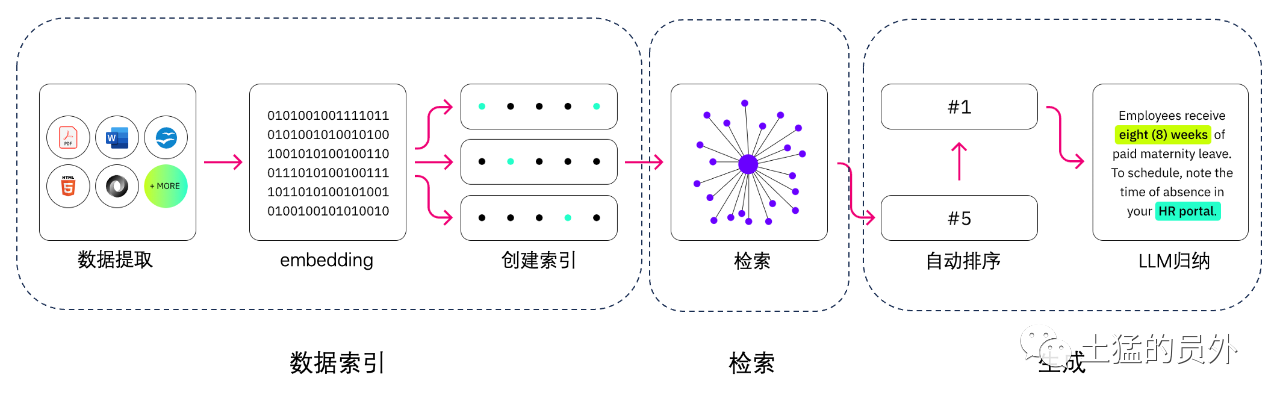
индексация данных
-* * извлечение данных * *
очистка данных: включая загрузчик данных, извлечение PDF, Word, разметки, базы данных и API и т.д. -Обработка данных: включая обработку формата данных, устранение неидентифицируемого контента, сжатие и форматирование и т.д. -извлечение метаданных: крайне важно извлечь имя файла, время, название главы, альт изображения и другую информацию.
инструменты для извлечения данных
-UnstructuredIO (используется) -LlamaParse (используется) -Google Document AI экстракт AWS -pdf2image + pytesseract
поиск
оптимизация поиска, как правило, разделена на следующие пять частей:
-* * Фильтрация метаданных * *: когда мы разделим индекс на много кусков, эффективность поиска будет проблемой. в настоящее время, если метаданные могут быть отфильтрованы в первую очередь, эффективность и актуальность будут значительно повышены. например, мы спрашиваем: « помогите мне разобраться во всех контрактах в XX отделе в мае этого года, которые включают в себя покупку XX оборудования? » да. в это время, если есть метаданные, мы можем искать соответствующие данные « * * XX Department + May 2023 * * », и объем поиска может сразу составить 1 / 10 000 от общей ситуации.
-* * извлечение отношения графа * *: если вы можете превратить многие сущности в узел, а отношения между ними в отношения, вы можете использовать связь между знаниями, чтобы сделать более точные ответы. особенно для некоторых многоходовых задач, использование индекса данных графа сделает поиск более актуальным.
-* * технология поиска * *: выше упомянуты некоторые методы предварительной обработки, и основные методы поиска являются следующими:
-
- 相似度检索:前面我已经写过那篇文章《大模型应用中大部分人真正需要去关心的核心——Embedding》中有提到六种相似度算法,包括欧氏距离、曼哈顿距离、余弦等,后面我还会再专门写一篇这方面的文章,可以关注我,yeah; -* * поиск по ключевым словам * : это очень традиционный метод поиска, но иногда это также очень важно. фильтрация метаданных, о которой мы только что говорили, это один вид, а другой заключается в том, чтобы сначала составить резюме куска, а затем найти возможный соответствующий кусок через поиск ключевых слов, чтобы повысить эффективность поиска. говорят, что Клауде.ай сделал то же самое. - * SQL Search * *: это более традиционный поиск, но для некоторых локализованных корпоративных приложений SQL Query является важным шагом. например, данные о продажах, о которых я говорил ранее, должны быть сначала найдены SQL. Other: все еще есть много методов поиска, поэтому давайте поговорим об этом позже.
-* * Rerank * *: во многих случаях наши результаты поиска не идеальны, потому что в системе есть большое количество кусков, и размеры, которые мы извлекаем, не обязательно являются оптимальными, и результаты одного поиска могут быть не столь идеальными с точки зрения актуальности. в это время нам нужно иметь некоторые стратегии, чтобы переупорядочить результаты поиска, такие как использование planB для перезаказа, или скорректировать совокупную релевантность, соответствие и другие факторы, чтобы получить рейтинг, который больше соответствует нашему бизнес-сценарию. потому что после этого шага мы отправим результат в LLM для окончательной обработки, поэтому результат этой части очень важен. кроме того, будет внутренний судья, который рассмотрит корреляцию и вызовет изменение порядка.
-* * ротация запросов * *: это способ запроса и поиска, и обычно существует несколько способов:
-* * Подзапрос: * * Вы можете использовать различные стратегии запроса в различных сценариях. например, вы можете использовать Querier, предоставляемый такими фреймворками, как LlamaIndex, запрос дерева (из листовых узлов, шаг за шагом, слияние), векторный запрос или самый примитивный последовательный запрос и т.д. * *; *
-* * Hyde: * * это способ копирования заданий для создания похожих или более стандартных шаблонов запросов. * *
переранг
большинство векторных баз данных жертвуют определенной степенью точности для вычислительной эффективности. это делает результаты поиска случайными, и оригинальная возвращенная вершина K не обязательно является наиболее актуальной.
使用BAAI/bge-reranker-base、BAAI/bge-reranker-large等开源模型来完成Re-Rank操作。
а база NetEase поддерживает Китай, Великобританию, Японию и Южную Корею.
отзыв / смешанное извлечение
двусторонний запрос:
-семантический поиск (векторный поиск) / * отзыв векторной базы данных * * -Поиск по ключевым словам (поиск по ключевым словам) / Поиск по ключевым словам
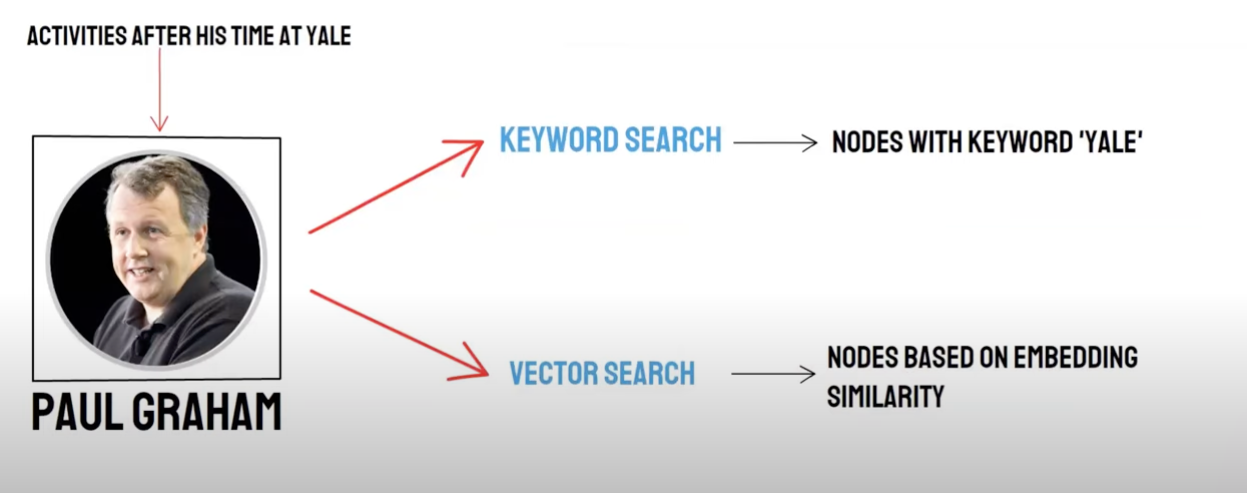
отзыв векторных баз данных и отзыв ключевых слов имеют свои преимущества и недостатки, поэтому сочетание результатов отзыва может повысить общую точность и эффективность поиска. алгоритм взаимного сортировки Fusion (Reciprocal Rank Fusion, RRF) вычисляет общий балл после слияния взвешенным суммированием ранжирования каждого документа в различных методах отзыва.
когда вы решите использовать отзыв поиска ключевых слов, то есть * * поиск ключевых слов * * выберите * * ансамбль ключевых слов * *, PAI будет использовать алгоритм RRF по умолчанию для мультиплексирования результатов отзыва векторной базы данных и поиска ключевых слов.
генерировать
фреймворк имеет Langchain и LlamaIndex
схема технологии подсчета и сбора урожая
рамка
сложность в том, что такое texto-sql?
разделение текста:
разделение текста: документ разделяется на более мелкие блоки, чтобы облегчить последующее вложение текста, а затем облегчить последующий поиск документа.
в идеале: поместите семантически связанные части текста в порядок.
- метод разделения * *
-в соответствии с правилом: (самый простой способ) разделить документ по предложениям. документ разделен в соответствии с общими символами окончания на китайском и английском языках, такими как однозначный брекер, китайский и английский эллипсы, двойные кавычки и так далее. на основе семантики:
- Во-первых, документ разделен на блоки документов на уровне предложения на основе правил.
- затем используйте модель, чтобы интегрировать блоки документов, основанные на семантике, и, наконец, получить блоки документов, основанные на семантике.
модель разделения текста на основе семантики * *
модель seq _ model * *, разработанная Институтом Али Дамы, основана на раздвижном окне BERT +, которое определяет семантическую сегментацию, предсказывая, принадлежит ли разделенное предложение границе параграфа.
векторизация текста: выберите модель встраивания
модель BBA Чжиюаня (модель bge-base-zh) или выбрать из примера MTEB.
векторное хранение
-Faiss: для личного использования
-Milvus: уровень производства
используйте вектор для получения соответствующих точек знаний в соответствии с вопросами.
Top _ k
Faiss: сделайте расширенный поиск рядом с результатами поиска, чтобы получить аналогичные документы, размер которых меньше chunk _ size (обычно 500 слов)
Milvus: Topk Retrieval + bge-base-zh + параграф модели агрегирования сходства
идея: проанализируйте идею расширенного поиска на основе поиска topk, мы обнаруживаем, что это в основном за счет расширения семантических сегментов, чтобы большая модель получила как можно больше полезной информации, чтобы улучшить эффект ответа.
поезд мысли:
- Во-первых, документ разделен на блоки документов на уровне предложения на основе правил.
- затем используйте модель, чтобы интегрировать блоки документов, основанные на семантике, и, наконец, получить блоки документов, основанные на семантике.
- В-третьих, модель текстового вложения используется для документов последовательно, и документы снова агрегируются в соответствии с семантическим сходством, что эквивалентно двойному агрегированию первоначальных документов уровня предложения с помощью различных методов.
построить быстро
你现在是一个智能助手了,现在需要你根据已知内容回答问题
已知内容如下:
"{context}"
通过对已知内容进行总结并且列举的方式来回答问题:"{question}",在答案中不能出现问题内容,并且不允许编造内容,并且使用简体中文回答。
如果该问题和已知内容不相关,请回答 "根据已知信息无法回答该问题" 或 "没有提供足够的相关信息"。
генерировать ответ: выберите LLM
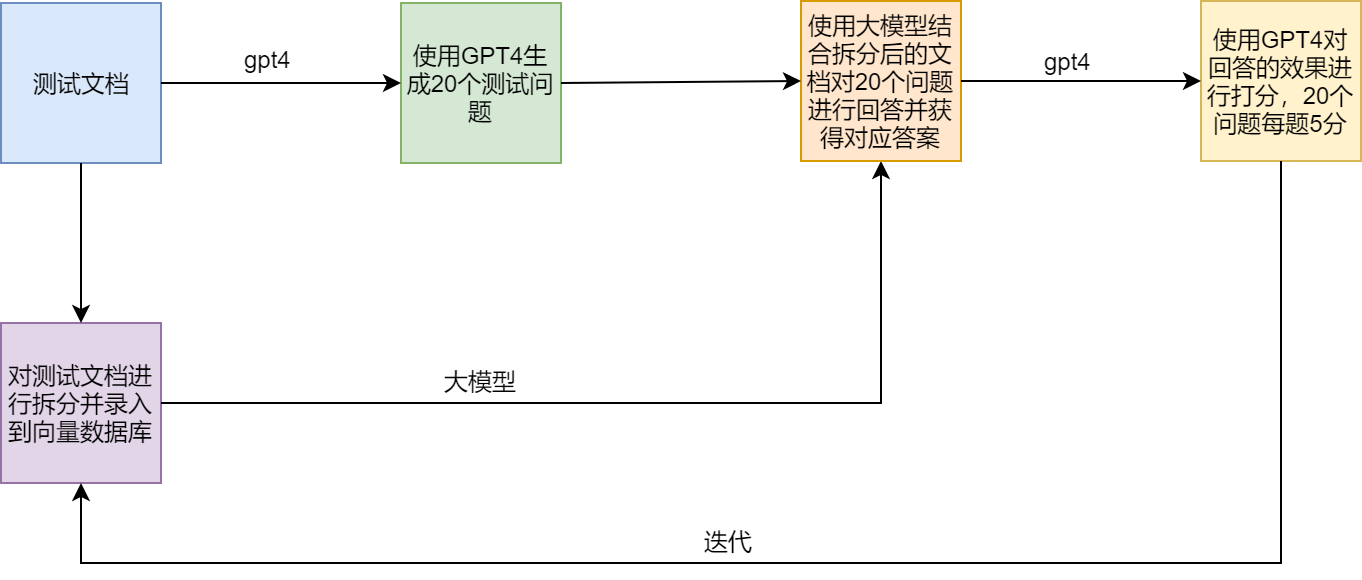
схема испытания
болевые точки и растворы тряпки

Примеры
LamaIndex官方提供了一个范例(SEC Insights),用来展示高级查询技术