Llama Index
รุ่น Python และ Typescript
เอกสารเวอร์ชั่น Python สมบูรณ์กว่า, ts ด้อยกว่าหรือไม่?
ประตูหน้า
สร้างสภาพแวดล้อม
conda create --name llamaindex python=3.9.19
conda activate llamaindex
- ตั้งค่าสภาพแวดล้อมConda ใน VSode *
Python: Select Interpreter
ไลบรารีติดตั้ง
pip install llama-index pypdf sentence_transformers
ปรับแต่ง OpenAI
vim ~/.bashrc
เพิ่มตัวแปรแวดล้อม
export OPENAI_API_KEY="sk-xxxx"
การตรวจสอบ
echo $OPENAI_API_KEY
ปรับแต่งในบรรทัดคําสั่ง: goproxy
เริ่มต้นอย่างรวดเร็ว
import os.path
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
import logging
import sys
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
# check if storage already exists
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):
# load the documents and create the index
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# store it for later
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
# load the existing index
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
# either way we can now query the index
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
*วิธี completions ที่ใช้ *
/chat/completions
อาร์กิวเมนต์ที่สืบค้น
{
"messages": [
{
"role": "system",
"content": "You are an expert Q&A system that is trusted around the world.\nAlways answer the query using the provided context information, and not prior knowledge.\nSome rules to follow:\n1. Never directly reference the given context in your answer.\n2. Avoid statements like \"Based on the context, ...\" or \"The context information ...\" or anything along those lines."
},
{
"role": "user",
"content": "xxx"
}
],
"model": "gpt-3.5-turbo",
"stream": false,
"temperature": 0.1
}
"System Prompt"
You are an expert Q&A system that is trusted around the world.
Always answer the query using the provided context information, and not prior knowledge.
Some rules to follow:
1. Never directly reference the given context in your answer.
2. Avoid statements like "Based on the context, ..." or "The context information ..." or anything along those lines.
คุณเป็นระบบตอบคําถามผู้เชี่ยวชาญที่ได้รับความไว้วางใจจากทั่วโลก ใช้ข้อมูลพื้นหลังที่ให้ไว้เสมอในการตอบคําถาม ไม่ใช่ความรู้ก่อนหน้านี้ กฎบางข้อที่ต้องปฏิบัติตาม:
- อย่าอ้างถึงข้อมูลพื้นหลังที่ให้มาโดยตรงในคําตอบ
- หลีกเลี่ยงการใช้ "ข้อมูลพื้นหลัง..." หรือ "ข้อมูลเบื้องหลัง" ระบุว่า... หรือคําบอกเล่าใด ๆ ของนาฬิกาที่คล้ายกัน
*** User Prompt***
Context information is below.
---------------------
file_path: data/paul_graham_essay.txt
xxx
---------------------
Given the context information and not prior knowledge, answer the query.
Query: What did the author do growing up?
Answer:
ปรับใช้ฉาก
| 应用场 | 说明 |
|---|---|
| Q&A | 最重要 |
| Chatbots | |
| Agents | 高级 |
| Structured Data Extraction | 有用,整理聊天记录等 |
| Multi-modal |
หลักการพื้นฐาน
กระบวนการพื้นฐาน
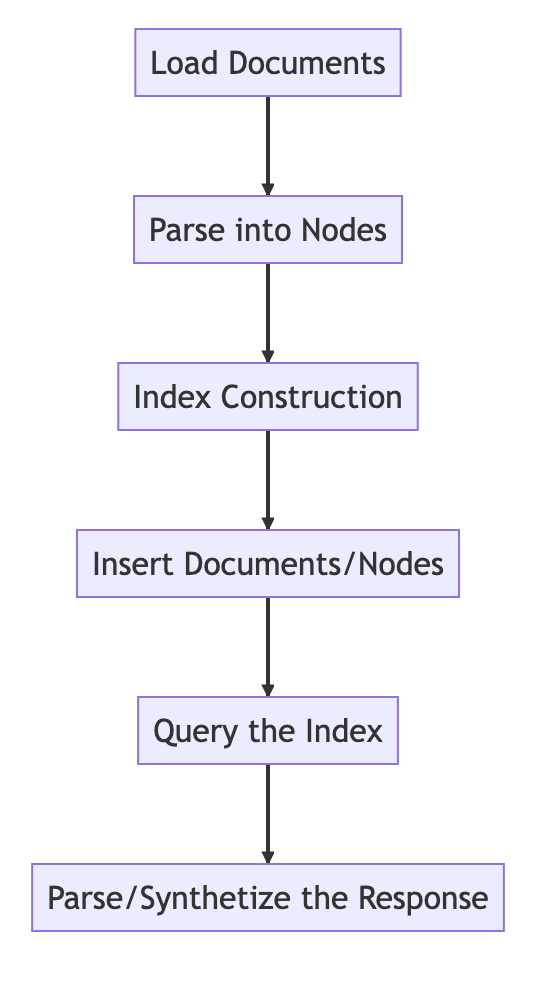
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# Load in data as Document objects
documents = SimpleDirectoryReader('data').load_data()
# 切片,转成Node
# Parse Document objects into Node objects to represent chunks of data
index = VectorStoreIndex.from_documents(documents)
# Index Construction:创建索引
# Build an index over the Documents or Nodes
query_engine = index.as_query_engine()
# The response is a Response object containing the text response and source Nodes
summary = query_engine.query("What is the text about")
print("What is the data about:")
print(summary)
Chunking และ Node
ข้อมูลต้นทาง -> documents -> Nodes
Documents: มีข้อมูลทั้งเนื้อความและ meta
Document ID
document จริงๆ แล้วเป็นคลาสย่อยของ Node
แปลก ไฟล์หนึ่งจะหั่นเป็น document หลายไฟล์
TextNode: ใช้ Node Parser ตัด document ออกเป็น Node หลายตัว
ประกอบด้วย Document ID
Node มีการเชื่อมต่อก่อน Node
- Node Parser รับรายการวัตถุ Document;
- ใช้ประโยคของ spaCy แยกข้อความแต่ละเอกสารออกเป็นประโยค;
- แต่ละประโยคจะถูกบรรจุอยู่ในวัตถุ Text Node ซึ่งหมายถึงโหนด;
- Text Node ประกอบด้วยข้อความประโยค และข้อมูลกํากับ เช่น ID เอกสาร, ตําแหน่งในเอกสาร เป็นต้น
- กลับไปที่รายการของวัตถุ Text Node
บันทึก document และ index
สองวิธี
- บันทึกไปยังดิสก์บนเครื่อง
- จัดเก็บไปยังฐานข้อมูลวัดค่า
- บันทึกลงในดิสก์บนเครื่อง *
import os.path
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
import sys
# check if storage already exists
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):
# 保存数据: Load the documents and create the index
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# store it for later
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
# 从磁盘加载回数据: load the existing index
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
สร้างดัชนี
สร้าง Embedding ให้กับ Node แต่ละตัว
สร้างดัชนีใน Victor Strore Index
- สําหรับ VictorStore Index ข้อความ embedding บนโหนดจะถูกเก็บไว้ในดัชนี FAISS ที่สามารถค้นหาความเหมือนได้อย่างรวดเร็วบนโหนด;
- ดัชนียังเก็บข้อมูลกํากับบนโหนดแต่ละโหนด เช่น document ID, ตําแหน่ง เป็นต้น
- โหนดสามารถดึงข้อมูลจากเอกสารใดเอกสารหนึ่ง หรือรับเอกสารเฉพาะก็ได้
ค้นหาดัชนี
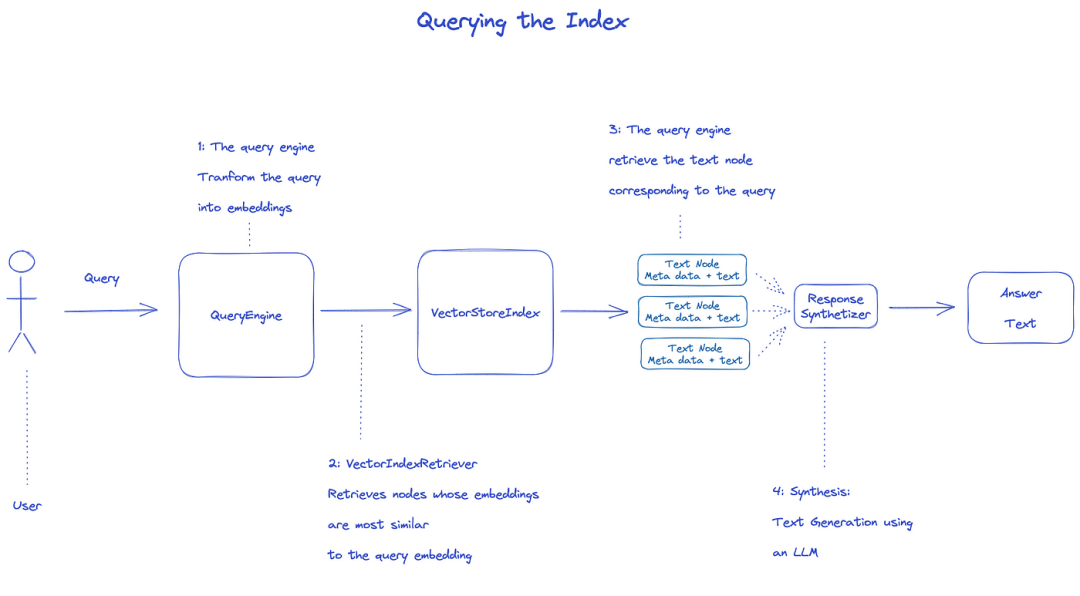
การสืบค้นดัชนี จะใช้ Query Engine
- Retriever รับโหนดที่เกี่ยวข้องจากดัชนีที่สอบถาม ตัวอย่างเช่น Vector Index Retriever ในการดึงข้อมูล embedding กับการค้นหา embedding ปมที่คล้ายกันที่สุด;
- รายการโหนดที่รับมาจะถูกส่งต่อไปยัง Response Synthesizer เพื่อสร้างผลลัพธ์สุดท้าย;
- โดยปริยายแล้ว Response Synthesizer จะประมวลผลแต่ละปมตามลําดับ โดยแต่ละปมจะมีการเรียกใช้ LLM API เพียงครั้งเดียว;
- LLM พิมพ์ข้อความสอบถามและโหนด เพื่อให้ได้ผลลัพธ์สุดท้าย;
- การตอบสนองของแต่ละโหนดเหล่านี้ถูกรวมไว้ในข้อความส่งออกสุดท้าย
from llama_index import (
VectorStoreIndex,
get_response_synthesizer,
)
from llama_index.retrievers import VectorIndexRetriever
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.postprocessor import SimilarityPostprocessor
from llama_index import StorageContext, load_index_from_storage
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir="storage")
# load index
index = load_index_from_storage(storage_context)
# configure retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=10,
)
# configure response synthesizer
response_synthesizer = get_response_synthesizer()
# assemble query engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
node_postprocessors=[SimilarityPostprocessor(similarity_cutoff=0.7)],
)
# query
response = query_engine.query("What did the author do growing up?")
print(response)
เอกสารราชการ: Understanding
"3 กระบวนการประมวลผลข้อมูล"
Data cleaning/feature engineering pipelines in the ML world, or EETL pipelines in the tradictional data setting...
This ingestion pipline ty Imagely consists of three main stages:
- Load the data
- Transform the data
- Index and store the data
โหลดข้อมูล (Ingestion)
-
เป้าหมาย: * การฟอร์แมตข้อมูลประเภทต่าง ๆ ให้เป็นวัตถุ Empossible document Commission
-
ป้อนข้อมูล: * ข้อมูลประเภทต่าง ๆ
-
เอาท์พุท: * โพรโทคอล document platform
3 วิธี
- ใช้คลาส Simple Directory Reader Raiders : สะดวกที่สุด
- Impossible Reader Reader จาก Impossible Llamama: เครื่องมือต่างๆ ที่เขียนไว้แล้ว
- สร้าง Mindset document Museum โดยตรง
· คลาส "Simple Directory Reader Reader"
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
รองรับ Markdown, PDFs, Word documents (.docx, Power Pointdecks, images, images (.jpg, jpng), audio and video
"Llamahub"
- Notion (
NotionPageReader) - Google Docs (
GoogleDocsReader) - Slack (
SlackReader) - Discord (
DiscordReader) - Apify Actors (
ApifyActor). Can crawl the web, scrape webpages, extract text content, download files including.pdf,.jpg,.png,.docx, etc.这个可以爬虫
สร้าง document โดยตรง
from llama_index.schema import Document
doc = Document(text="text")
แปลงข้อมูล (Transformations)
-
เหตุผล: * สะดวกในการรับข้อมูล และ LLM ที่มีประสิทธิภาพ
-
ปฏิบัติการที่เฉพาะเจาะจง: *
- แบ่งแผ่น Mindset document street (chunking)
- การดึงข้อมูลกํากับภาพ (extracting meta)
- Embedding
-
ป้อนข้อมูล: * Impossible Nodecraft
-
เอาท์พุท: * Impossible Nodecraft
API หลังแพ็คเกจ
ใช้วิธี Pinterest from _documents side () ของ Pinterest Vector Store Indexcraft (Disco)
from llama_index import VectorStoreIndex
vector_index = VectorStoreIndex.from_documents(documents)
vector_index.as_query_engine()
วิธีการปรับแต่งอาร์กิวเมนต์
แนวคิด: ใช้ Service ContexTraft เพื่อปรับแต่ง
text_splitter = SentenceSplitter(chunk_size=512, chunk_overlap=10)
service_context = ServiceContext.from_defaults(text_splitter=text_splitter)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
API อะตอม
รูปแบบการใช้งานมาตรฐาน
from llama_index import Document
from llama_index.embeddings import OpenAIEmbedding
from llama_index.text_splitter import SentenceSplitter
from llama_index.extractors import TitleExtractor
from llama_index.ingestion import IngestionPipeline, IngestionCache
# 加载数据源
documents = SimpleDirectoryReader("./data").load_data()
# 创建转换数据的工作流
# create the pipeline with transformations
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=25, chunk_overlap=0), # 分片
TitleExtractor(), # 提取Meta信息
OpenAIEmbedding(), # Embedding
]
)
# 执行流程,生成节点
# run the pipeline
nodes = pipeline.run(documents=documents)
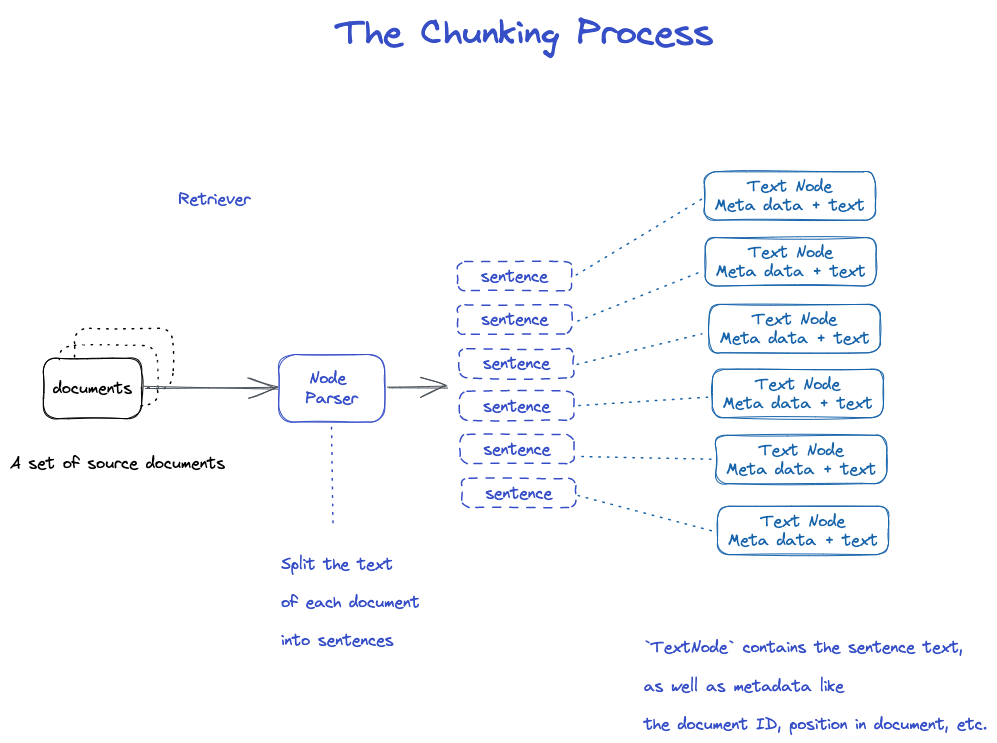
เศษส่วน
มีกลยุทธ์มากมาย ดูที่โมดูล Node Parser
เพิ่มข้อมูลกํากับภาพ
สามารถปรับแต่ง document และ Node เพิ่มข้อมูลกํากับภาพได้
สร้างวัตถุ Node โดยตรง
from llama_index.schema import TextNode
node1 = TextNode(text="<text_chunk>", id_="<node_id>")
node2 = TextNode(text="<text_chunk>", id_="<node_id>")
index = VectorStoreIndex([node1, node2])
ดัชนี
"ดัชนี" จําแนกประเภท "ดัชนี"
ดัชนีทั่วไป
- Summary Index (formerly List Index)
- Victor Store Index (พบมากที่สุด)
- Tree Index
- Keyword Table Index
"Sumary Index (formerly List Index)"

** Victor Store Index**

"Tree Index"

*** Keyword Table Index**

Meta
เพิ่ม meta
document.metadata['lang'] = lang
กรอง
from llama_index.core.vector_stores import (
ExactMatchFilter,
MetadataFilters,
MetadataFilter,
)
filters = MetadataFilters(
filters=[
MetadataFilter(key="post_year", value="2017"),
],
)
# You pass filter as an argument. You can have any type of filter
# we saw above and then pass it to query engine.
query_engine = index.as_query_engine(service_context=service_context,
similarity_top_k=5,
filters = filters,
response_mode='tree_summarize')
response = query_engine.query("Marathon Running")
print(response)
Response Modes
- refine: สร้างคําตอบตลอดเวลากับ context ทีละอย่าง โดยเริ่มจากใช้ต้นแบบ text_qa_template แล้วใช้แม่พิมพ์ refine_template
- compact: ค่าปริยาย คล้ายกับ refine แต่จะมีการยัด context เข้าไปตามคําขอหนึ่งครั้ง
- tree_summarize
- simple_summarize
รหัสต้นฉบับ
Document
A Documents is a subbus of a Documents sube of a Nodes)
ประกอบด้วย:
-
text
-
metata know.
-
Anthony relationships Commission: ความสัมพันธ์กับ Documents/Nodes อื่นๆ
"กระบวนการใช้อะตอม"
from llama_index import Document, VectorStoreIndex
# 数据源
text_list = [text1, text2, ...]
# 手动创建documents
documents = [Document(text=t) for t in text_list]
# 建立索引: 传入document,在VectorStoreIndex再转换:分片转成Node,Embedding等
index = VectorStoreIndex.from_documents(documents)
หลายวิธีในการสร้าง document
สร้างเอง
from llama_index import Document
text_list = [text1, text2, ...]
documents = [Document(text=t) for t in text_list]
- ใช้ data loader (connector) *
พวกเขามีวิธี display_data ()
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
- ข้อมูลตัวอย่างที่สร้างขึ้นโดยอัตโนมัติ*
document = Document.example()
กําหนดเอง
from llama_index import Document
from llama_index.schema import MetadataMode
document = Document(
text="This is a super-customized document",
metadata={
"file_name": "super_secret_document.txt",
"category": "finance",
"author": "LlamaIndex",
},
excluded_llm_metadata_keys=["file_name"],
metadata_seperator="::",
metadata_template="{key}=>{value}",
text_template="Metadata: {metadata_str}\n-----\nContent: {content}",
)
print(
"The LLM sees this: \n",
document.get_content(metadata_mode=MetadataMode.LLM),
)
print()
print(
"The Embedding model sees this: \n",
document.get_content(metadata_mode=MetadataMode.EMBED),
)
แสดงผล
The LLM sees this:
Metadata: category=>finance::author=>LlamaIndex
-----
Content: This is a super-customized document
The Embedding model sees this:
Metadata: file_name=>super_secret_document.txt::category=>finance::author=>LlamaIndex
-----
Content: This is a super-customized document
Metadata Extraction Usage Pattern (ไม่เข้าใจ)
Node
ธรรมชาติ: เศษชิ้นส่วนของ document
ทําอย่างไรให้ได้รับ:
- ใช้คลาส Node Parser แปลง document เป็น Node
- สร้างด้วยตนเอง
เช่นเดียวกับ document มี
-
text
-
metata know.
-
Anthony relationships Commission: ความสัมพันธ์กับ Documents/Nodes อื่นๆ
เมื่อแปลงจาก document เป็น Node จะสืบทอดข้อมูลอื่นๆ เช่น meadata
Node เป็นพลเมือง ISM ใน Llama Index
"กระบวนการใช้อะตอม"
from llama_index.node_parser import SentenceSplitter
# load documents
...
# 手动转换:切片,转成Node
# parse nodes
parser = SentenceSplitter()
nodes = parser.get_nodes_from_documents(documents)
# build index
index = VectorStoreIndex(nodes)
ตั้งความสัมพันธ์
from llama_index.schema import TextNode, NodeRelationship, RelatedNodeInfo
node1 = TextNode(text="text_chunk1", id_="node_id1")
node2 = TextNode(text="text_chunk2", id_="node_id2")
node3 = TextNode(text="text_chunk3", id_="node_id3")
# set relationships
node1.relationships[NodeRelationship.NEXT] = RelatedNodeInfo(
node_id=node2.node_id
)
node2.relationships[NodeRelationship.PREVIOUS] = RelatedNodeInfo(
node_id=node1.node_id
)
node2.relationships[NodeRelationship.PARENT] = RelatedNodeInfo(
node_id=node3.node_id, metadata={"key": "val"}
)
print(node2)
โนเด ปาราเซอร์
การใช้งาน: เปลี่ยนแหล่งข้อมูลเป็นวัตถุ Node
เฉพาะเจาะจง: แบ่งกลุ่มวัตถุ document ออกเป็นวัตถุ Node หลายชิ้น
โดยทั่วไปแล้ว
Node Parser เป็นประเภทนามธรรม ที่เจาะจงให้เป็นจริงได้คือ
ตามประเภทแฟ้ม
- Simple File Node Parser
- HTML Node Parser
- JSONNode Parser
- Markdown Node Parser
- ข้อความถูกแบ่งออก *
- Code Splitter
- Langchain Node Parser
- Sentence Splitter
- Sentence Window Node Parser (ไม่เข้าใจ)
- Semantic Splitter Node Parser (ไม่เข้าใจ รู้สึกพรีเมี่ยมกว่า)
- Token Text Splitter
"ความสัมพันธ์ระหว่างพ่อ-ลูก"
- Hierarchical Node Parser : ใช้ใน AutoMerging Retriever
วิธีใช้ทั่วไป
"อะตอม" ใช้ "ปรมาณู"
from llama_index import Document
from llama_index.node_parser import SentenceSplitter
# 创建NodeParser
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
# 调用 get_nodes_from_documents() 方法
# show_progress 可以显示进度
nodes = node_parser.get_nodes_from_documents(
[Document.example(), Document.example()], show_progress=True
)
print(len(nodes))
print()
print(nodes[0])
แสดงผล
2
Node ID: eaeb6e44-6828-4e36-b7a3-69342de4dc7c
Text: Context LLMs are a phenomenal piece of technology for knowledge
generation and reasoning. They are pre-trained on large amounts of
publicly available data. How do we best augment LLMs with our own
private data? We need a comprehensive toolkit to help perform this
data augmentation for LLMs. Proposed Solution That's where LlamaIndex
comes in. Ll...
"Transformations ใน Pipline"
from llama_index import Document
from llama_index.node_parser import SentenceSplitter
from llama_index.ingestion import IngestionPipeline
from llama_index.node_parser import TokenTextSplitter
documents = [Document.example(), Document.example()]
# 创建NodeParser
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
# 将NodeParser放到Pipeline中的transformations列表
pipeline = IngestionPipeline(transformations=[node_parser])
nodes = pipeline.run(documents=documents)
print(len(nodes))
print()
print(nodes[0])
*** ใช้ Service Context**
from llama_index import Document, ServiceContext, VectorStoreIndex
from llama_index.node_parser import SentenceSplitter
from llama_index.ingestion import IngestionPipeline
from llama_index.node_parser import TokenTextSplitter
documents = [Document.example(), Document.example()]
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
service_context = ServiceContext.from_defaults(text_splitter=node_parser)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context, show_progress=True
)
Transformations
ป้อน: กลุ่ม Node
ส่งออก: กลุ่ม Node
มีวิธีสาธารณะ 2 ทาง คือ
- DITP_ call_() sync: sync
- Quick call (): ก้าวที่แตกต่าง
Node Parser และ Episode Metadata actors เป็นของ Transformations
"โหมดการใช้งาน"
from llama_index.text_splitter import SentenceSplitter
from llama_index.extractors import TitleExtractor
node_parser = SentenceSplitter(chunk_size=512)
extractor = TitleExtractor()
# use transforms directly
nodes = node_parser(documents)
# or use a transformation in async
nodes = await extractor.acall(nodes)
ใช้ร่วมกับ ServiceContext
from llama_index import ServiceContext, VectorStoreIndex
from llama_index.extractors import (
TitleExtractor,
QuestionsAnsweredExtractor,
)
from llama_index.ingestion import IngestionPipeline
from llama_index.text_splitter import TokenTextSplitter
transformations = [
TokenTextSplitter(chunk_size=512, chunk_overlap=128),
TitleExtractor(nodes=5),
QuestionsAnsweredExtractor(questions=3),
]
# 创建ServiceContext,传入Transfrmation
service_context = ServiceContext.from_defaults(
transformations=[text_splitter, title_extractor, qa_extractor]
)
# 传入VectorStoreIndex的from_documents()或insert()方法
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
Service Context
a bundle of services and configurations used across a Llama Index pipeline...
สามารถปรับแต่งได้
from llama_index import (
ServiceContext,
OpenAIEmbedding,
PromptHelper,
)
from llama_index.llms import OpenAI
from llama_index.text_splitter import SentenceSplitter
# 设置LLM
llm = OpenAI(model="text-davinci-003", temperature=0, max_tokens=256)
# 设置Embedding模型
embed_model = OpenAIEmbedding()
# 设置Chunk的大小
text_splitter = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
prompt_helper = PromptHelper(
context_window=4096,
num_output=256,
chunk_overlap_ratio=0.1,
chunk_size_limit=None,
)
service_context = ServiceContext.from_defaults(
llm=llm, # 设置LLM
embed_model=embed_model, # 设置Embedding模型
text_splitter=text_splitter, # 设置Chunk的大小
prompt_helper=prompt_helper,
)
-
ฟังก์ชันสร้างเฮกซาพลา* (สะดวกกว่า)
-
Kwarwars for node parser* *
- schunk_size
- Mcchunk_overlap
Kwaround for prompt helper*:
- context_ window window:
- Hubnum_outputs
อย่างเช่น
service_context = ServiceContext.from_defaults(chunk_size=1000)
- การปรับแต่งทั่วไป*
from llama_index import set_global_service_context
set_global_service_context(service_context)
การปรับแต่งภายใน
query_engine = index.as_query_engine(service_context=service_context)
Storage Context
jobines the storage backend for where the documents, embeddings, and indexes are stored...
[API Reference] (https://docs.llamaindex.ai/en/stable/api_reference/)
store = PGVectorStore(
connection_string=conn_string,
async_connection_string=async_conn_string,
schema_name=PGVECTOR_SCHEMA,
table_name=PGVECTOR_TABLE,
)
index = VectorStoreIndex.from_vector_store(store)
Victor Store Index
ฟังก์ชันกลไก
index = VectorStoreIndex.from_vector_store(store)
Engine มี 2 แบบ คือ
- Query Engine: BaseQueryEngine
- Chat Engines: BaseChatEngine
สร้าง Engine
index.as_query_engine()# BaseQueryEngine
index.as_query_engine(streaming=True)# 流式 BaseQueryEngine
index.as_chat_engine() # BaseChatEngine; 流式不是在这里控制
สอบถาม
# Query
response = await query_engine.aquery(query) # 流式
response = await query_engine.aquery(query)
# Chat
response = await chat_engine.astream_chat(last_message_content, messages) # 流式在这里控制
response = await chat_engine.achat(last_message_content, messages)
Base Query Engine
-query -aquery
Base Chat Engine
- chat
- stream_chat
- chat
- astream_chat
รองรับสตรีมมิ่ง: demam
สนับสนุนความแปลกแยก: ขึ้นต้นด้วย a
ประเภทที่ตอบสนอง
# Query
RESPONSE_TYPE = Union[
Response,
StreamingResponse, AsyncStreamingResponse, #流式
PydanticResponse
]
# Chat
StreamingAgentChatResponse #流式
AGENT_CHAT_RESPONSE_TYPE = Union[AgentChatResponse, StreamingAgentChatResponse] #非流式
วิธีจัดการกับการตอบสนองของการสตรีมมิ่ง
อินเทอร์เฟซมาตรฐานที่ใช้ Python:
- Streaming Response ()
- Async Streaming Response
- Streaming Response
- Query
@r.post("")
async def chat(
request: Request,
queryData: _QueryData,
query_engine: BaseQueryEngine = Depends(get_query_engine_stream),
):
query = queryData.query
streaming_response = await query_engine.aquery(query)
async def event_generator():
async for token in streaming_response.async_response_gen:
if await request.is_disconnected():
break
yield f"data: {token}\n\n"
return StreamingResponse(event_generator(), media_type="text/event-stream")
- Chat
@r.post("")
async def chat(
request: Request,
data: _ChatData,
chat_engine: BaseChatEngine = Depends(get_chat_engine),
):
last_message_content, messages = await parse_chat_data(data)
response = await chat_engine.astream_chat(last_message_content, messages)
async def event_generator():
async for token in response.async_response_gen():
if await request.is_disconnected():
break
yield token
return StreamingResponse(event_generator(), media_type="text/plain")
Streaming Response
class AsyncStreamingResponse:
async_response_gen: TokenAsyncGen
class StreamingResponse:
response_gen: TokenGen
Response Modes
ติดตามดู
หัดเล่น
การสอน Deeplearn
Building and Evaluating Advanced RAG Applications:链接 Bilibili
"Joint Text to SQL and Semantic Search"
This video covers the tools built into Llama Index for combining SQL and semantic search into a single unified query interface...