RAG:检索增强生成
RAG
Paçavra: Artırma Geliştirilmiş Ögeleri
Karmaşık bir davayı çözmeye çalışıyorsun.
Bir dedektifin görevi, davayla ilgili ipuçları, kanıtlar ve tarihsel kayıtlar toplamaktır. Dedektif bilgileri topladıktan sonra, muhabir gerçekleri büyüleyici bir hikaye olarak özetledi ve tutarlı bir hikaye sundu.
LLM'nin sorunu
- Halüsinasyon: Cevap vermeden yanlış bilgi sağlamak.
- LLM modası geçmiş bilgileri kullanır, ve son bilgi süresinden sonra en son ve güvenilir bilgilere erişemez.
- Buna ek olarak, LLM tarafından sağlanan cevap kaynağına atıfta bulunmamaktadır, bu da iddianın kullanıcı tarafından doğru veya tam güvenilir olarak doğrulanamayacağı anlamına gelir. Bu, yapay zeka tarafından oluşturulan bilgileri kullanırken bağımsız doğrulama ve değerlendirmenin önemini vurgulamaktadır.
您可以将大型语言模型看作是一个过于热情的新员工,他拒绝随时了解时事,但总是会绝对自信地回答每一个问题。
Bu sorunları çözmenin tek yolu paçavra. LLM'yi yeniden yönlendirir ve bilgi kaynağından ilgili bilgileri geri alır. Örgütlerin oluşturulan metin çıktıları üzerinde daha fazla kontrolleri vardır, ve kullanıcılar LLM'nin tepkileri nasıl oluşturduğu hakkında daha fazla şey öğrenebilirler.
LLM Süreci
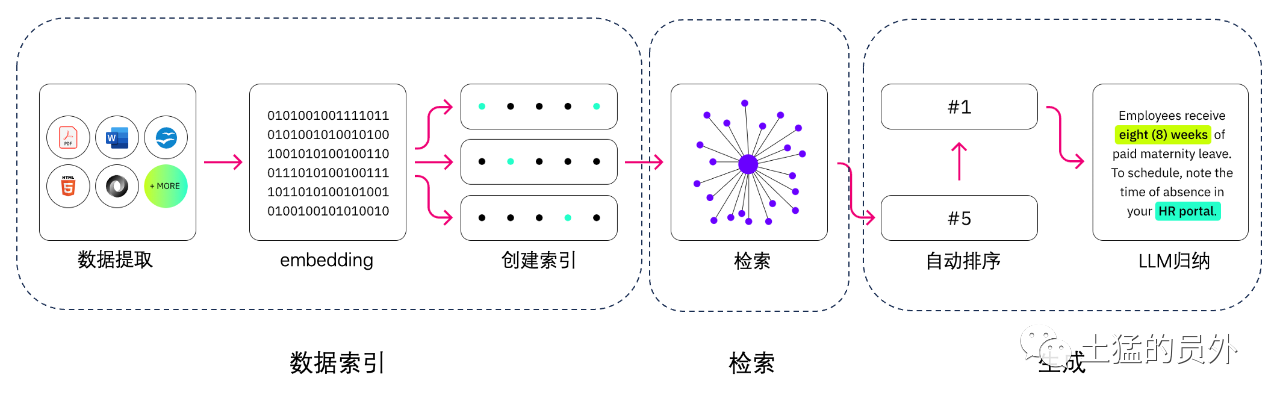
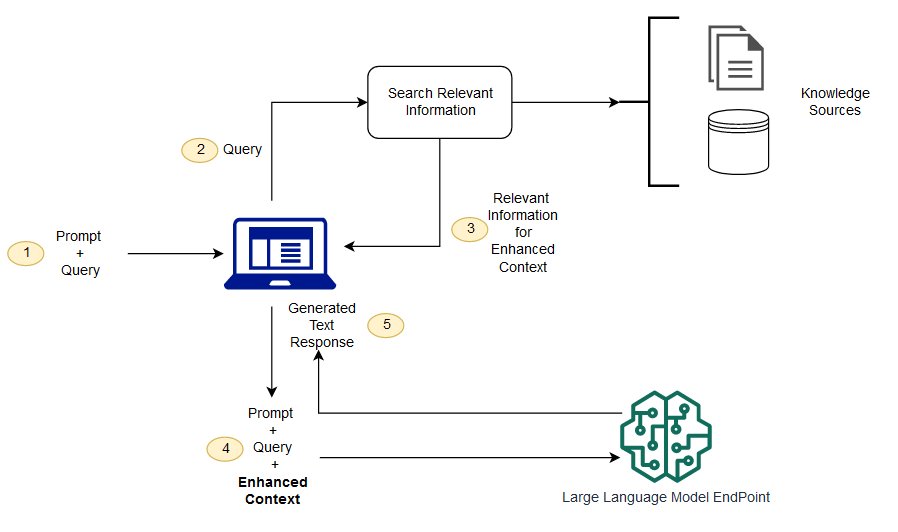
Yeni nesille katalitik arama arasındaki fark nedir?
Atletik arama, LLM uygulamalarına çok sayıda dış bilgi kaynağı eklemek isteyen kuruluşların paçavra sonuçlarını geliştirebilir. Modern Girişimcilik, UNICEF, FAQ'lar, araştırma raporları, müşteri hizmetleri rehberleri ve insan kaynakları depoları gibi çeşitli sistemlerde büyük miktarda bilgi depolar. Bağlamsal geri alma ölçekte zorludur ve bu nedenle üretilmiş çıktının kalitesini küçültür.
Manyetik arama teknolojisi: Farklı bilgileri içeren büyük veritabanlarını tarayıp daha doğru bir şekilde elde edebilirsiniz. Örneğin, "Geçen yıl mekanik bakım için ne kadar harcadınız?" gibi sorulara cevap verebilirler. Soruyu ilgili belgeye haritalandırarak ve arama sonuçları yerine spesifik metnin iade edilmesi gibi sorular. Geliştiriciler bu cevabı LLM için daha fazla bağlam sağlamak için kullanabilirler.
Paçavrada geleneksel veya anahtar kelime arama çözümleri bilgi için sınırlı sonuçlar üretir - yoğun görevler. Geliştiriciler, veriyi elle hazırlarken kelime yerleştirme, belge parçalanması ve diğer kompleks sorunlarla da uğraşmak zorundalar. Buna karşılık, katalitik arama teknolojisi bilgi tabanının hazırlandığı tüm işleri yapabilir, bu yüzden geliştiriciler bunu yapmak zorunda değil. Aynı zamanda alfabetik olarak ilgili hiyeroglifler üretirler ve bez parçacığının kalitesini vurgulamak için sıralanmış kelimeleri sıralarlar.
Bezin üç çekirdek bileşeni
Geliştirilmiş jenerasyon modeli temel olarak üç çekirdek bileşenden oluşur:
- HTML: Dış bilgi kaynaklarından ilgili bilgilerin çıkarılmasından sorumludur. @ info: whatsthis
- Parçalayıcı (Ranker): Arama sonuçlarını değerlendirir ve değerlendirir.
- Jeneratör: Son cevabı ya da içeriği oluşturmak için kullanıcının girdisiyle birleştirilen geri alma ve sıralama sonuçlarını kullan.
Bez beyin haritası
Bu resim çok detaylı!
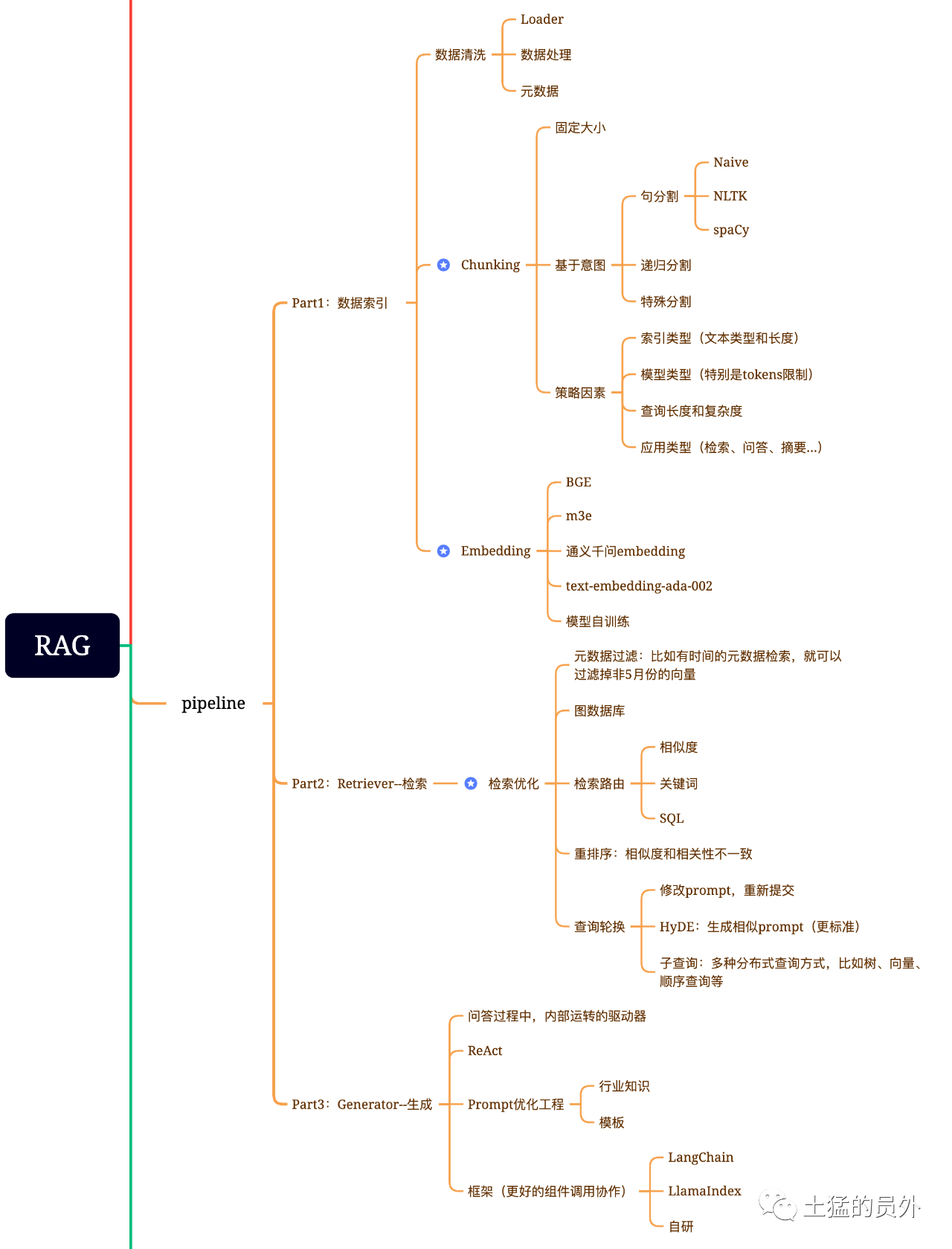
Veri İndeksleme
- ** Veri çıkarma **
Veri temizliği: Veri Lozomotifi, EUFOR'un çıkarılması, kelime, işaretleme, veritabanı ve API, vb.
- Veri işleme: Veri biçimlendirme işlemi, tanımlanabilir içeriğin elenmesi, sıkıştırma ve biçimlendirme gibi. Dosya adı, zaman, bölüm başlığı, resim sıralaması ve diğer bilgileri almak çok önemli.
Veri Çıkarma Araçları
- Yapısal olmayanlar (kullanılan) @ info: whatsthis
- LlamaParse (kullanılan) @ info: whatsthis
- Google belge AI
- AWS TextractGenericName
- pdf2Image+ piksel seract
Ara
Kurtarma iyonlaşması genellikle şu beş bölüme ayrılır:
Endeksi bir çok parçaya böldüğümüzde, geri alma verimliliği sorun olacaktır. Şu anda, önce UUIM yeniden programlanabilirse, verimlilik ve ilgisi büyük ölçüde artırılacaktır. Örneğin, "Bu yılın Mayıs ayında XX bölümündeki tüm sözleşmeleri düzenlememe yardım edin, XX ekipmanlarının satın alınması da dahil mi?" diye soruyoruz. - Evet. Şu anda, eğer bir tutarsızlık varsa, "** XX Department + Mayıs 2023** ve geri alma miktarı aynı anda 1/10000 olabilir.
-** Graph ilişkisi geri alma**: Eğer birçok varlığı düğüme dönüştürebilirseniz ve aralarındaki ilişkiyi ilişkiye dönüştürebilirseniz, daha doğru cevaplar vermek için bilgi arasındaki ilişkiyi kullanabilirsiniz. Özellikle de bazı çoklu- hop sorunları için, Grafik veri endeksinin kullanımı geri alma işlemini daha ilgili hale getirecek.
-
** Retrieval teknolojisi**: Yukarıda bazı analizler var - işlem yöntemleri, ve ana geri alma yöntemleri şu şekildedir:
-
- 相似度检索:前面我已经写过那篇文章《大模型应用中大部分人真正需要去关心的核心——Embedding》中有提到六种相似度算法,包括欧氏距离、曼哈顿距离、余弦等,后面我还会再专门写一篇这方面的文章,可以关注我,yeah; Bu çok geleneksel bir arama yöntemidir, ama bazen çok önemlidir. Az önce bahsettiklerimiz bir tür, diğeri de önce Chunk'un bir özetini yapmak, ve sonra anahtar kelime ile muhtemel parçayı bulmak, geri alma verimliliğini artırmak için. Claude.ai'nin de aynı şeyi yaptığı söyleniyor. Bu daha gelenekseldir, ama bazı üst düzey girişim uygulamaları için, XML sorgusu temel bir adımdır. Örneğin, daha önce bahsettiğim satış verilerinin önce UUIM tarafından aranması gerekiyor.
-
Diğer: Hala bir sürü geri alma teknikleri var, o yüzden bunu daha sonra konuşalım.
-** rerank**: Birçok durumda, geri alma sonuçlarımız ideal değildir, çünkü sistemde çok sayıda parça vardır, ve kurtardığımız boyutlar ille de uygun değildir, ve bir aramanın sonuçları pek de uygun olmayabilir. Şu anda, yeniden sipariş vermek için planb'ı kullanmak veya iş senaryomuza daha uygun bir sıralama elde etmek için uyumluluk, eşleştirme ve diğer faktörler gibi geri alma sonuçlarını yeniden düzenlemek için bazı stratejilere ihtiyacımız var. Çünkü bu adımdan sonra, sonucu son işlem için LLM'ye göndereceğiz, yani bu bölümün sonucu çok önemli. Ayrıca mahkeme emrini gözden geçirip yeniden düzenlemeyi tetikleyecek bir iç yargıç da olacak.
Bu bir sorgulama ve geri alma yöntemidir ve genellikle birçok yol vardır:
- ** Sub - sorgu:** Farklı senaryolarda çeşitli sorgu stratejilerini kullanabilirsiniz. Örneğin, Llamaxicz, ağaç sorgusu, ağaç sorgusu (adım düğümlerinden, adım sorgusu, birleştirme), vektör sorgusu, ya da en ilkel sıralı sorgu parçaları, vb.
-** Hyde:** Bu, benzer ya da daha standart şablonlar üretmek için işleri kopyalamanın bir yoludur. ****
R- RankGenericName
Çoğu vektör veritabanları hesaplama verimliliği için belirli bir doğruluk derecesini feda eder. Bu geri alma sonuçlarını rastgele yapar, ve orijinal geri dönen Top K en çok da ilgili olmak zorunda değildir. @ info: whatsthis
使用BAAI/bge-reranker-base、BAAI/bge-reranker-large等开源模型来完成Re-Rank操作。
Ve Neteease'in MÖ-reranker'ı da Çin'i, İngiltere'yi, Japonya'yı ve Güney Kore'yi destekliyor.
Geri Alma/ Karışık Geri Alma
İki - Yol Sorgusu:
- Atletik geri alma (vektör arama) / * Vektör veritabanının geri çağırılması *
- Anahtar Sözcük Araması (key Word Arama) / Anahtar Sözcük Arama Çağrısı
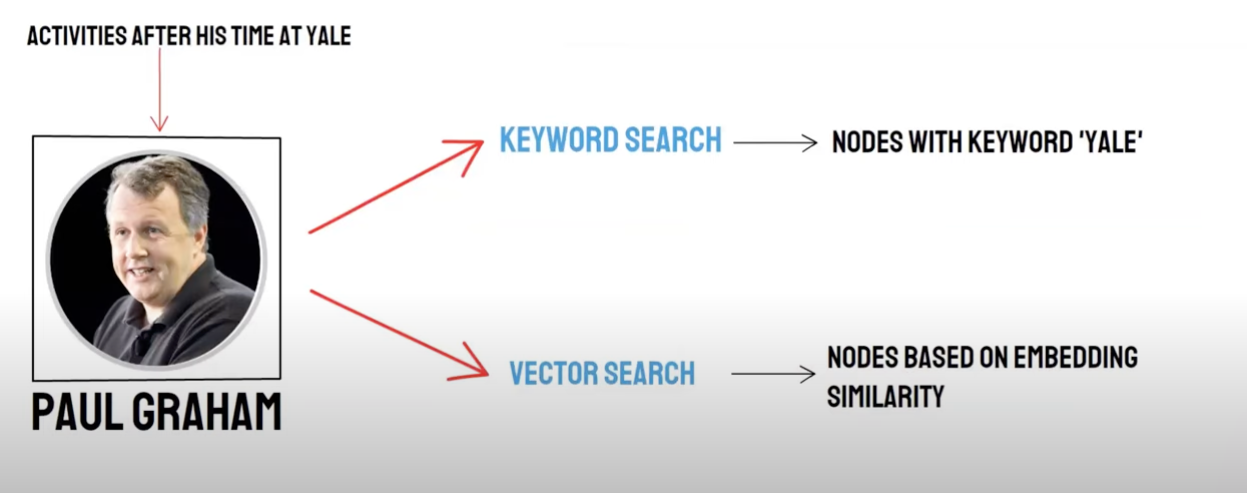
Vektör veritabanı geri çağırma ve anahtar kelime geri alma kendi avantajları vardır, bu yüzden bu ikisinin geri çağırma sonuçlarını birleştirmek genel geri alma doğruluğu ve verimliliği artırabilir. Karşılıklı füzyon (karşılıklı Rank Fusion, RFS) algoritması her belgenin sıralamasını farklı geri çağırma yöntemleriyle füzyondan sonra toplam skoru hesaplar.
Anahtar kelime geri alma geri çağırmayı seçtiğinizde, yani, anahtar kelime Retrieval**, anahtar sözcükler birbirine benzer**, PAI, vektör veritabanı ve anahtar kelime geri alma sonuçlarını öntanımlı olarak kullanarak RFS algoritmasını kullanacaktır.
Oluştur
Çerçevede Langchain ve Llamaqua var.
Teknolojiyi sayma ve hasat etme planı.
Çerçeve
Zor olan şu: Metin ne anlama geliyor - Xindi'ye mi?
Metin paylaşımı:
Metin bölünmesi: Belge, sonraki metnin yerleştirilmesini kolaylaştırmak ve daha sonra belgenin ele geçirilmesini kolaylaştırmak için daha küçük bloklara ayrılmıştır.
K3b: Alfabetik olarak bağlantılı metin parçalarını bir araya getir.
** Ayrılık metodu **
- Kurala göre, belgeyi cümleye göre bölmek en kolay yoldur. Belge, Çince ve İngilizce'deki ortak sonlandırma sembollerine göre bölünmüştür, mesela tek karakter kırıcı, Çince ve İngilizce skleroz, çift tırnak işareti ve benzeri gibi.
- EEG'ye göre: 1 numara. İlk olarak, belge hüküme bölünür - kurallara göre seviye doküman blokları.
- İki. - İki. O zaman bu modelle doküman bloklarını XML'e göre entegre etmek ve sonunda katalitik- doküman bloklarını almak için kullanın.
** Manyetik - tabanlı metin bölme modeli **
SEQ_Model**, Ali Dama Enstitüsü tarafından geliştirilen model, yarık cümlenin paragraf sınırına ait olup olmadığını tahmin ederek katalitik segmentasyonu belirleyen Bert+ sürgülü pencereye dayanmaktadır.
Metin Hesaplama: Gönderme Modelini Seç@ info: whatsthis
Shaoyuan'ın BBA modeli (BGE - baz - zh modeli) ya da MTEB örneğinden seçin.
Vektör Depolama
-
Kişisel kullanım için.
-
Milkha: Üretim seviyesi
Sorulara göre eşleşen bilgileri almak için vektör kullanın.
Üst_ k
Faiss: Arama sonuçlarının yakınında, Chunk_ boyutundan daha az (genellikle 500 kelime) benzer belgeler elde etmek için geniş bir arama yapın (genellikle 500 kelime)
Milkha: TOPK Retrieval+BGE - baz - zh+ Paragraf Toplama Modeli
Fikir: Uzatılmış geri alma fikrini TOPK'ya dayanarak analiz ederek, büyük modelin cevabın etkisini geliştirmek için mümkün olduğu kadar yararlı bilgiler elde etmesinin daha çok katalitik emisyonların genişlemesinden kaynaklandığını görüyoruz.
Düşünce treni:
- İlk olarak, belge hüküme bölünür - kurallara göre seviye doküman blokları.
- O zaman bu modelle doküman bloklarını XML'e göre entegre etmek ve sonunda katalitik- doküman bloklarını almak için kullanın.
- Üçüncü olarak, metin yerleştirme modeli dokümanlar sıralı olarak kullanılır, ve dokümanlar, orijinal cümleyi birleştirmeye eşdeğer, farklı yöntemlerle iki katlı dokümanlara eşdeğerdir.
İnşa Oluştur
你现在是一个智能助手了,现在需要你根据已知内容回答问题
已知内容如下:
"{context}"
通过对已知内容进行总结并且列举的方式来回答问题:"{question}",在答案中不能出现问题内容,并且不允许编造内容,并且使用简体中文回答。
如果该问题和已知内容不相关,请回答 "根据已知信息无法回答该问题" 或 "没有提供足够的相关信息"。
Cevap oluştur: LLM Seç
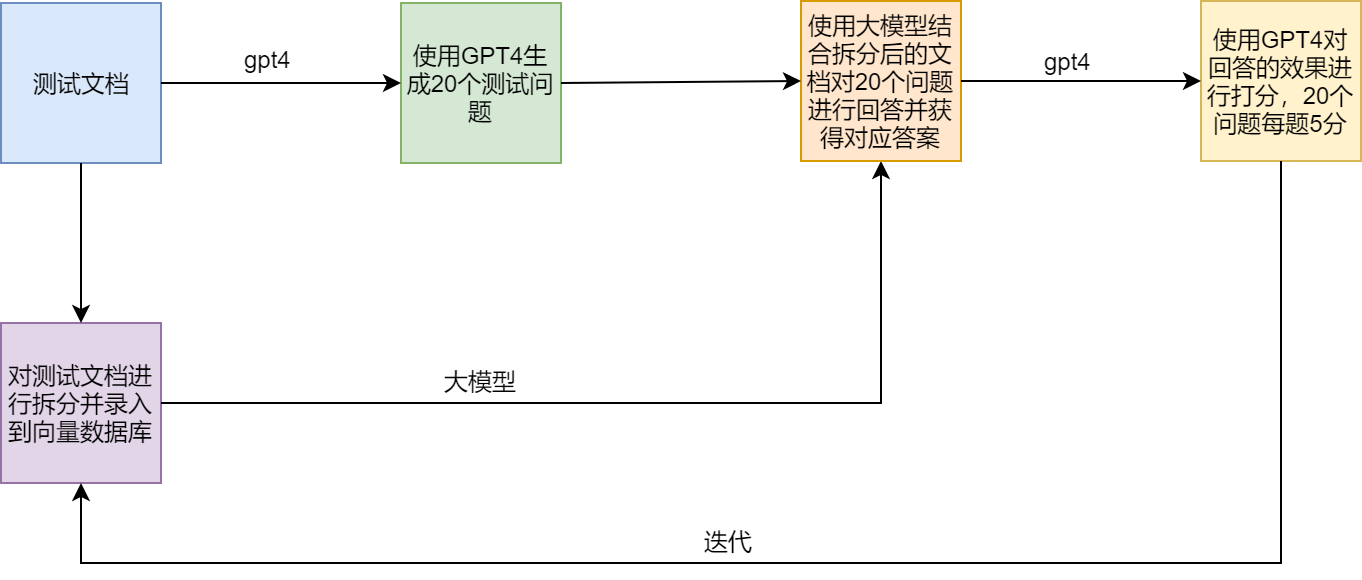
Test şeması
Acı noktaları ve paçavraların solüsyonları

Örnekler
LamaIndex官方提供了一个范例(SEC Insights),用来展示高级查询技术