RAG:检索增强生成
RAG (Rập)
RAG: Retrieval Augmented Generation
Bạn đang cố gắng giải mã một vụ án phức tạp:
- Vai trò của thám tử là thu thập các manh mối, chứng cứ liên quan đến vụ án và một số hồ sơ lịch sử.
- Sau khi thám tử thu thập thông tin này, phóng viên đã tóm tắt những sự kiện này thành một câu chuyện hấp dẫn và trình bày một câu chuyện nối tiếp.
Câu hỏi của LLM
- ảo giác: cung cấp thông tin sai sự thật khi chưa có câu trả lời.
- LLM sử dụng những thông tin lỗi thời, nó không thể truy cập những thông tin mới nhất, đáng tin cậy sau khi hết hạn kiến thức của mình.
- Ngoài ra, câu trả lời mà LLM cung cấp không được trích xuất từ nguồn, có nghĩa là ý kiến của nó không thể được người dùng Điều này cho thấy tầm quan trọng của việc kiểm định độc lập và đánh giá khi sử dụng thông tin do trí tuệ nhân tạo tạo ra.
您可以将大型语言模型看作是一个过于热情的新员工,他拒绝随时了解时事,但总是会绝对自信地回答每一个问题。
RG là một giải pháp cho một số thách thức. Nó sẽ được định hướng lại để truy xuất các thông tin liên quan từ nguồn kiến thức có thẩm quyền và xác định trước Các tổ chức có thể kiểm soát tốt nhất đầu ra văn bản được tạo ra và bạn có thể tìm hiểu sâu hơn vê
Quy trình của LLM
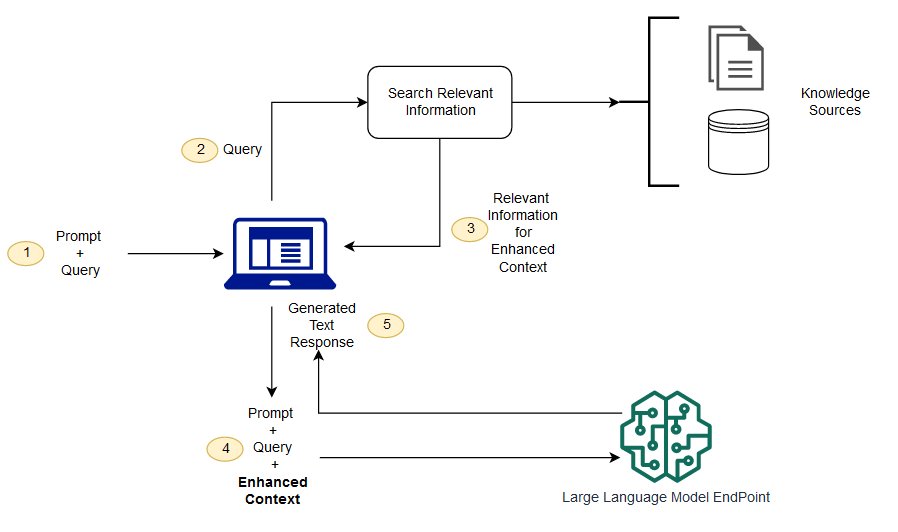
Có gì khác nhau giữa việc truy xuất sự tăng cường và tìm kiếm theo nghĩa khác nhau?
Việc tìm kiếm nghĩa có thể cải thiện kết quả RIG cho các tổ chức muốn thêm nhiều nguồn tri thức bên ngoài vào ứng Các doanh nghiệp hiện đại lưu trữ nhiều thông tin trên nhiều hệ thống khác nhau như cẩm nang, các vấn đề thường gặp, báo cáo nghiên cứu, hướng dẫn dịch vụ khách hàng và kho lưu trữ tài liệu nhân lực. Tra cứu ngữ cảnh mang tính thách thức về quy mô, do đó sẽ làm giảm chất lượng đầu ra.
Công nghệ tìm kiếm nghĩa: Bạn có thể quét các cơ sở dữ liệu lớn chứa các thông tin khác nhau và truy xuất dữ liê Ví dụ, họ có thể trả lời những câu hỏi như * "Năm ngoái tốn bao nhiêu tiền để sửa chữa cơ khí?" * Các vấn đề như thế bằng cách ánh xạ các câu hỏi tới các tài liệu liên quan và trở về một văn Sau đó, các nhà phát triển có thể sử dụng câu trả lời đó để cung cấp nhiều
Các nhà phát triển cũng phải xử lý việc nhúng từ, phân chia tài liệu và các vấn đề phức tạp khác khi chuẩn bị dữ liệu bằng tay. So với mọi công nghệ tìm kiếm nghĩa có thể hoàn thành tất cả các công việc mà kho kiến thức chuẩn bị, do đó các nhà phát triển không cần phải làm như vậy. Chúng cũng tạo ra các đoạn liên quan đến nghĩa và các từ đánh dấu được sắp xếp theo các tính phụ thuộc để cải thiện tối đa chất lượ
Ba thành phần cốt lõi của RG
Mô hình tăng cường tra cứu được tạo thành chủ yếu bởi ba thành phần cốt lõi:
- Bộ tra cứu (Retriever): chịu trách nhiệm truy xuất thông tin liên quan từ nguồn tri thức bên ngoài.
- Bộ sắp xếp (Rnkeer): Đánh giá kết quả tra cứu và sắp xếp ưu tiên.
- Trình tạo (Genator): Sử dụng kết quả tra cứu và sắp xếp, kết hợp nhập của người dùng để tạo ra câu trả lời
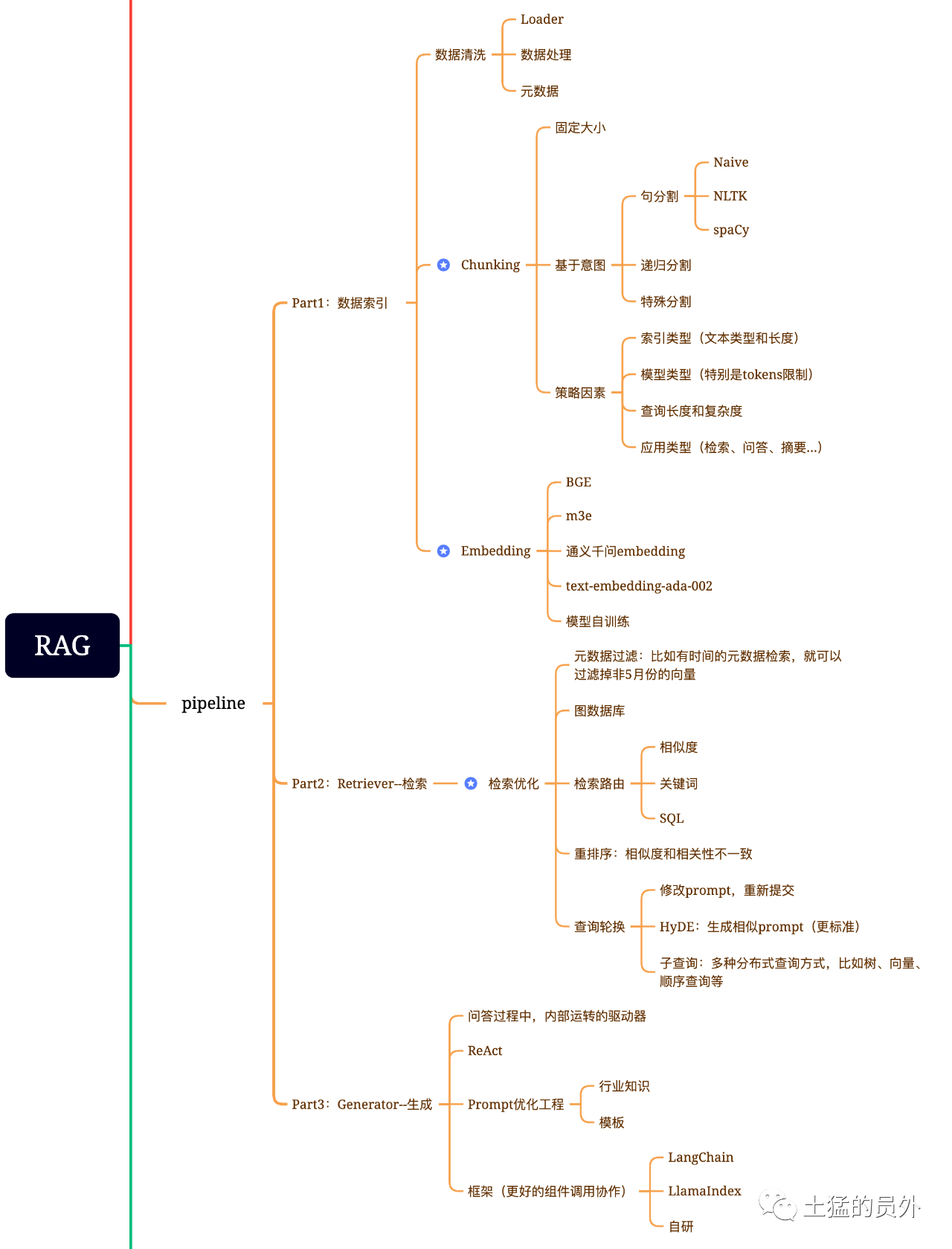
Biểu đồ não RG
Bản đồ này, rất chi tiết!
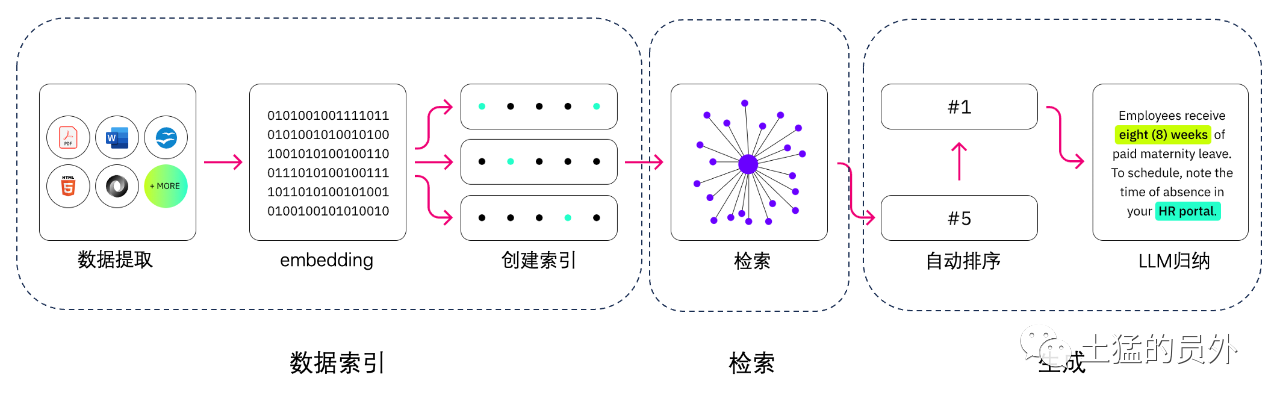
Chỉ mục dữ liệu
-** trích xuất dữ liệu *
- Một cuộc thanh lọc dữ liệu: bao gồm dữ liệu Loder, trích xuất PDF,word,markdon và cơ sở dữ liệu và API;
- Xử lý dữ liệu: bao gồm cả định dạng dữ liệu, không nhận diện được nội dung, nén và định dạng;
- Các trích xuất siêu dữ liệu: Trích xuất các thông tin như tên tệp, thời gian, các chương tittle, hình ảnh, v.v...
Công cụ trích xuất dữ
- Unstructure IO (đã dùng)
- Lalama Parse (đã dùng)
- Google Document AI.
- AWS Textract (AWS Textract)
- Pdf2 image + pytesct.
Về bình.
Sự tối ưu tra cứu thường được chia thành 5 phần làm việc dưới đây:
Trong thời gian này, nếu lọc qua siêu dữ liệu trước sẽ giúp tăng hiệu quả và độ tương quan. Ví dụ, chúng tôi đặt câu hỏi “Hãy giúp tôi sắp xếp lại tất cả các hợp đồng trong tháng 5 này của HĐXX, hợp đồng chứa thiết bị của HĐXX có những gì?” . Trong trường hợp này, nếu có siêu dữ liệu, chúng ta có thể tìm kiếm các dữ liệu liên quan đến “*XX + * tháng 5 năm 2023” để lấy lại số liệu có thể trở thành một phần vạn dữ liệu toàn cục;
-* Mối quan hệ tìm kiếm **: Nếu bạn có thể biến nhiều thực thể thành nude, biến mối quan hệ giữa chúng thành retion, bạn có thể sử dụng mối quan hệ của kiến thức để trả lời chính xác hơn. Đặc biệt là đối với một số vấn đề nhảy nhiều, việc sử dụng chỉ mục dữ liệu đồ họa sẽ làm cho độ liên quan của việc tra cứu trở nên cao hơn;
-** Công nghệ tra cứu **: Có một số phương pháp điều khiển trước, cách chính của việc truy xuất hay đây là:
-
- 相似度检索:前面我已经写过那篇文章《大模型应用中大部分人真正需要去关心的核心——Embedding》中有提到六种相似度算法,包括欧氏距离、曼哈顿距离、余弦等,后面我还会再专门写一篇这方面的文章,可以关注我,yeah; Việc lọc siêu dữ liệu mà chúng ta vừa nói là một loại, và một là hãy tóm tắt Chink trước, sau đó tra cứu bằng từ khóa để tìm ra các unk có thể liên quan, tăng hiệu quả tra cứu. Người ta nói rằng Clude.ai cũng làm như vậy;
-
- QL truy xuất **: Điều này càng trở nên truyền thống hơn, nhưng đối với một số ứng dụng của các doanh nghiệp địa phương, truy vấn QL là một bước rất cần thiết, ví dụ như số liệu bán hàng như tôi đã đề cập ở trên thì cần phải làm truy xuất QL trước.
- Các công nghệ khác: Công nghệ tra cứu còn rất nhiều, sử dụng ở phía sau đến khi nói từ từ.
Bởi sau bước này, chúng tôi sẽ trao kết quả cho LLM để xử lý cuối cùng nên kết quả của phần này rất quan trọng. Trong đó sẽ có một bộ đánh giá bên trong để thẩm định độ phụ thuộc và kích hoạt việc sắp xếp lại.
-** Một cách để truy vấn ***: Đó là một cách để truy vấn, và một số cách:
-
- Truy vấn con: * Có thể sử dụng các chính sách truy vấn khác nhau trong các khung khác nhau, chẳng hạn như có thể sử dụng các bộ truy vấn được cung cấp từ khung của Lalama Index, sử dụng các truy vấn cây (từ các điểm kết nối lá, từng bước, kết hợp), sử dụng các truy vấn theo số lượng, hoặc thứ tự truy vấn gốc nhất, v.v *; **
♪
- R-Rk.
Hầu hết các cơ sở dữ liệu đo lường để tính toán hiệu quả sẽ hy sinh một mức độ chính xác nhất định. Điều này khiến kết quả tra cứu tồn tại một sự ngẫu nhiên nhất định, không nhất thiết phải có sự liên quan nào đó giữa các TopK trở về ban đầu.
使用BAAI/bge-reranker-base、BAAI/bge-reranker-large等开源模型来完成Re-Rank操作。
Ngoài ra còn có sự góp mặt của Beyonce-Reranker-base trên mạng, hỗ trợ cho Trung Quốc sang Hàn Quốc.
Thu hồi/ tra cứu hỗn hợp
Truy vấn đôi:
- Thu hồi cơ sở dữ liệu theo nghĩa *
- Truy xuất từ khóa ( KeywordSearch) / Từ khóa để lấy cuộc thu hồi
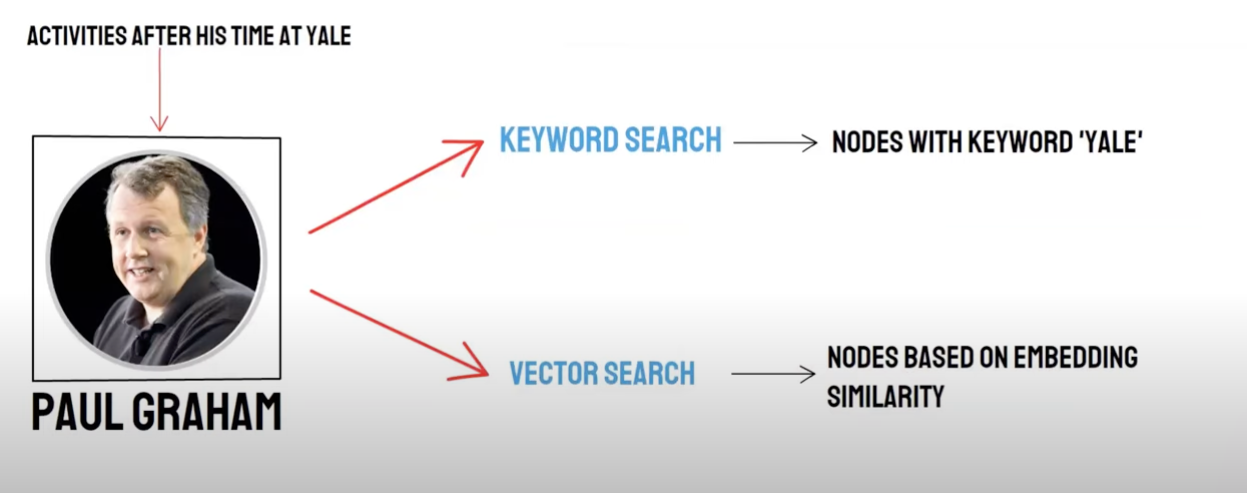
Việc thu hồi cơ sở dữ liệu và từ khóa lấy lại từ khóa có những lợi thế và thiếu sót riêng, nhờ vậy việc tổng hợp kết quả thu hồi có thể nâng cao tính chính xác và hiệu quả của việc tra cứu tổng thể. Việc sắp xếp vát (Recprocal Rucion, RRF) tính toán tổng số điểm sau khi hỗ trợ bằng cách kết hợp với mỗi tài liệu trong các phương pháp thu hộp khác nhau.
Khi bạn chọn sử dụng từ khóa để lấy lại sự thu hồi, tức * * Keyiword Retrival* ** * *) *, PAI sẽ được mặc định sử dụng thuật toán RRF để tiến hành thu hồi đa đường đối với kết quả thu hồi cơ sở dữ liệu đo lường và kết quả thu hồi từ khóa.
Tạo ra
Khung thành có sự góp mặt của Langchain và Lalama Index
Các phương án đếm lúa kỹ thuật
Khung
Cái khó là: text-to-sql là gì?
Chia văn bản:
Tách văn bản: Chia tài liệu thành các khối nhỏ hơn để dễ dàng cho việc làm văn bản tiếp theo là Embedding, và thuận tiện cho việc tra cứu tài liệu tiếp theo.
Trường hợp lý tưởng: Đặt các đoạn văn bản liên quan đến nghĩa với nhau theo thứ tự.
- Phương pháp tách ra * *
- Theo quy định: (cách đơn giản nhất) để tách tài liệu theo câu. Chia tài liệu dựa trên các ký hiệu chấm dứt thông thường bằng tiếng Trung và tiếng Anh, chẳng hạn như dấu chấm dứt ký tự đơn, dấu tiết kiệm tiếng Anh, mã số kép, v.v...
- Theo nghĩa đen:
- Đầu tiên dựa trên quy tắc để tách tài liệu thành các khối tài liệu ở cấp độ câu
-
- Mô hình tách văn bản dựa trên nghĩa * *
Mô hình này dựa trên cửa sổ trượt dựa trên cửa sổ trượt
Định lượng văn bản: Chọn mô hình Embedding
Mô hình BBA của Nguồn thông minh (Bge-base-zh) hoặc được lựa chọn từ tấm gương MTEB.
Lưu trực tiếp
-
Dùng cá nhân.
-
Milivus: Cấp độ sản xuất
Dựa trên câu hỏi sử dụng các điểm kiến thức phù hợp với lượng
Top_k
Faiss: Tìm kiếm mở rộng gần kết quả tìm kiếm để tìm các tài liệu tương tự nhỏ hơn chunk_size (thường là 500 từ)
Milivus: topk tra cứu + Bge-base-zh+ các mô hình kết hợp giống đoạn
Ý tưởng: Phân tích ý tưởng tra cứu mở rộng dựa trên topk tra cứu, chúng tôi thấy rằng chủ yếu là thông qua các đoạn nghĩa mở rộng để các mô hình lớn tiếp cận càng nhiều thông tin hữu ích để nâng cao hiệu quả trả lời khi trả lời càng nhiều càng tốt.
Ý tưởng:
- Đầu tiên dựa trên quy tắc để tách tài liệu thành các khối tài liệu ở cấp độ câu
- Sau đó sử dụng mô hình để tích hợp các khối tài liệu dựa trên nghĩa, cuối cùng là khối tài liệu dựa trên nghĩa
- Thứ tự một lần nữa cho các tài liệu sử dụng mô hình mbedding, được gắn kết lại với độ tương đương nghĩa, tương ứng với hai lần tập hợp tài liê
Xây dựng một Prompt
你现在是一个智能助手了,现在需要你根据已知内容回答问题
已知内容如下:
"{context}"
通过对已知内容进行总结并且列举的方式来回答问题:"{question}",在答案中不能出现问题内容,并且不允许编造内容,并且使用简体中文回答。
如果该问题和已知内容不相关,请回答 "根据已知信息无法回答该问题" 或 "没有提供足够的相关信息"。
Tạo ra câu trả lời:chọn LLM
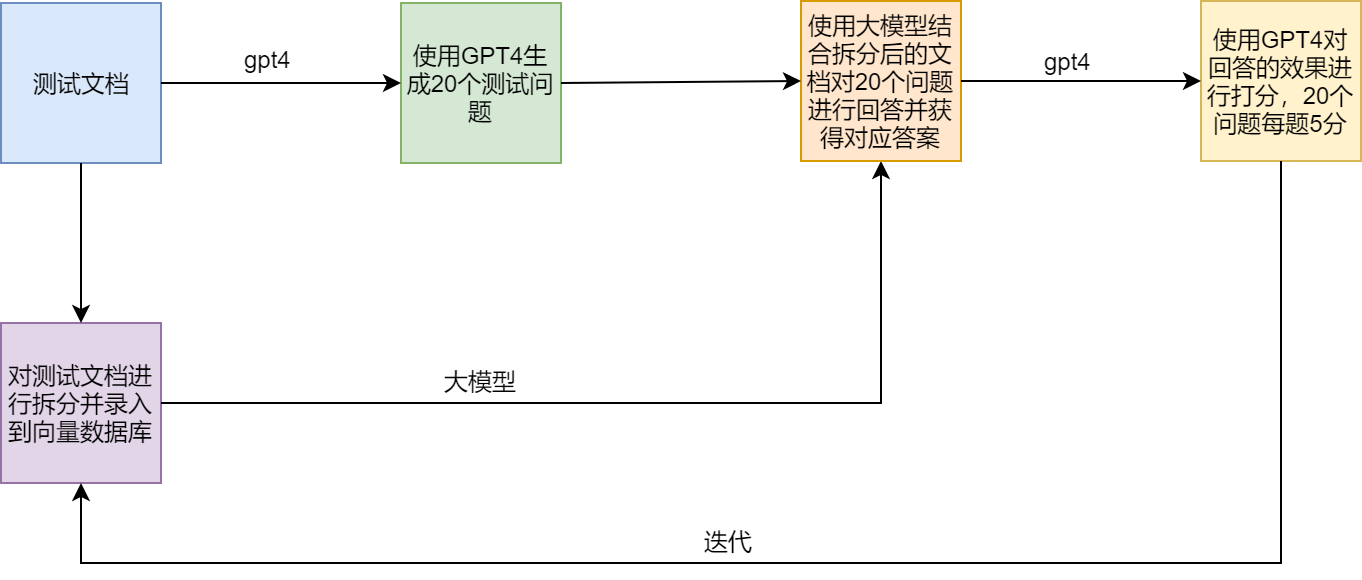
Phương án thử nghiệm
Những điểm đau và giải pháp của RG

các ví dụ điển hình
LamaIndex官方提供了一个范例(SEC Insights),用来展示高级查询技术