Indice Llama
Version Python et Typescript
La version Python de la documentation est plus complète, TS est relativement pauvre?
INTRODUCTION
Créer un environnement
conda create --name llamaindex python=3.9.19
conda activate llamaindex
-
- définir l'environnement Conda dans VSCode * *
Python: Select Interpreter
Bibliothèque d'installation
pip install llama-index pypdf sentence_transformers
Configurer OpenAI
vim ~/.bashrc
Ajouter une variable d'environnement
export OPENAI_API_KEY="sk-xxxx"
Vérification
echo $OPENAI_API_KEY
-
- accessibilité * *
Configurer: goproxy sur la ligne de commande
Quick Start
import os.path
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
import logging
import sys
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
# check if storage already exists
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):
# load the documents and create the index
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# store it for later
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
# load the existing index
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
# either way we can now query the index
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
-
- méthode de complétion utilisée * *
/chat/completions
-
- paramètres de la requête * *
{
"messages": [
{
"role": "system",
"content": "You are an expert Q&A system that is trusted around the world.\nAlways answer the query using the provided context information, and not prior knowledge.\nSome rules to follow:\n1. Never directly reference the given context in your answer.\n2. Avoid statements like \"Based on the context, ...\" or \"The context information ...\" or anything along those lines."
},
{
"role": "user",
"content": "xxx"
}
],
"model": "gpt-3.5-turbo",
"stream": false,
"temperature": 0.1
}
-
- invite du système * *
You are an expert Q&A system that is trusted around the world.
Always answer the query using the provided context information, and not prior knowledge.
Some rules to follow:
1. Never directly reference the given context in your answer.
2. Avoid statements like "Based on the context, ..." or "The context information ..." or anything along those lines.
Vous êtes un système de questions et réponses expert de confiance partout dans le monde. Lorsque vous répondez à des questions, utilisez toujours les informations de base fournies, plutôt que les connaissances antérieures. Quelques règles à suivre:
- Ne jamais se référer directement à l'information de base donnée dans la réponse.
- évitez d'utiliser « basé sur des informations de base, … » Ou "l'information de base indique que..." Ou quelque chose comme ça.
-
- invite de l'utilisateur * *
Context information is below.
---------------------
file_path: data/paul_graham_essay.txt
xxx
---------------------
Given the context information and not prior knowledge, answer the query.
Query: What did the author do growing up?
Answer:
Scénario d'application
| 应用场 | 说明 |
|---|---|
| Q&A | 最重要 |
| Chatbots | |
| Agents | 高级 |
| Structured Data Extraction | 有用,整理聊天记录等 |
| Multi-modal |
Principes de base
Processus de base
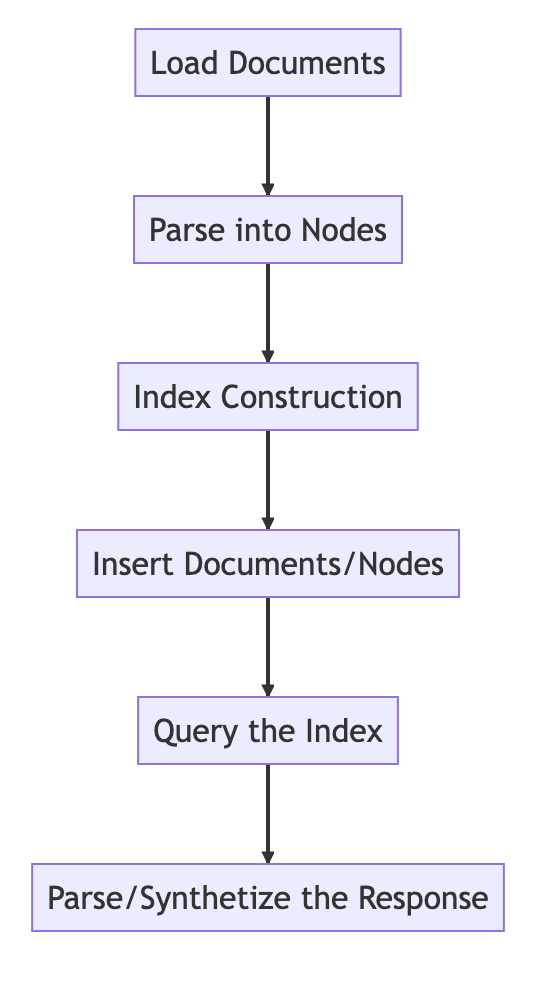
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# Load in data as Document objects
documents = SimpleDirectoryReader('data').load_data()
# 切片,转成Node
# Parse Document objects into Node objects to represent chunks of data
index = VectorStoreIndex.from_documents(documents)
# Index Construction:创建索引
# Build an index over the Documents or Nodes
query_engine = index.as_query_engine()
# The response is a Response object containing the text response and source Nodes
summary = query_engine.query("What is the text about")
print("What is the data about:")
print(summary)
Chunking et Node
Source data- > documents-- > nœuds
Documents: contient des informations sur le corps et les méta-informations
ID du document
Le document est en fait une sous-classe de Node
il est étrange qu'un fichier soit découpé en plusieurs documents.
TextNode: utilisez NodeParser pour couper le document en plusieurs nœuds
inclure l'ID du document
il y avait un lien entre Node et Node
- NodeParser reçoit une liste d'objets Document
- En utilisant la segmentation de phrase de spaCy, le texte de chaque document est divisé en phrases.
- Chaque phrase est enveloppée dans un objet TextNode qui représente un nœud
- TextNode contient du texte de phrase, ainsi que des métadonnées, telles que l'ID du document, l'emplacement dans le document, etc.
- Retourne une liste d'objets TextNode.
Enregistrer le document et l'index
De deux manières
-Défendre sur le disque local -base de données de stockage à vecteur
-
- enregistrer sur le disque local * *
import os.path
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
import sys
# check if storage already exists
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):
# 保存数据: Load the documents and create the index
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# store it for later
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
# 从磁盘加载回数据: load the existing index
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
Construire un index
Créer une intégration pour chaque nœud
Créer un index dans VectorStroreIndex
- Pour VectorStoreIndex, l'intégration de texte sur le nœud est stockée dans l'index FAISS, et la recherche de similarité peut être effectuée rapidement sur le nœud.
- L'index stocke également les métadonnées sur chaque nœud, telles que l'ID du document, l'emplacement, etc.
- Un nœud peut récupérer le contenu d'un document ou d'un document spécifique.
Index des requêtes
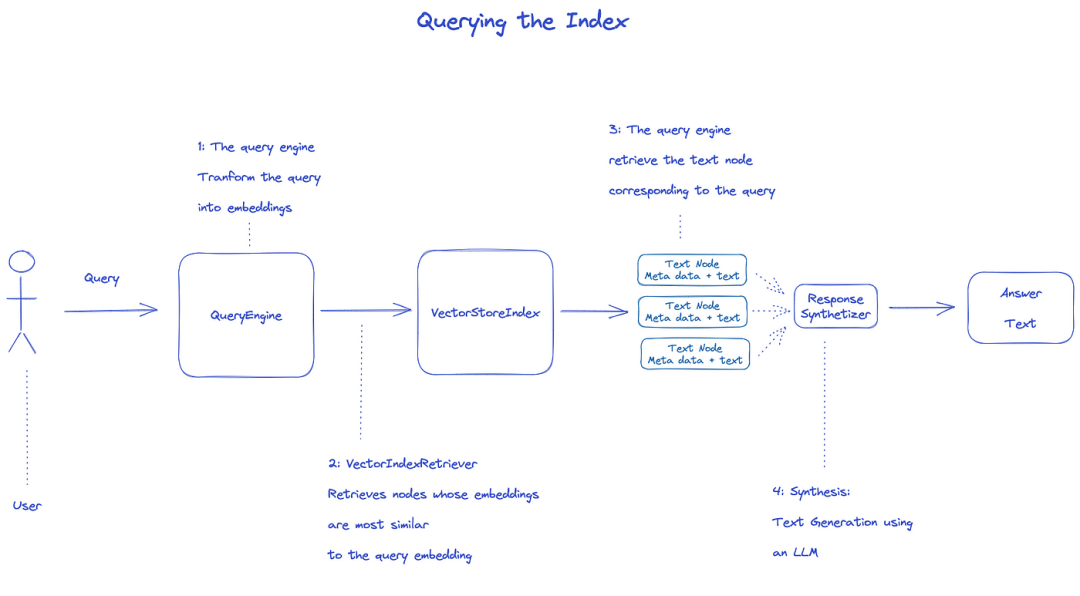
pour interroger l'index, QueryEngine sera utilisé.
- Retriever obtient les nœuds pertinents à partir de l'index de la requête. Par exemple, VectorIndexRetriever récupère le nœud dont l'intégration est la plus similaire à l'intégration de requêtes
- La liste récupérée des nœuds est passée à ResponseSynthesizer pour générer la sortie finale
- Par défaut, ResponseSynthesizer traite chaque nœud séquentiellement, et chaque nœud appelle l'API LLM une fois
- Entrée LLM requête et texte de noeud pour obtenir la sortie finale
- Les réponses de chacun de ces nœuds sont agrégées dans la chaîne de sortie finale.
from llama_index import (
VectorStoreIndex,
get_response_synthesizer,
)
from llama_index.retrievers import VectorIndexRetriever
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.postprocessor import SimilarityPostprocessor
from llama_index import StorageContext, load_index_from_storage
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir="storage")
# load index
index = load_index_from_storage(storage_context)
# configure retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=10,
)
# configure response synthesizer
response_synthesizer = get_response_synthesizer()
# assemble query engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
node_postprocessors=[SimilarityPostprocessor(similarity_cutoff=0.7)],
)
# query
response = query_engine.query("What did the author do growing up?")
print(response)
Document officiel: Understanding
-
- trois processus de traitement des données * *
Les pipelines de nettoyage de données / d'ingénierie des fonctionnalités dans le monde ML, ou les pipelines ETL dans le cadre de données traditionnel.
Ce pipeline d'ingestion se compose généralement de trois étapes principales:
- Charger les données
- Transformer les données
- Indexer et stocker les données
Données de charge (ingestion)
-
- objectif: * * formater différents types de données en objets « documents ».
-
- entrée: * * différents types de données
-
- sortie: * *
objet document
- sortie: * *
-
- 3 façons * *
-Utilisez la classe SimpleDirectoryReader: la plus pratique
-Reader 'dans LlamaHub`: divers outils qui ont été écrits
-créer directement le « document »
-
SimpleDirectoryReaderclasse * *
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
support Markdown, PDF, documents Word (.docx), decks PowerPoint, images (.jpg, .png), audio et vidéo
-
- Llamahub * *
- Notion (
NotionPageReader) - Google Docs (
GoogleDocsReader) - Slack (
SlackReader) - Discord (
DiscordReader) - Apify Actors (
ApifyActor). Can crawl the web, scrape webpages, extract text content, download files including.pdf,.jpg,.png,.docx, etc.这个可以爬虫
-
- créer le document * * directement
from llama_index.schema import Document
doc = Document(text="text")
Transformer les données (transformations)
-
- raison: * * récupération pratique et utilisation efficace du LLM
-
- opérations spécifiques: * *
-fragment « document » (découpage) Extraire les métadonnées (extraction des métadonnées) -Embedding
-
- entrée: * * `Node'
-
- sortie: * * `Node'
API encapsulée
Utiliser la méthode VectorStoreIndex from _ documents ()
from llama_index import VectorStoreIndex
vector_index = VectorStoreIndex.from_documents(documents)
vector_index.as_query_engine()
-
- comment personnaliser les paramètres * *
Idée: utilisez « ServiceContext» pour personnaliser
text_splitter = SentenceSplitter(chunk_size=512, chunk_overlap=10)
service_context = ServiceContext.from_defaults(text_splitter=text_splitter)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
API atomique
Mode d'utilisation standard
from llama_index import Document
from llama_index.embeddings import OpenAIEmbedding
from llama_index.text_splitter import SentenceSplitter
from llama_index.extractors import TitleExtractor
from llama_index.ingestion import IngestionPipeline, IngestionCache
# 加载数据源
documents = SimpleDirectoryReader("./data").load_data()
# 创建转换数据的工作流
# create the pipeline with transformations
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=25, chunk_overlap=0), # 分片
TitleExtractor(), # 提取Meta信息
OpenAIEmbedding(), # Embedding
]
)
# 执行流程,生成节点
# run the pipeline
nodes = pipeline.run(documents=documents)
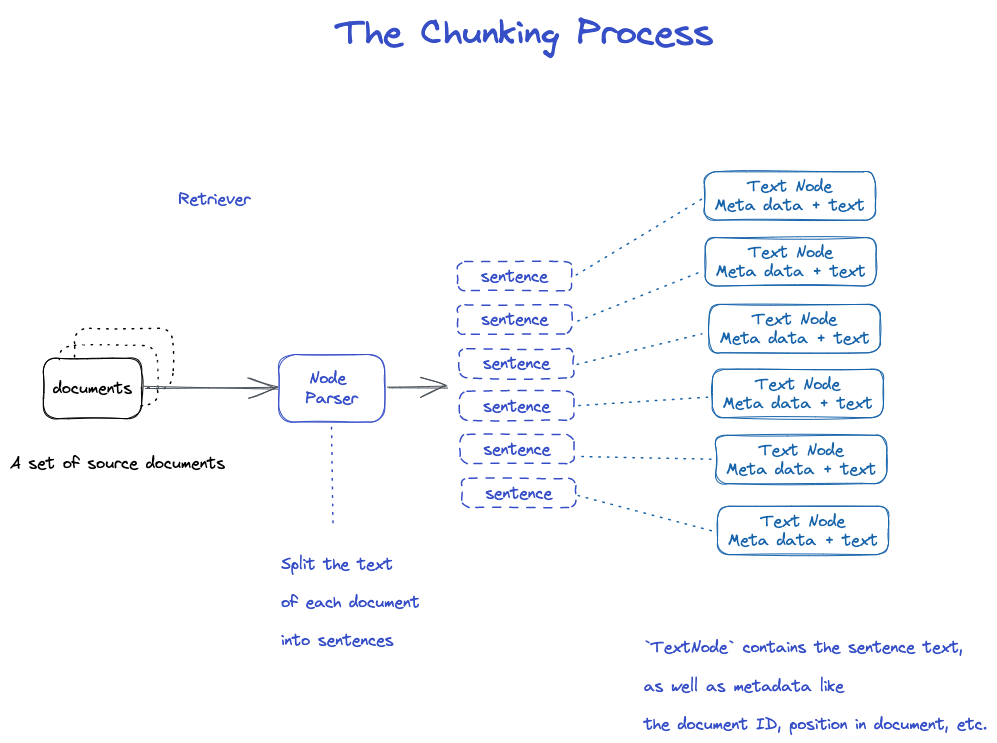
Tranche
Il existe de nombreuses stratégies, comme spécifié dans le module Node Parser.
Ajouter des métadonnées
Vous pouvez personnaliser le document et le nœud pour ajouter des métadonnées.
Créer un objet Node directement
from llama_index.schema import TextNode
node1 = TextNode(text="<text_chunk>", id_="<node_id>")
node2 = TextNode(text="<text_chunk>", id_="<node_id>")
index = VectorStoreIndex([node1, node2])
Index
-
- classement de l'indice * *
- Vector Stores
- Document Stores
- Index Stores
- Key-Value Stores
- Using Graph Stores -[Chat stores] (
-
- indices communs * *
-Index sommaire (anciennement List Index) -Vector Store Index (le plus commun) -Index des arbres -Index de la table des mots clés
-
- Index sommaire (anciennement Index Liste) * *

-
- Vector Store Index * *

-
- Indice des arbres * *

-
- Index des tables de mots clés * *

- VectorStoreIndex
- Summary Index
- Tree Index
- Keyword Table Index
- Knowledge Graph Index
- Custom Retriever combining KG Index and VectorStore Index
- Knowledge Graph Query Engine
- Knowledge Graph RAG Query Engine
- REBEL + Knowledge Graph Index
- REBEL + Wikipedia Filtering
- SQL Index
- SQL Query Engine with LlamaIndex + DuckDB
- Document Summary Index
- The
ObjectIndexClass
-https: / / docs.llamaindex.ai / fr / stable / module _ guides / storing / chat _ stores.html)
Méta
Ajouter un méta
document.metadata['lang'] = lang
Filtre
from llama_index.core.vector_stores import (
ExactMatchFilter,
MetadataFilters,
MetadataFilter,
)
filters = MetadataFilters(
filters=[
MetadataFilter(key="post_year", value="2017"),
],
)
# You pass filter as an argument. You can have any type of filter
# we saw above and then pass it to query engine.
query_engine = index.as_query_engine(service_context=service_context,
similarity_top_k=5,
filters = filters,
response_mode='tree_summarize')
response = query_engine.query("Marathon Running")
print(response)
Modes de réponse
-raffiner: générer des réponses une par une avec le contexte; utilisez d'abord le template text _ qa _ template, puis utilisez le template Refinate _ template. -compact: par défaut. Semblable à raffiner, cependant, le contexte est bourré d'une demande. -tree _ summary -Récapitulatif _ simple
Code source
Document
un
Documentest une sous-classe d'un `Node')
Contient:
-le texte
-< < métadate > >
-roomships: relation avec d'autres documents / nœuds
-
- processus d'utilisation atomique * *
from llama_index import Document, VectorStoreIndex
# 数据源
text_list = [text1, text2, ...]
# 手动创建documents
documents = [Document(text=t) for t in text_list]
# 建立索引: 传入document,在VectorStoreIndex再转换:分片转成Node,Embedding等
index = VectorStoreIndex.from_documents(documents)
Plusieurs méthodes de création de document
-
- créer manuellement * *
from llama_index import Document
text_list = [text1, text2, ...]
documents = [Document(text=t) for t in text_list]
-
- utiliser le chargeur de données (connecteur) * *
Ils ont tous une méthode load _ data ()
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
-
- données d'échantillon générées automatiquement * *
document = Document.example()
Méta personnalisé
from llama_index import Document
from llama_index.schema import MetadataMode
document = Document(
text="This is a super-customized document",
metadata={
"file_name": "super_secret_document.txt",
"category": "finance",
"author": "LlamaIndex",
},
excluded_llm_metadata_keys=["file_name"],
metadata_seperator="::",
metadata_template="{key}=>{value}",
text_template="Metadata: {metadata_str}\n-----\nContent: {content}",
)
print(
"The LLM sees this: \n",
document.get_content(metadata_mode=MetadataMode.LLM),
)
print()
print(
"The Embedding model sees this: \n",
document.get_content(metadata_mode=MetadataMode.EMBED),
)
Produit
The LLM sees this:
Metadata: category=>finance::author=>LlamaIndex
-----
Content: This is a super-customized document
The Embedding model sees this:
Metadata: file_name=>super_secret_document.txt::category=>finance::author=>LlamaIndex
-----
Content: This is a super-customized document
Modèle d'utilisation de l'extraction de métadonnées (je ne comprends pas)
Noeud
Essence: fragmentation du document
Comment obtenir:
-Utiliser la classe NodeParser pour convertir le document en nœud -créer manuellement
Comme document, il y a:
-le texte
-< < métadate > >
-roomships: relation avec d'autres documents / nœuds
Lors de la conversion de document en nœud, des informations telles que les métadonnées sont héritées.
Node est un citoyen de première classe dans LlamaIndex.
-
- processus d'utilisation atomique * *
from llama_index.node_parser import SentenceSplitter
# load documents
...
# 手动转换:切片,转成Node
# parse nodes
parser = SentenceSplitter()
nodes = parser.get_nodes_from_documents(documents)
# build index
index = VectorStoreIndex(nodes)
-
- établir une relation * *
from llama_index.schema import TextNode, NodeRelationship, RelatedNodeInfo
node1 = TextNode(text="text_chunk1", id_="node_id1")
node2 = TextNode(text="text_chunk2", id_="node_id2")
node3 = TextNode(text="text_chunk3", id_="node_id3")
# set relationships
node1.relationships[NodeRelationship.NEXT] = RelatedNodeInfo(
node_id=node2.node_id
)
node2.relationships[NodeRelationship.PREVIOUS] = RelatedNodeInfo(
node_id=node1.node_id
)
node2.relationships[NodeRelationship.PARENT] = RelatedNodeInfo(
node_id=node3.node_id, metadata={"key": "val"}
)
print(node2)
NodeParser
Objectif: convertir des sources de données en objets Node
Spécifique: fragmenter un groupe d'objets de document en plusieurs objets Node
Mise en œuvre concrète commune
NodeParser est une classe abstraite, qui est implémentée comme suit:
-
- par type de fichier * *
SimpleFileNodeParser -HTMLNodeParser -JSONNodeParser -MarkdownNodeParser
-
- segmentation du texte * *
-CodeSplitter -LangchainNodeParser SentenceSplitter -EntenceWindowNodeParser (je ne comprends pas) -SemanticSplitterNodeParser (je ne comprends pas, c'est plus avancé) -TokenTextSplitter
-
- relation père-fils * *
-HierarchicalNodeParser: utilisé dans AutoMergingRetriever
Utilisation typique
-
- utilisation atomique * *
from llama_index import Document
from llama_index.node_parser import SentenceSplitter
# 创建NodeParser
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
# 调用 get_nodes_from_documents() 方法
# show_progress 可以显示进度
nodes = node_parser.get_nodes_from_documents(
[Document.example(), Document.example()], show_progress=True
)
print(len(nodes))
print()
print(nodes[0])
Produit
2
Node ID: eaeb6e44-6828-4e36-b7a3-69342de4dc7c
Text: Context LLMs are a phenomenal piece of technology for knowledge
generation and reasoning. They are pre-trained on large amounts of
publicly available data. How do we best augment LLMs with our own
private data? We need a comprehensive toolkit to help perform this
data augmentation for LLMs. Proposed Solution That's where LlamaIndex
comes in. Ll...
-
- transformations * * dans Pipline
from llama_index import Document
from llama_index.node_parser import SentenceSplitter
from llama_index.ingestion import IngestionPipeline
from llama_index.node_parser import TokenTextSplitter
documents = [Document.example(), Document.example()]
# 创建NodeParser
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
# 将NodeParser放到Pipeline中的transformations列表
pipeline = IngestionPipeline(transformations=[node_parser])
nodes = pipeline.run(documents=documents)
print(len(nodes))
print()
print(nodes[0])
-
- utiliser ServiceContext * *
from llama_index import Document, ServiceContext, VectorStoreIndex
from llama_index.node_parser import SentenceSplitter
from llama_index.ingestion import IngestionPipeline
from llama_index.node_parser import TokenTextSplitter
documents = [Document.example(), Document.example()]
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
service_context = ServiceContext.from_defaults(text_splitter=node_parser)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context, show_progress=True
)
Transformations
Entrée: un ensemble de nœuds
Sortie: un ensemble de nœuds
Il y a deux façons communes:
-_ _ call _ _ (): synchroniser
-`Asynchrone () ': acall
NodeParser et `MetadataExtractor 'appartiennent aux transformations
-
- mode d'utilisation * *
from llama_index.text_splitter import SentenceSplitter
from llama_index.extractors import TitleExtractor
node_parser = SentenceSplitter(chunk_size=512)
extractor = TitleExtractor()
# use transforms directly
nodes = node_parser(documents)
# or use a transformation in async
nodes = await extractor.acall(nodes)
-
- combiné avec ServiceContext * *
from llama_index import ServiceContext, VectorStoreIndex
from llama_index.extractors import (
TitleExtractor,
QuestionsAnsweredExtractor,
)
from llama_index.ingestion import IngestionPipeline
from llama_index.text_splitter import TokenTextSplitter
transformations = [
TokenTextSplitter(chunk_size=512, chunk_overlap=128),
TitleExtractor(nodes=5),
QuestionsAnsweredExtractor(questions=3),
]
# 创建ServiceContext,传入Transfrmation
service_context = ServiceContext.from_defaults(
transformations=[text_splitter, title_extractor, qa_extractor]
)
# 传入VectorStoreIndex的from_documents()或insert()方法
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
ServiceContext
un ensemble de services et de configurations utilisés sur un pipeline LlamaIndex.
-
- peut être configuré * *
from llama_index import (
ServiceContext,
OpenAIEmbedding,
PromptHelper,
)
from llama_index.llms import OpenAI
from llama_index.text_splitter import SentenceSplitter
# 设置LLM
llm = OpenAI(model="text-davinci-003", temperature=0, max_tokens=256)
# 设置Embedding模型
embed_model = OpenAIEmbedding()
# 设置Chunk的大小
text_splitter = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
prompt_helper = PromptHelper(
context_window=4096,
num_output=256,
chunk_overlap_ratio=0.1,
chunk_size_limit=None,
)
service_context = ServiceContext.from_defaults(
llm=llm, # 设置LLM
embed_model=embed_model, # 设置Embedding模型
text_splitter=text_splitter, # 设置Chunk的大小
prompt_helper=prompt_helper,
)
-
- paramètres du constructeur * * (plus pratique)
-
- Kwargs pour l'analyseur de nœuds * *:
-Chunk _ size ' -chevauchement de _ morceaux
-
- Kwargs pour prompt Helper * *:
-< < fenêtre > >: < < fenêtre > >: -Num _ output '
Par exemple,
service_context = ServiceContext.from_defaults(chunk_size=1000)
-
- configuration globale * *
from llama_index import set_global_service_context
set_global_service_context(service_context)
-
- configuration locale * *
query_engine = index.as_query_engine(service_context=service_context)
StorageContext
Définit le backend de stockage pour l'endroit où les documents, les intégrations et les index sont stockés.
[référence API] (https: / / docs.llamaindex.ai / fr / stable / API _ reference /)
store = PGVectorStore(
connection_string=conn_string,
async_connection_string=async_conn_string,
schema_name=PGVECTOR_SCHEMA,
table_name=PGVECTOR_TABLE,
)
index = VectorStoreIndex.from_vector_store(store)
Indice VectorStoreIndex
Fonction du constructeur
index = VectorStoreIndex.from_vector_store(store)
Il existe deux types de moteurs:
- Query Engine: BaseQueryEngine
- Chat Engines: BaseChatEngine
Créer le moteur
index.as_query_engine()# BaseQueryEngine
index.as_query_engine(streaming=True)# 流式 BaseQueryEngine
index.as_chat_engine() # BaseChatEngine; 流式不是在这里控制
Requête
# Query
response = await query_engine.aquery(query) # 流式
response = await query_engine.aquery(query)
# Chat
response = await chat_engine.astream_chat(last_message_content, messages) # 流式在这里控制
response = await chat_engine.achat(last_message_content, messages)
BaseQueryEngine
-Query -aquerie
BaseChatEngine
-Chat -stream _ chat -achat -astream _ chat
supporte le streaming: Stream
l'asynchrone est supportée: en commençant par un
Type de réponse
# Query
RESPONSE_TYPE = Union[
Response,
StreamingResponse, AsyncStreamingResponse, #流式
PydanticResponse
]
# Chat
StreamingAgentChatResponse #流式
AGENT_CHAT_RESPONSE_TYPE = Union[AgentChatResponse, StreamingAgentChatResponse] #非流式
Comment faire face à la réponse de streaming
utilisez les API standard de Python:
-StreamingResponse () -AsyncStreamingResponse -RéponseStreamingResponse
-Query
@r.post("")
async def chat(
request: Request,
queryData: _QueryData,
query_engine: BaseQueryEngine = Depends(get_query_engine_stream),
):
query = queryData.query
streaming_response = await query_engine.aquery(query)
async def event_generator():
async for token in streaming_response.async_response_gen:
if await request.is_disconnected():
break
yield f"data: {token}\n\n"
return StreamingResponse(event_generator(), media_type="text/event-stream")
-Chat
@r.post("")
async def chat(
request: Request,
data: _ChatData,
chat_engine: BaseChatEngine = Depends(get_chat_engine),
):
last_message_content, messages = await parse_chat_data(data)
response = await chat_engine.astream_chat(last_message_content, messages)
async def event_generator():
async for token in response.async_response_gen():
if await request.is_disconnected():
break
yield token
return StreamingResponse(event_generator(), media_type="text/plain")
StreamingResponse
class AsyncStreamingResponse:
async_response_gen: TokenAsyncGen
class StreamingResponse:
response_gen: TokenGen
Modes de réponse
Surveillance et contrôle
Tutoriels
Tutoriel Deeplearn
Building and Evaluating Advanced RAG Applications:链接 Bilibili
-
- texte joint à SQL et recherche sémantique * *
Cette vidéo couvre les outils intégrés à LlamaIndex pour combiner la recherche SQL et sémantique dans une seule interface de requête unifiée.