Índice de lama
Versão em Python e typeScript
A versão Python da documentação é mais completa, o TS é relativamente pobre?
Introdução
Criar um ambienteName
conda create --name llamaindex python=3.9.19
conda activate llamaindex
*** Configura o ambiente em VSCode ***
Python: Select Interpreter
Biblioteca de instalação
pip install llama-index pypdf sentence_transformers
Configurar o OpenAIName
vim ~/.bashrc
Adicionar a variável do ambiente
export OPENAI_API_KEY="sk-xxxx"
Verificação
echo $OPENAI_API_KEY
*** Acessibilidade ***
Configurar: goproxy na linha de comandos
Iniciação rápida
import os.path
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
import logging
import sys
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
# check if storage already exists
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):
# load the documents and create the index
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# store it for later
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
# load the existing index
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
# either way we can now query the index
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
** Método de conclusão utilizado **
/chat/completions
** Parâmetros de pesquisa **
{
"messages": [
{
"role": "system",
"content": "You are an expert Q&A system that is trusted around the world.\nAlways answer the query using the provided context information, and not prior knowledge.\nSome rules to follow:\n1. Never directly reference the given context in your answer.\n2. Avoid statements like \"Based on the context, ...\" or \"The context information ...\" or anything along those lines."
},
{
"role": "user",
"content": "xxx"
}
],
"model": "gpt-3.5-turbo",
"stream": false,
"temperature": 0.1
}
*** Interrupção do sistema ***
You are an expert Q&A system that is trusted around the world.
Always answer the query using the provided context information, and not prior knowledge.
Some rules to follow:
1. Never directly reference the given context in your answer.
2. Avoid statements like "Based on the context, ..." or "The context information ..." or anything along those lines.
És um especialista de confiança no sistema de perguntas e respostas em todo o mundo. Ao responder a perguntas, utilize sempre a informação de base fornecida, em vez de conhecimentos anteriores. Algumas regras a seguir:
1 . > 1 . Nunca faça referência directa à informação de base dada na resposta. 2 . > 2 . Evitar utilizar "com base em informações de base, ...". Ou "informações de fundo indicam que..." Ou algo do género.
*** Interrupção de utilizador ***
Context information is below.
---------------------
file_path: data/paul_graham_essay.txt
xxx
---------------------
Given the context information and not prior knowledge, answer the query.
Query: What did the author do growing up?
Answer:
Cenário de aplicação
| 应用场 | 说明 |
|---|---|
| Q&A | 最重要 |
| Chatbots | |
| Agents | 高级 |
| Structured Data Extraction | 有用,整理聊天记录等 |
| Multi-modal |
PRINCÍPIOS DE BASE
Processo básico de base
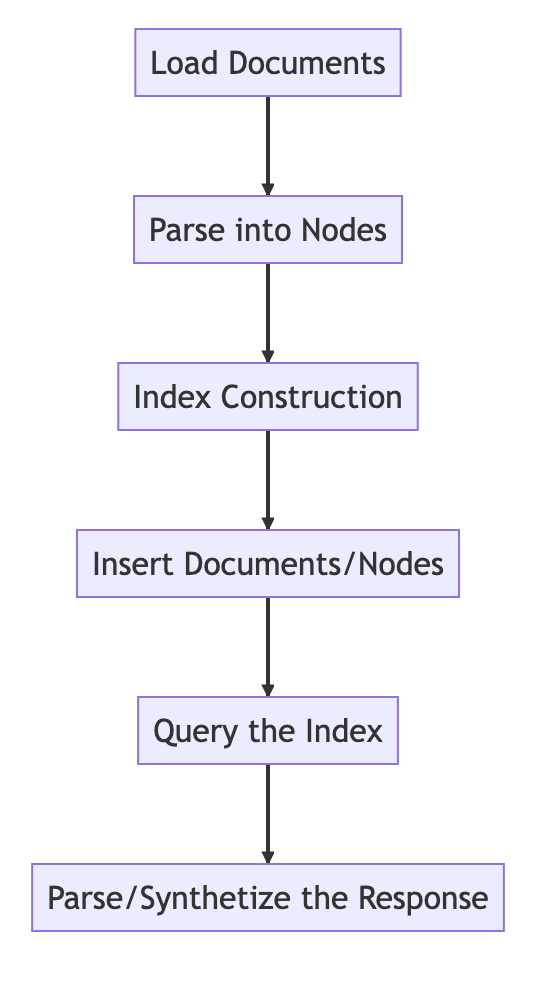
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# Load in data as Document objects
documents = SimpleDirectoryReader('data').load_data()
# 切片,转成Node
# Parse Document objects into Node objects to represent chunks of data
index = VectorStoreIndex.from_documents(documents)
# Index Construction:创建索引
# Build an index over the Documents or Nodes
query_engine = index.as_query_engine()
# The response is a Response object containing the text response and source Nodes
summary = query_engine.query("What is the text about")
print("What is the data about:")
print(summary)
O CHUNKING E NODE
Dados de origem - > documentos - > nós
Documentos: contém o organismo e meta informação
ID do documento
document é na verdade uma subclasse de Node
É estranho que um ficheiro seja cortado em muitos documentos.
Número de Texto: usar o NodeParser para cortar o documento em vários Nó
Incluir o ID do documento
Havia uma ligação entre o Node e o Node
- O NodeParser recebe uma lista de objectos do documento 2 . > 2 . Usando a segmentação da sentença de Spacy, o texto de cada documento é dividido em frases. 3 . > 3 . Cada frase é embrulhada num objecto TextNode que representa um nó
- O TextNode contém texto de frase, bem como metadados, tais como ID do documento, localização no documento, etc. 5 . > 5 . Devolve uma lista de objectos do TextNode.
Gravar o documento e o índice
Duas maneiras
- Gravar no disco local
- Base de dados Storage to Vector
*** Gravar no disco local ***
import os.path
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
import sys
# check if storage already exists
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):
# 保存数据: Load the documents and create the index
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# store it for later
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
# 从磁盘加载回数据: load the existing index
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
Construir um índiceName
Criar uma incorporação para cada Nó
Criar um índice no VectorStroreIndex
1 . > 1 . Para VectorStoreIndex, o texto incorporado no nó é armazenado no índice Faiss, e a busca de similaridade pode ser feita rapidamente no nó. 2 . > 2 . O índice também armazena metadados em cada nó, como ID do documento, localização, etc. 3 . > 3 . Um nó pode obter o conteúdo de um documento ou de um documento específico.
Índice de pesquisa
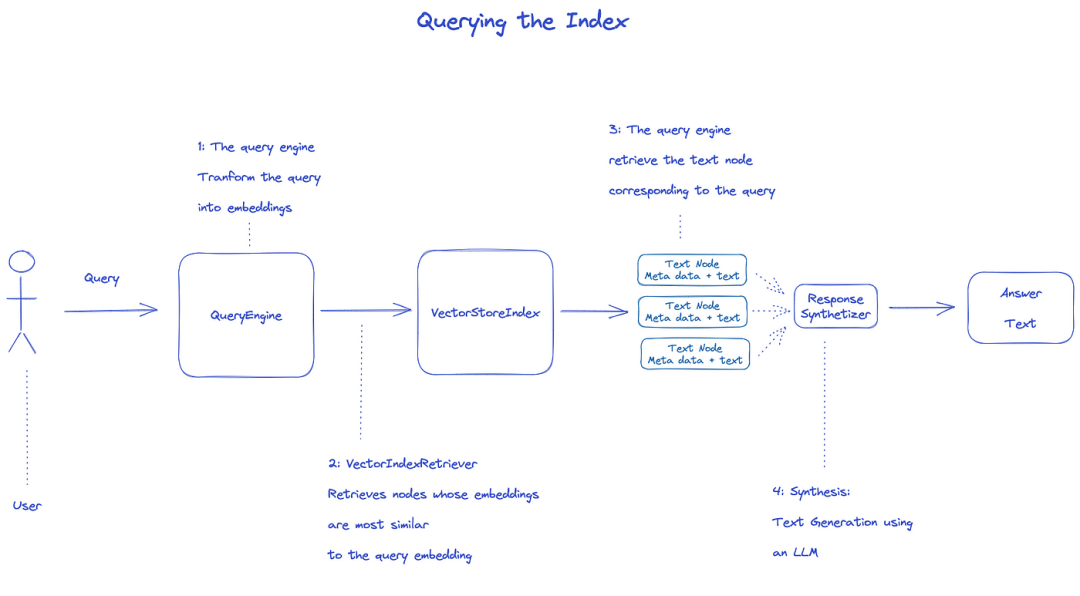
Para consultar o índice, será utilizado o QueryEngine.
- A recuperação obtém os nós relevantes do índice da pesquisa. Por exemplo, VectorIndexRetriever recupera o nó cuja incorporação é mais semelhante à incorporação da pesquisa 2 . > 2 . A lista de nós recuperados é passada para ResponseSynthesizer para gerar a saída final 3 . > 3 . Por padrão, ResponseSynthesizer processa cada nó sequencialmente, e cada nó chama LLM API uma vez.
- Consulta de entrada LLM e texto do nó para obter a saída final 5 . > 5 . As respostas de cada um destes nós são agregadas na cadeia de saída final.
from llama_index import (
VectorStoreIndex,
get_response_synthesizer,
)
from llama_index.retrievers import VectorIndexRetriever
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.postprocessor import SimilarityPostprocessor
from llama_index import StorageContext, load_index_from_storage
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir="storage")
# load index
index = load_index_from_storage(storage_context)
# configure retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=10,
)
# configure response synthesizer
response_synthesizer = get_response_synthesizer()
# assemble query engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
node_postprocessors=[SimilarityPostprocessor(similarity_cutoff=0.7)],
)
# query
response = query_engine.query("What did the author do growing up?")
print(response)
Documento oficial: memorando de entendimento
** Três processos de tratamento de dados **
Limpeza de dados/pipelines de engenharia de recursos no mundo ML, ou gasodutos de ETL no contexto tradicional de dados.
Este gasoduto de ingestão consiste normalmente em três fases principais:
- Carregar os dadosName
- Transformar os dados
- Índice e armazenamento dos dados
Carregar os dados (ingestão)
** Objetivo:** Formatar vários tipos de dados em objetos 'documento'.
** Entrada: ** Vários tipos de dados
** Resultado: *** Objecto «documento»
*** Três maneiras ***
- Utilizar a classe «SimpleDirectoryReader»: a mais conveniente
- «Reader» em «LlamaHubb»: várias ferramentas que foram escritas
- criar «documento» directamente.
*** Classe «SimpleDirectoryReader» **
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
Apoiar Markdown, PDFs, Documentos Word (.docx), baralhos PowerPoint, imagens (.jpg, .png), áudio e vídeo
*** Llamahub ***
- Notion (
NotionPageReader) - Google Docs (
GoogleDocsReader) - Slack (
SlackReader) - Discord (
DiscordReader) - Apify Actors (
ApifyActor). Can crawl the web, scrape webpages, extract text content, download files including.pdf,.jpg,.png,.docx, etc.这个可以爬虫
*** Criar o documento *** directamente
from llama_index.schema import Document
doc = Document(text="text")
Transformar os dados (transformações)
** Razão: ** Recuperação conveniente e utilização eficiente da LLM
*** Operações específicas: ***
- Fragmento 'documento' (chunking)
- Extrair metadados (extracção de metadados)
- Com a incorporação
** Entrada: ** 'Node'
** Saída: *** 'Node'
API encapsulada em encapsulado
Utilizar o método «VectorStoreIndex» «From_documents» ( )
from llama_index import VectorStoreIndex
vector_index = VectorStoreIndex.from_documents(documents)
vector_index.as_query_engine()
*** Como personalizar os parâmetros ***
Ideia: usar o 'ServiceContexto' para personalizar
text_splitter = SentenceSplitter(chunk_size=512, chunk_overlap=10)
service_context = ServiceContext.from_defaults(text_splitter=text_splitter)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
API atómica API
Modo de utilização normal
from llama_index import Document
from llama_index.embeddings import OpenAIEmbedding
from llama_index.text_splitter import SentenceSplitter
from llama_index.extractors import TitleExtractor
from llama_index.ingestion import IngestionPipeline, IngestionCache
# 加载数据源
documents = SimpleDirectoryReader("./data").load_data()
# 创建转换数据的工作流
# create the pipeline with transformations
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=25, chunk_overlap=0), # 分片
TitleExtractor(), # 提取Meta信息
OpenAIEmbedding(), # Embedding
]
)
# 执行流程,生成节点
# run the pipeline
nodes = pipeline.run(documents=documents)
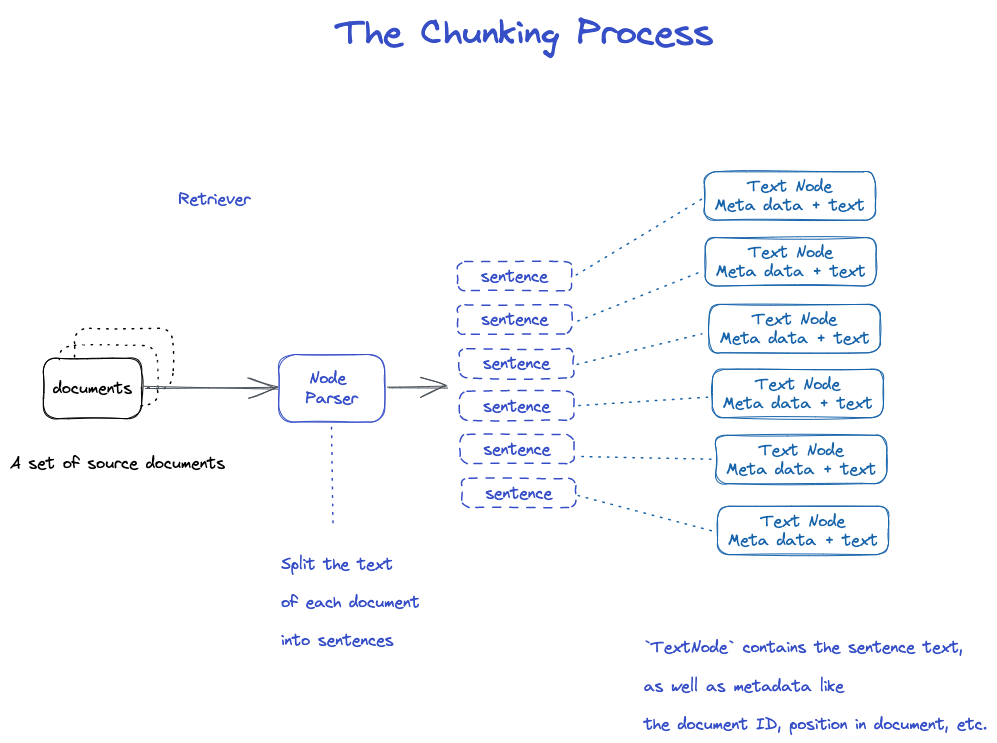
Uma fatia de fatia
Existem muitas estratégias, como especificado no módulo Node Parser.
Adicionar os Metadados
Poderá personalizar o documento e o Nó para adicionar meta- dados.
Criar um objecto de Nó directamente
from llama_index.schema import TextNode
node1 = TextNode(text="<text_chunk>", id_="<node_id>")
node2 = TextNode(text="<text_chunk>", id_="<node_id>")
index = VectorStoreIndex([node1, node2])
Índice
** Classificação dos índices **
- Vector Stores
- Document Stores
- Index Stores
- Key-Value Stores
- Using Graph Stores
- [ chat Stores ] [ Chat Stores ]
** índices comuns **
- Índice de síntese (antigo índice da lista)
- Vector Store Index (mais comum)
- Índice das árvores
- Índice da Tabela de Palavras-chave
** Índice de síntese (anteriormente Índice de Listas)**

** Vector Store Index **

*** Índice de árvores ***

** Índice da Tabela de Palavras-chave **

-
https: //docs.llamaindex.ai/ en/ stable/ module_guias/armazen/chat_stores.html)
meta
Adicionar meta do meta
document.metadata['lang'] = lang
Filtro
from llama_index.core.vector_stores import (
ExactMatchFilter,
MetadataFilters,
MetadataFilter,
)
filters = MetadataFilters(
filters=[
MetadataFilter(key="post_year", value="2017"),
],
)
# You pass filter as an argument. You can have any type of filter
# we saw above and then pass it to query engine.
query_engine = index.as_query_engine(service_context=service_context,
similarity_top_k=5,
filters = filters,
response_mode='tree_summarize')
response = query_engine.query("Marathon Running")
print(response)
Modos de resposta
- refinar: Gerar respostas uma a uma com o contexto; usar o modelo text_Qa_template primeiro, e depois usar o modelo refine_template.
- Compact: por padrão. Semelhante ao refinar, no entanto, o contexto está abarrotado com um pedido.
- TREE_ RESUMOZ
- Simple_ SUMÁRIO
Código fonte de dados
Documento de trabalho da Comissão
um «Documento» é uma subclasse de um «Node»)
Contém: @ info/ plain
-
Texto de texto
-
"Metadata" - "Metadata"
-
«roomships », relação com outros documentos/nós
*** Processo de utilização atómica ***
from llama_index import Document, VectorStoreIndex
# 数据源
text_list = [text1, text2, ...]
# 手动创建documents
documents = [Document(text=t) for t in text_list]
# 建立索引: 传入document,在VectorStoreIndex再转换:分片转成Node,Embedding等
index = VectorStoreIndex.from_documents(documents)
Vários métodos de criação do documento
*** Criar manualmente ***
from llama_index import Document
text_list = [text1, text2, ...]
documents = [Document(text=t) for t in text_list]
** Usar o carregador de dados (conector) **
Todas elas têm um método load_data ()
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
*** Dados gerados automaticamente pela amostra ***
document = Document.example()
Meta por medida
from llama_index import Document
from llama_index.schema import MetadataMode
document = Document(
text="This is a super-customized document",
metadata={
"file_name": "super_secret_document.txt",
"category": "finance",
"author": "LlamaIndex",
},
excluded_llm_metadata_keys=["file_name"],
metadata_seperator="::",
metadata_template="{key}=>{value}",
text_template="Metadata: {metadata_str}\n-----\nContent: {content}",
)
print(
"The LLM sees this: \n",
document.get_content(metadata_mode=MetadataMode.LLM),
)
print()
print(
"The Embedding model sees this: \n",
document.get_content(metadata_mode=MetadataMode.EMBED),
)
Saída a partir de
The LLM sees this:
Metadata: category=>finance::author=>LlamaIndex
-----
Content: This is a super-customized document
The Embedding model sees this:
Metadata: file_name=>super_secret_document.txt::category=>finance::author=>LlamaIndex
-----
Content: This is a super-customized document
Padrão de utilização de extracção de meta- dados (não compreendo)
Nó
Essencial: fragmentação do documento
Como é que se consegue:
- Usar a classe de NodeParser para converter o documento para Nó
- Criar manualmente. -
Tal como o documento, há:
-
Texto de texto
-
"Metadata" - "Metadata"
-
«roomships », relação com outros documentos/nós
Ao converter de documento para Nó, informações como meta- dados são herdadas.
Nó é um cidadão de primeira classe no LlamaIndex.
*** Processo de utilização atómica ***
from llama_index.node_parser import SentenceSplitter
# load documents
...
# 手动转换:切片,转成Node
# parse nodes
parser = SentenceSplitter()
nodes = parser.get_nodes_from_documents(documents)
# build index
index = VectorStoreIndex(nodes)
*** Relação definida ***
from llama_index.schema import TextNode, NodeRelationship, RelatedNodeInfo
node1 = TextNode(text="text_chunk1", id_="node_id1")
node2 = TextNode(text="text_chunk2", id_="node_id2")
node3 = TextNode(text="text_chunk3", id_="node_id3")
# set relationships
node1.relationships[NodeRelationship.NEXT] = RelatedNodeInfo(
node_id=node2.node_id
)
node2.relationships[NodeRelationship.PREVIOUS] = RelatedNodeInfo(
node_id=node1.node_id
)
node2.relationships[NodeRelationship.PARENT] = RelatedNodeInfo(
node_id=node3.node_id, metadata={"key": "val"}
)
print(node2)
NodeParser do NodeReser
Objectivo: Converter as fontes de dados em Nó
Específico: Fragmentar um grupo de objectos do documento em múltiplos objectos de Nó
Execução comum e concreta
NodeParser é uma classe abstrata, que é implementada da seguinte forma:
*** Por tipo de ficheiro ***
- SimpleFileNodeParser - SimpleFileNodeParser
- HTMLNodeParser (HTMLNodeParser)
- JSONNodeParser. - JSONNodeParser.
- Marcar o NodeParser
*** Segmentação do texto **
- Separador de códigos
- LangchainNodeParser. - LangchainNodeParser
- SentenceSplitter - SentenceSplitter
- "SentenceWindowNodeParser" (não entendo)
- SemantiSplitterNodeParser (não entendo, parece mais avançado)
- TokenTextSplitter - TokenTextSplitter
*** Pai - Relação de filho ***
- HierarquicalNodeParser: utilizado no AutoMerginRetriever
Utilização típica do produto
*** Uso atómico ***
from llama_index import Document
from llama_index.node_parser import SentenceSplitter
# 创建NodeParser
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
# 调用 get_nodes_from_documents() 方法
# show_progress 可以显示进度
nodes = node_parser.get_nodes_from_documents(
[Document.example(), Document.example()], show_progress=True
)
print(len(nodes))
print()
print(nodes[0])
Saída a partir de
2
Node ID: eaeb6e44-6828-4e36-b7a3-69342de4dc7c
Text: Context LLMs are a phenomenal piece of technology for knowledge
generation and reasoning. They are pre-trained on large amounts of
publicly available data. How do we best augment LLMs with our own
private data? We need a comprehensive toolkit to help perform this
data augmentation for LLMs. Proposed Solution That's where LlamaIndex
comes in. Ll...
*** Transformações *** em piplina
from llama_index import Document
from llama_index.node_parser import SentenceSplitter
from llama_index.ingestion import IngestionPipeline
from llama_index.node_parser import TokenTextSplitter
documents = [Document.example(), Document.example()]
# 创建NodeParser
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
# 将NodeParser放到Pipeline中的transformations列表
pipeline = IngestionPipeline(transformations=[node_parser])
nodes = pipeline.run(documents=documents)
print(len(nodes))
print()
print(nodes[0])
** Usar ServiceContext **
from llama_index import Document, ServiceContext, VectorStoreIndex
from llama_index.node_parser import SentenceSplitter
from llama_index.ingestion import IngestionPipeline
from llama_index.node_parser import TokenTextSplitter
documents = [Document.example(), Document.example()]
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
service_context = ServiceContext.from_defaults(text_splitter=node_parser)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context, show_progress=True
)
As transformações em curso
Entrada: um conjunto de Nó
Resultado: um conjunto de Nó
Há duas maneiras comuns:
- `___ call_()»: sincronizar
- «Asynchronous ()»: acall
NodeParser e «MetadataExtractor» pertencem a transformações
*** Modo de utilização **
from llama_index.text_splitter import SentenceSplitter
from llama_index.extractors import TitleExtractor
node_parser = SentenceSplitter(chunk_size=512)
extractor = TitleExtractor()
# use transforms directly
nodes = node_parser(documents)
# or use a transformation in async
nodes = await extractor.acall(nodes)
*** Combinado com ServiceContext ***
from llama_index import ServiceContext, VectorStoreIndex
from llama_index.extractors import (
TitleExtractor,
QuestionsAnsweredExtractor,
)
from llama_index.ingestion import IngestionPipeline
from llama_index.text_splitter import TokenTextSplitter
transformations = [
TokenTextSplitter(chunk_size=512, chunk_overlap=128),
TitleExtractor(nodes=5),
QuestionsAnsweredExtractor(questions=3),
]
# 创建ServiceContext,传入Transfrmation
service_context = ServiceContext.from_defaults(
transformations=[text_splitter, title_extractor, qa_extractor]
)
# 传入VectorStoreIndex的from_documents()或insert()方法
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
ServiçoContexto de texto
Um pacote de serviços e configurações utilizados através de um gasoduto LlamaIndex.
*** Pode ser configurado **
from llama_index import (
ServiceContext,
OpenAIEmbedding,
PromptHelper,
)
from llama_index.llms import OpenAI
from llama_index.text_splitter import SentenceSplitter
# 设置LLM
llm = OpenAI(model="text-davinci-003", temperature=0, max_tokens=256)
# 设置Embedding模型
embed_model = OpenAIEmbedding()
# 设置Chunk的大小
text_splitter = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
prompt_helper = PromptHelper(
context_window=4096,
num_output=256,
chunk_overlap_ratio=0.1,
chunk_size_limit=None,
)
service_context = ServiceContext.from_defaults(
llm=llm, # 设置LLM
embed_model=embed_model, # 设置Embedding模型
text_splitter=text_splitter, # 设置Chunk的大小
prompt_helper=prompt_helper,
)
*** Parâmetros do construtor ** (mais conveniente)
** Kwargs para analisador de nó ***:
- 'Chunk_ dime'
- `chunk_ sobreposição
*** Kwargs para auxiliar de linha ***:
- 'Window': 'Window': 'Window':
- "num_output" - "num_output"
Por exemplo, por exemplo
service_context = ServiceContext.from_defaults(chunk_size=1000)
*** Configuração global **
from llama_index import set_global_service_context
set_global_service_context(service_context)
*** Configuração local **
query_engine = index.as_query_engine(service_context=service_context)
Texto do StorageContext
Define a infra- estrutura de armazenamento para onde os documentos, os pacotes e os índices são guardados.
[Referência da API] (htts: // docs.llamaindex.ai/ en/ stable/ API_reference /)
store = PGVectorStore(
connection_string=conn_string,
async_connection_string=async_conn_string,
schema_name=PGVECTOR_SCHEMA,
table_name=PGVECTOR_TABLE,
)
index = VectorStoreIndex.from_vector_store(store)
VectorStoreIndex Índice
Função do construtor
index = VectorStoreIndex.from_vector_store(store)
Existem dois tipos de motores:
- Query Engine: BaseQueryEngine
- Chat Engines: BaseChatEngine
Criar um motorName
index.as_query_engine()# BaseQueryEngine
index.as_query_engine(streaming=True)# 流式 BaseQueryEngine
index.as_chat_engine() # BaseChatEngine; 流式不是在这里控制
Uma consulta de opinião
# Query
response = await query_engine.aquery(query) # 流式
response = await query_engine.aquery(query)
# Chat
response = await chat_engine.astream_chat(last_message_content, messages) # 流式在这里控制
response = await chat_engine.achat(last_message_content, messages)
BaseQueryEngine >
Questão de consulta
Aquícolas
BaseChatEngine >
- Conversar >
- 'stream_ chat'
- cada uma
- astream_ chat
suporta a transmissão: fluxo
O asíncrono é suportado: a começar por um
Tipo de resposta
# Query
RESPONSE_TYPE = Union[
Response,
StreamingResponse, AsyncStreamingResponse, #流式
PydanticResponse
]
# Chat
StreamingAgentChatResponse #流式
AGENT_CHAT_RESPONSE_TYPE = Union[AgentChatResponse, StreamingAgentChatResponse] #非流式
Como lidar com a resposta em streaming
Utilizar as APIs-padrão de Python:
- StreamingResponse ()
- AsyncStreamingResponse
- StreamingResponse
- Questão de consulta
@r.post("")
async def chat(
request: Request,
queryData: _QueryData,
query_engine: BaseQueryEngine = Depends(get_query_engine_stream),
):
query = queryData.query
streaming_response = await query_engine.aquery(query)
async def event_generator():
async for token in streaming_response.async_response_gen:
if await request.is_disconnected():
break
yield f"data: {token}\n\n"
return StreamingResponse(event_generator(), media_type="text/event-stream")
- Conversar? - Sim.
@r.post("")
async def chat(
request: Request,
data: _ChatData,
chat_engine: BaseChatEngine = Depends(get_chat_engine),
):
last_message_content, messages = await parse_chat_data(data)
response = await chat_engine.astream_chat(last_message_content, messages)
async def event_generator():
async for token in response.async_response_gen():
if await request.is_disconnected():
break
yield token
return StreamingResponse(event_generator(), media_type="text/plain")
"StreamingResponse"
class AsyncStreamingResponse:
async_response_gen: TokenAsyncGen
class StreamingResponse:
response_gen: TokenGen
Modos de resposta
Monitor e controlo
Tutoriais do ensino superior
Tutorial deeplearn Deeplearn
Building and Evaluating Advanced RAG Applications:链接 Bilibili
*** Texto conjunto para SQL e pesquisa semântica ***
Este vídeo cobre as ferramentas construídas no LlamaIndex para combinar SQL e pesquisa semântica em uma única interface de consulta unificada.