Base de datos vectorial å
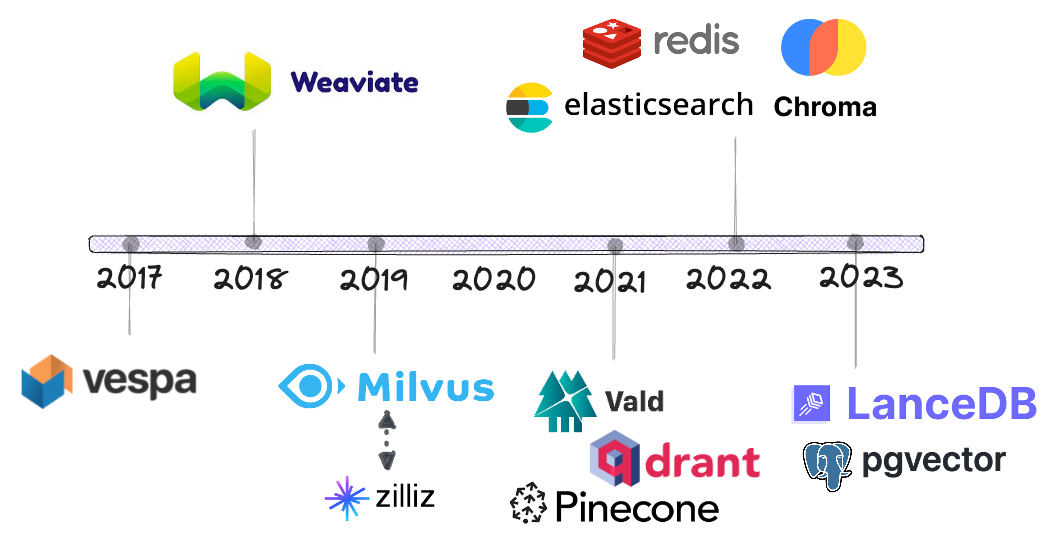
Cronología
Vespa es uno de los primeros vendedores en añadir búsqueda de similitud vectorial junto al algoritmo de búsqueda de palabras clave basado en BM25.
Weaviate lanzó a finales de 2018 una base de datos dedicada a la búsqueda de vectores de código abierto.
Para 2019, empezaremos a ver más competencia en esta área, incluyendo Milvus (también de código abierto). Zilliz es la empresa matriz de Milvus.
En 2021, tres nuevos proveedores se unieron a la competencia: Vald, Qdrant y Pinecone.
Fue sólo entonces que proveedores establecidos como Elasticsearch, Redis y PostgreSQL comenzaron a ofrecer búsqueda vectorial, mucho más tarde de lo que la gente pensaba, sólo en 2022 y después.
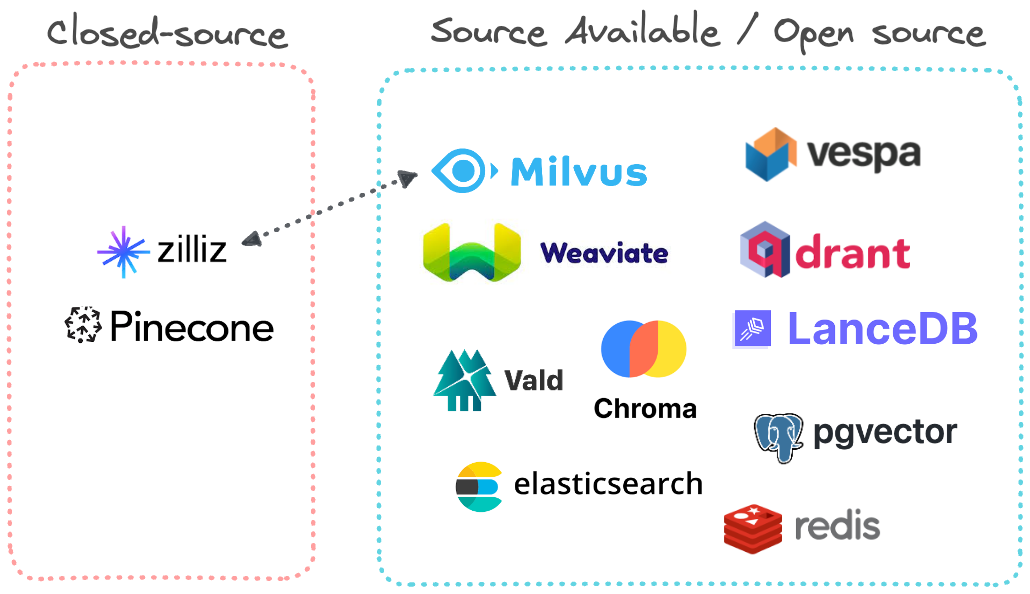
Código abierto y comercio
Negocios: Pinecona y Zilliz
Enchufe - en forma
- pgvector
- Redis Stack
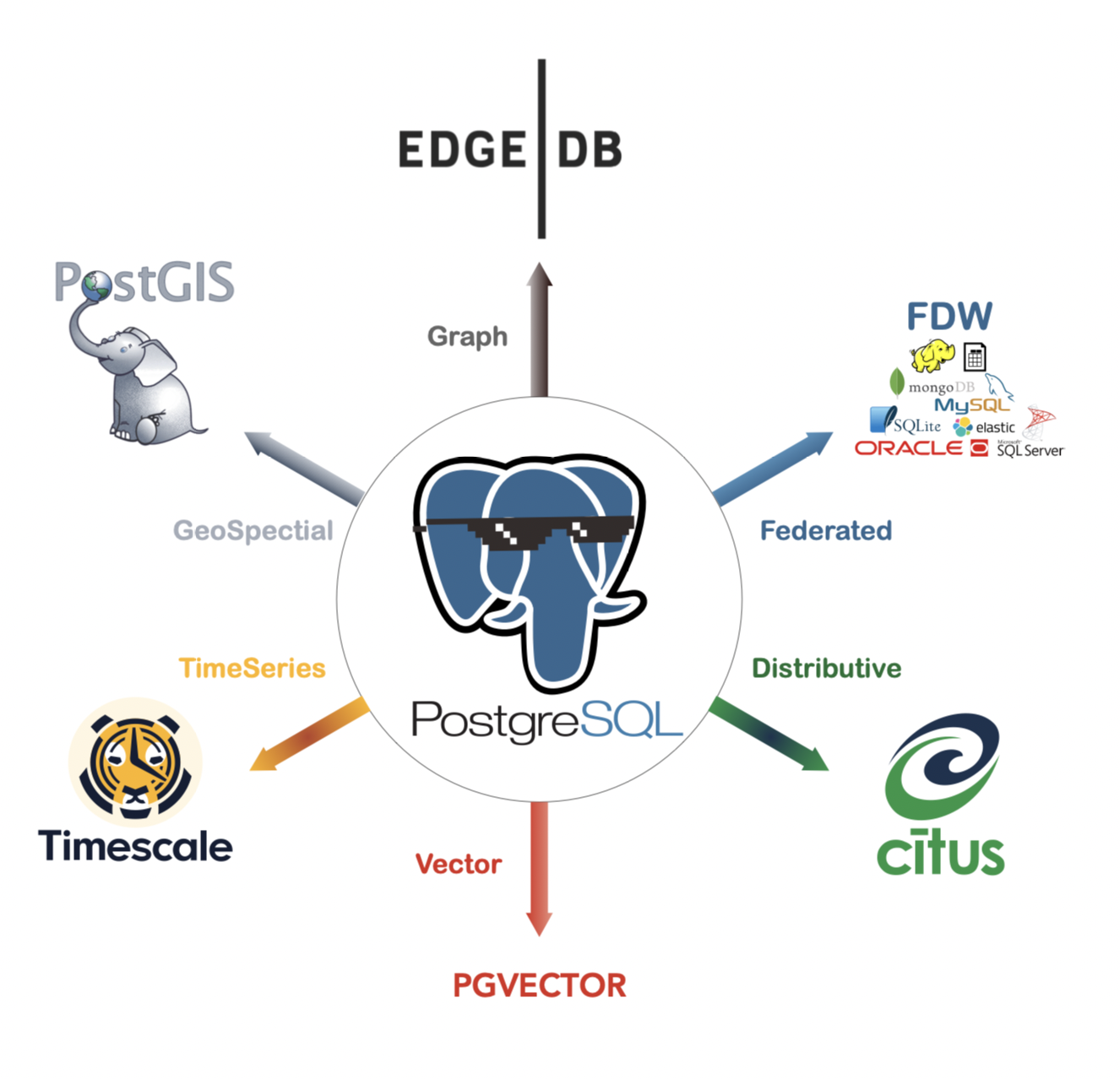
Postgres@info: whatsthis
Una base de datos también admite:
- Base de datos relacional: RDS
- Base de datos Vector: pgvector
- Base de datos de series temporales: la base de datos de series temporales juega un papel importante en el filtrado de metadatos. Es una base de datos que registra eventos y tiempo de ocurrencia, y la velocidad de búsqueda de series temporales es muy rápida. En aplicaciones RAG, si se eliminan decenas de miles de archivos de conocimiento de la industria, será muy importante utilizar el filtrado del tiempo. Por ejemplo, si sólo necesitamos recuperar los archivos del contrato en marzo de 2023, entonces podemos utilizar datos de series temporales para seleccionar el trozo de destino de decenas de miles, y luego calcular el vector.
Enchufe del Vector de escala de tiempo - In@info: whatsthis
Búsqueda de similitudes más rápidas para millones de vectores: soporte** Algoritmo DiskAN**,** Algoritmo HNSW**
- Timescale Vector optimiza las consultas de búsqueda de vectores basadas en el tiempo: Utilice el tiempo automático - particionamiento basado en la partición y indexación de la súper tabla de Timescale para encontrar efectivamente las incrustaciones más cercanas, búsqueda por rango de tiempo o vector de restricción de la existencia de documentos, y almacenar y recuperar fácilmente respuestas de modelo de lenguaje grande (LLM) y historia de chat. Tiempo - búsqueda semántica basada también le permite utilizar la generación mejorada de búsqueda** (Generación aumentada Retrieval,rag) y la recuperación de contexto basado en tiempo - para proporcionar a los usuarios respuestas LLM más útiles. -** Stack de infraestructuras de IA simplificadas:** combinandoincorporaciones vectoriales,** datos relacionales** ydatos de series cronológicas en una base de datos PostgreSQL, Timescale Vector elimina la complejidad operativa de la gestión de múltiples sistemas de bases de datos a gran escala. -** Simplificar el procesamiento de metadatos y el filtrado de atributos múltiples:** Los desarrolladores pueden utilizar todos los tipos de datos PostgreSQL para almacenar y filtrar metadatos y conectar los resultados de búsqueda vectorial con datos relacionales para obtener más contexto - respuestas sensibles. En futuras versiones, Timescale Veltor optimizará aún más el filtrado multi-atributo rico para permitir una búsqueda más rápida de similitudes al filtrar metadatos.
Base de datos de vectores recopilada por LlamaIndex
** Opciones Vector Store & soporte de características**
| Vector Store | Type | Metadata Filtering | Hybrid Search | Delete | Store Documents | Async |
|---|---|---|---|---|---|---|
| Apache Cassandra® | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Astra DB | cloud | ✓ | ✓ | ✓ | ||
| Azure Cognitive Search | cloud | ✓ | ✓ | ✓ | ||
| Azure CosmosDB MongoDB | cloud | ✓ | ✓ | |||
| ChatGPT Retrieval Plugin | aggregator | ✓ | ✓ | |||
| Chroma | self-hosted | ✓ | ✓ | ✓ | ||
| DashVector | cloud | ✓ | ✓ | ✓ | ✓ | |
| Deeplake | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| DocArray | aggregator | ✓ | ✓ | ✓ | ||
| DynamoDB | cloud | ✓ | ||||
| Elasticsearch | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ |
| FAISS | in-memory | |||||
| txtai | in-memory | |||||
| Jaguar | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | |
| LanceDB | cloud | ✓ | ✓ | ✓ | ||
| Lantern | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ |
| Metal | cloud | ✓ | ✓ | ✓ | ||
| MongoDB Atlas | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| MyScale | cloud | ✓ | ✓ | ✓ | ✓ | |
| Milvus / Zilliz | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Neo4jVector | self-hosted / cloud | ✓ | ✓ | |||
| OpenSearch | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Pinecone | cloud | ✓ | ✓ | ✓ | ✓ | |
| Postgres | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ |
| pgvecto.rs | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | |
| Qdrant | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ |
| Redis | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Simple | in-memory | ✓ | ✓ | |||
| SingleStore | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Supabase | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Tair | cloud | ✓ | ✓ | ✓ | ||
| TencentVectorDB | cloud | ✓ | ✓ | ✓ | ✓ | |
| Timescale | ✓ | ✓ | ✓ | ✓ | ||
| Typesense | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Weaviate | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ |
Bases de datos más apoyadas
| ector Store | Type | Metadata Filtering | Hybrid Search | Delete | Store Documents | Async | |
|---|---|---|---|---|---|---|---|
| DashVector | cloud | ✓ | ✓ | ✓ | ✓ | ||
| Elasticsearch | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ | 总觉得比较重 |
| Jaguar | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ||
| Lantern | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ | |
| MyScale | cloud | ✓ | ✓ | ✓ | ✓ | ||
| Pinecone | cloud | ✓ | ✓ | ✓ | ✓ | ||
| Postgres | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ | |
| pgvecto.rs | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ||
| Qdrant | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ | 创始人好像出走了 |
| TencentVectorDB | cloud | ✓ | ✓ | ✓ | ✓ | ||
| Weaviate | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ |
Elasticsearch:总觉得比较重
Postgress:先从最简单的开始吧。
Qdrant:创始人好像出走了。
Comparación de bases de datos por LangChain
| 数据库名称 | 应用场景 |
|---|---|
| HNSWLib, Faiss, LanceDB, CloseVector | 如果你需要一个可以在你的Node.js应用程序中运行的内存数据库,无需其他服务器 |
| MemoryVectorStore, CloseVector | 如果你在寻找一个可以在类似浏览器的环境中内存中运行的东西 |
| HNSWLib, Faiss | 如果你来自Python,并且你在寻找类似于FAISS的东西 |
| Chroma | 如果你在寻找一个开源的、功能全面的向量数据库,可以在docker容器中本地运行 |
| Zep | 如果你在寻找一个开源的向量数据库,提供低延迟、本地嵌入文档支持,并且支持边缘上的应用 |
| Weaviate | 如果你在寻找一个开源的、生产就绪的向量数据库,可以在docker容器中本地运行或在云中托管 |
| Supabase vector store | 如果你已经在使用Supabase,看看Supabase向量存储,使用同一个Postgres数据库来存储你的嵌入 |
| Pinecone | 如果你在寻找一个生产就绪的向量存储,你不必担心自己托管 |
| SingleStore vector store | 如果你已经在使用SingleStore,或者你需要一个分布式、高性能的数据库,你可能会考虑SingleStore向量存储 |
| AnalyticDB vector store | 如果你在寻找一个在线MPP(大规模并行处理)数据仓库服务,你可能会考虑AnalyticDB向量存储 |
| MyScale | 如果你在寻找一个性价比高的向量数据库,允许使用SQL进行向量搜索 |
| CloseVector | 如果你在寻找一个可以从浏览器和服务器端加载的向量数据库,看看CloseVector。它是一个旨在跨平台的向量数据库 |
| ClickHouse | 如果你在寻找一个可扩展的、开源的列式数据库,对于分析查询有着出色的性能 |