Base de données vectorielles å
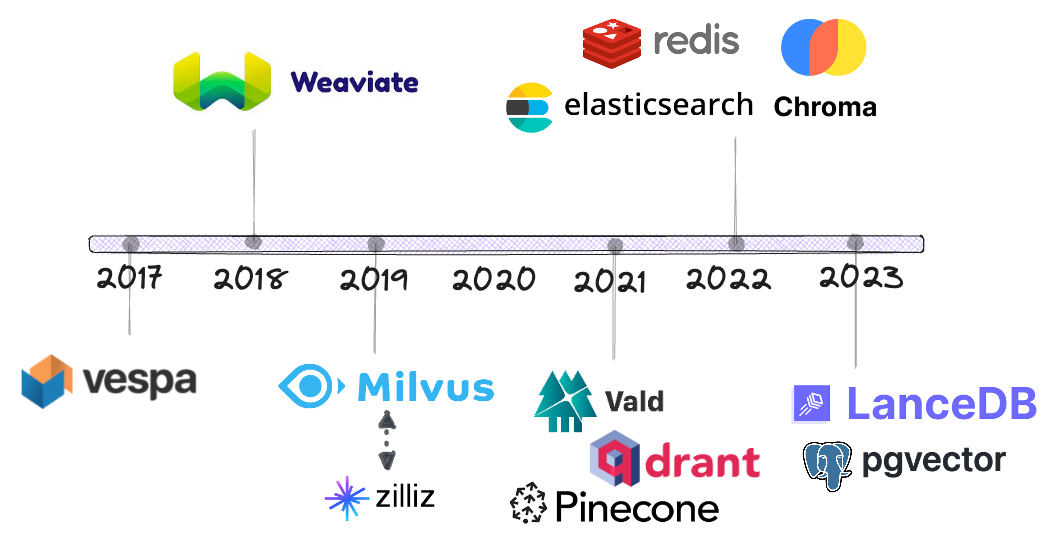
Calendrier
Vespa est l'un des premiers fournisseurs à ajouter la recherche de similarité vectorielle à côté de l'algorithme de recherche par mot-clé principal basé sur BM25.
Weaviate a ensuite lancé un produit de base de données de recherche vectorielle open source dédié à la fin de 2018.
D'ici 2019, nous commencerons à voir plus de concurrence dans ce domaine, y compris Milvus (également open source). Zilliz est la société mère de Milvus.
En 2021, trois nouveaux fournisseurs ont rejoint la compétition: Vald, Qdrant et Pinecone.
Ce n'est qu'à ce moment-là que des fournisseurs établis tels qu'Elasticsearch, redis et PostgreSQL ont commencé à offrir la recherche vectorielle, beaucoup plus tard que les gens ne le pensaient, qu'en 2022 et après.
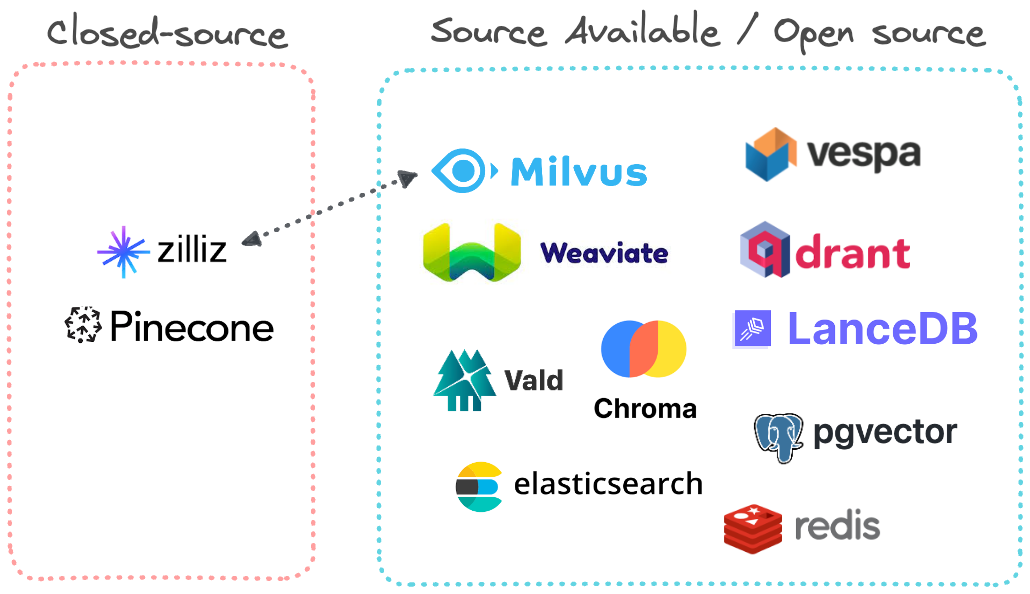
Open source et commerce
Activité: Pinecone et Zilliz
Formulaire plug-in
-pgvector -pile de redis
Postgres
Une base de données prend également en charge:
Base de données relationnelle: RDS -base de données Vector: pgvector -base de données de séries temporelles: la base de données de séries chronologiques joue un rôle important dans le filtrage des métadonnées. Il s'agit d'une base de données qui enregistre les événements et l'heure d'occurrence, et la vitesse de recherche des séries chronologiques est très rapide. Dans les applications RAG, si des dizaines de milliers de fichiers de connaissance de l'industrie sont découpés, il sera très important d'utiliser le filtrage temporel. Par exemple, si nous avons seulement besoin de récupérer les fichiers contractuels en mars 2023, alors nous pouvons utiliser des données de séries chronologiques pour choisir le morceau cible de dizaines de milliers, puis calculer le vecteur.
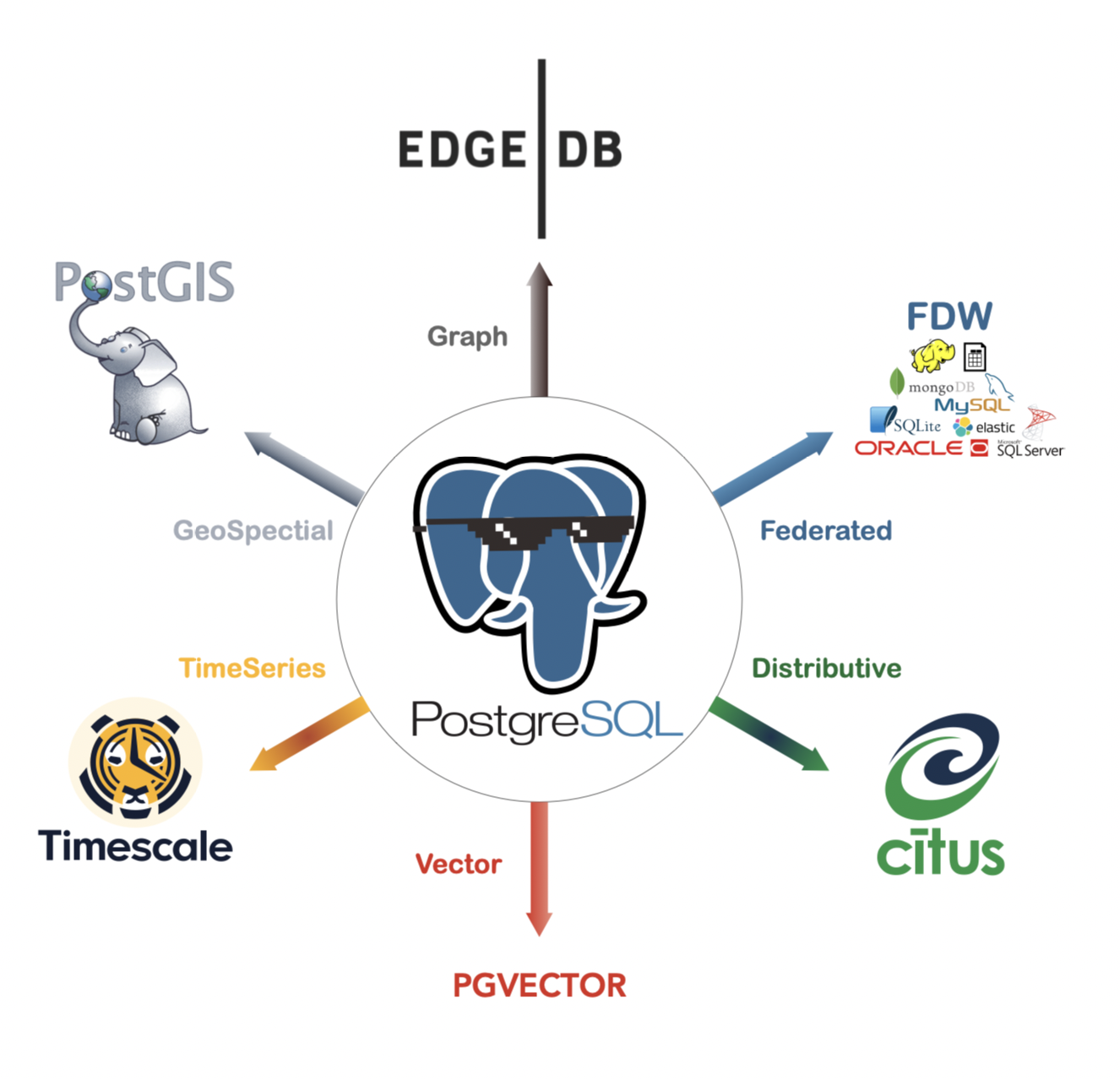
Module vectoriel temporel
Recherche plus rapide de similarité pour des millions de vecteurs: support * * DiskANN * * algorithme, * * HNSW * * algorithme
-* * Time Scale Vector optimise les requêtes de recherche vectorielle basées sur le temps: * * utilisez le partitionnement automatique basé sur le temps et l'indexation de la super table de l'échelle de temps pour trouver efficacement les Embeddings les plus proches, rechercher par intervalle de temps ou par vecteur de contrainte de l'année d'existence du document, et stocker et récupérer facilement les réponses au modèle de langue (LLM) et l'historique du chat. La recherche sémantique basée sur le temps vous permet également d'utiliser * * Search Enhanced Generation (REtrieval Augmented Generation, * * RAG * ) et la récupération contextuelle basée sur le temps pour fournir aux utilisateurs des réponses LLM plus utiles. - * pile d'infrastructure d'IA simplifiée: * * en combinant * * Embeddings vectoriels * , * * données relationnelles * * et * * données chronologiques * * dans une base de données PostgreSQL SQL, le vecteur temporel élimine la complexité opérationnelle de la gestion de plusieurs systèmes de base de données à grande échelle. - * simplifier le traitement des métadonnées et le filtrage multi-attributs: * * les développeurs peuvent utiliser tous les types de données PostgreSQL pour stocker et filtrer les métadonnées et connecter les résultats de la recherche vectorielle aux données relationnelles pour obtenir des réponses plus sensibles au contexte. Dans les versions futures, le vecteur temporel optimisera davantage le filtrage multiattribut riche pour permettre une recherche de similarité plus rapide lors du filtrage des métadonnées.
Base de données vectorielle collectée par LlamaIndex
-
- Vector Store options & Feature Support * *
| Vector Store | Type | Metadata Filtering | Hybrid Search | Delete | Store Documents | Async |
|---|---|---|---|---|---|---|
| Apache Cassandra® | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Astra DB | cloud | ✓ | ✓ | ✓ | ||
| Azure Cognitive Search | cloud | ✓ | ✓ | ✓ | ||
| Azure CosmosDB MongoDB | cloud | ✓ | ✓ | |||
| ChatGPT Retrieval Plugin | aggregator | ✓ | ✓ | |||
| Chroma | self-hosted | ✓ | ✓ | ✓ | ||
| DashVector | cloud | ✓ | ✓ | ✓ | ✓ | |
| Deeplake | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| DocArray | aggregator | ✓ | ✓ | ✓ | ||
| DynamoDB | cloud | ✓ | ||||
| Elasticsearch | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ |
| FAISS | in-memory | |||||
| txtai | in-memory | |||||
| Jaguar | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | |
| LanceDB | cloud | ✓ | ✓ | ✓ | ||
| Lantern | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ |
| Metal | cloud | ✓ | ✓ | ✓ | ||
| MongoDB Atlas | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| MyScale | cloud | ✓ | ✓ | ✓ | ✓ | |
| Milvus / Zilliz | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Neo4jVector | self-hosted / cloud | ✓ | ✓ | |||
| OpenSearch | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Pinecone | cloud | ✓ | ✓ | ✓ | ✓ | |
| Postgres | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ |
| pgvecto.rs | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | |
| Qdrant | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ |
| Redis | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Simple | in-memory | ✓ | ✓ | |||
| SingleStore | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Supabase | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Tair | cloud | ✓ | ✓ | ✓ | ||
| TencentVectorDB | cloud | ✓ | ✓ | ✓ | ✓ | |
| Timescale | ✓ | ✓ | ✓ | ✓ | ||
| Typesense | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Weaviate | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ |
Bases de données les plus prises en charge
| ector Store | Type | Metadata Filtering | Hybrid Search | Delete | Store Documents | Async | |
|---|---|---|---|---|---|---|---|
| DashVector | cloud | ✓ | ✓ | ✓ | ✓ | ||
| Elasticsearch | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ | 总觉得比较重 |
| Jaguar | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ||
| Lantern | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ | |
| MyScale | cloud | ✓ | ✓ | ✓ | ✓ | ||
| Pinecone | cloud | ✓ | ✓ | ✓ | ✓ | ||
| Postgres | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ | |
| pgvecto.rs | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ||
| Qdrant | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ | 创始人好像出走了 |
| TencentVectorDB | cloud | ✓ | ✓ | ✓ | ✓ | ||
| Weaviate | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ |
Elasticsearch:总觉得比较重
Postgress:先从最简单的开始吧。
Qdrant:创始人好像出走了。
Comparaison des bases de données par LangChain
| 数据库名称 | 应用场景 |
|---|---|
| HNSWLib, Faiss, LanceDB, CloseVector | 如果你需要一个可以在你的Node.js应用程序中运行的内存数据库,无需其他服务器 |
| MemoryVectorStore, CloseVector | 如果你在寻找一个可以在类似浏览器的环境中内存中运行的东西 |
| HNSWLib, Faiss | 如果你来自Python,并且你在寻找类似于FAISS的东西 |
| Chroma | 如果你在寻找一个开源的、功能全面的向量数据库,可以在docker容器中本地运行 |
| Zep | 如果你在寻找一个开源的向量数据库,提供低延迟、本地嵌入文档支持,并且支持边缘上的应用 |
| Weaviate | 如果你在寻找一个开源的、生产就绪的向量数据库,可以在docker容器中本地运行或在云中托管 |
| Supabase vector store | 如果你已经在使用Supabase,看看Supabase向量存储,使用同一个Postgres数据库来存储你的嵌入 |
| Pinecone | 如果你在寻找一个生产就绪的向量存储,你不必担心自己托管 |
| SingleStore vector store | 如果你已经在使用SingleStore,或者你需要一个分布式、高性能的数据库,你可能会考虑SingleStore向量存储 |
| AnalyticDB vector store | 如果你在寻找一个在线MPP(大规模并行处理)数据仓库服务,你可能会考虑AnalyticDB向量存储 |
| MyScale | 如果你在寻找一个性价比高的向量数据库,允许使用SQL进行向量搜索 |
| CloseVector | 如果你在寻找一个可以从浏览器和服务器端加载的向量数据库,看看CloseVector。它是一个旨在跨平台的向量数据库 |
| ClickHouse | 如果你在寻找一个可扩展的、开源的列式数据库,对于分析查询有着出色的性能 |