Cơ sở dữ liệu trước
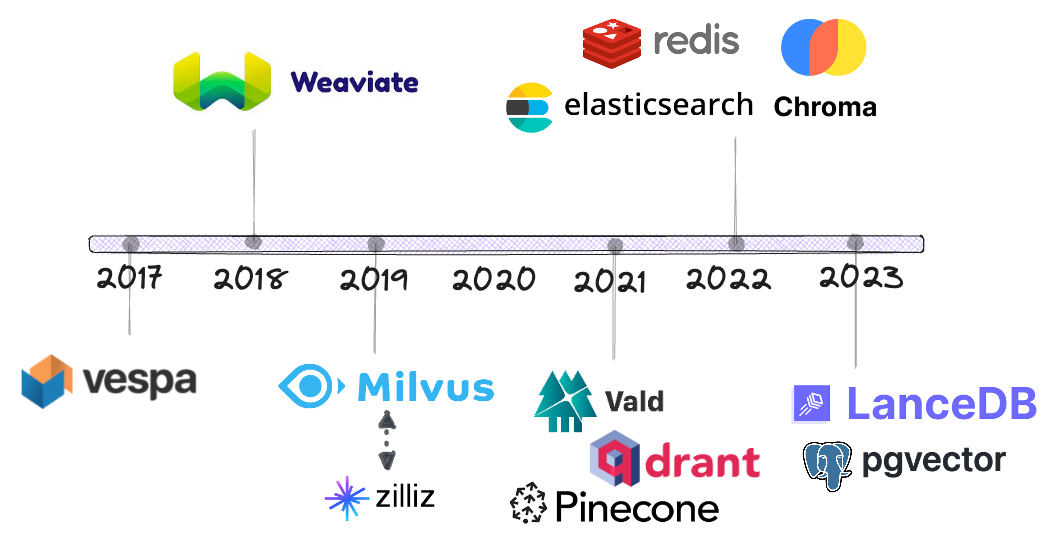
Đường thời gian
Vespa là một trong những nhà sản xuất đầu tiên tham gia tìm kiếm lượt lượng cạnh các thuật toán tìm kiếm từ khóa BM25.
Weaviate sau đó đã cho ra mắt một sản phẩm cơ sở dữ liệu tìm kiếm nguồn mở chuyên biệt vào cuối năm 2018.
Đến năm 2019, chúng ta bắt đầu chứng kiến sự cạnh tranh nhiều hơn trong lĩnh vực này, trong đó có Milius (cũng là nguồn mở). Zilliz là công ty mẹ của Milivus.
Vào năm 2021, có thêm 3 nhà cung cấp mới tham gia cạnh tranh: Vald, Qdrant và Pencone.
Cho đến thời điểm này, các nhà sản xuất bài bản cũ như Elstics, Redis và Postgre QL mới bắt đầu cung cấp tìm kiếm theo lượng phát lượng, muộn hơn nhiều so với những gì người ta tưởng tượng, chỉ sau năm 2022 và sau đó.
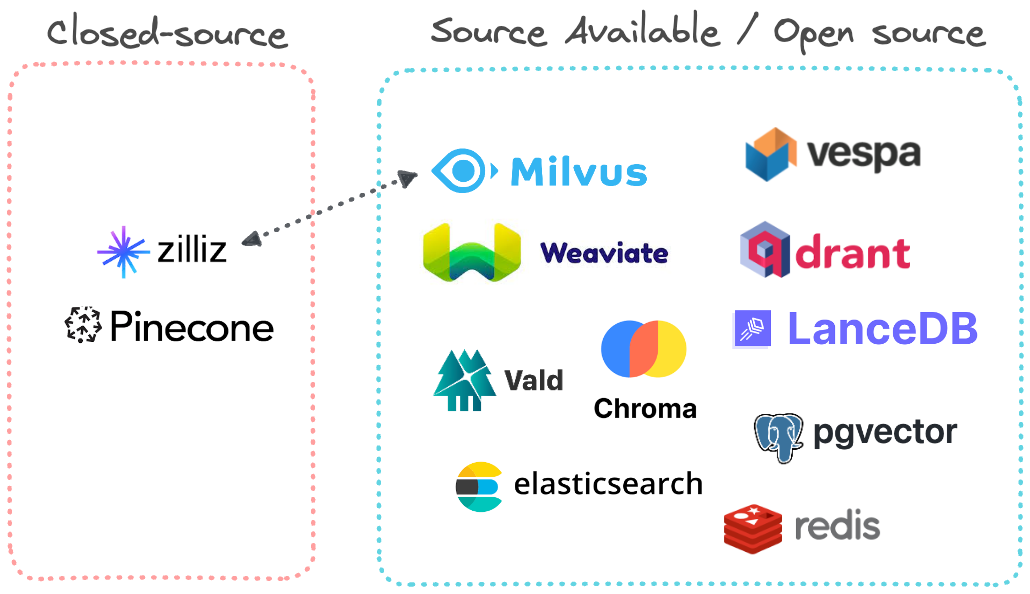
Nguồn mở và thương mại
Thương mại: Pencone và Zilliz
Hình thức bổ sung
- Được rồi.
- Redis Stack.
Xin lỗi.
Một cơ sở dữ liệu hỗ trợ cùng lúc:
- Cơ sở dữ liệu quan hệ: RDS
- Cơ sở dữ liệu cung cấp:pgvector
- Cơ sở dữ liệu trình tự thời gian: Cơ sở dữ liệu thời gian đóng vai trò quan trọng trong việc lọc siêu dữ liệu, nó là một cơ sở dữ liệu ghi lại các sự kiện và diễn biến thời gian, rất nhanh cho việc tìm kiếm các chuỗi thời gian. Trong ứng dụng RAG, nếu hồ sơ kiến thức ngành công nghiệp được cắt ra vài chục nghìn thì việc sử dụng lọc thời gian sẽ rất quan trọng, ví dụ như chúng ta chỉ cần lấy hồ sơ hợp đồng tháng 3 năm 2023, thì có thể dùng dữ liệu theo thời gian để lấy mục tiêu Chink từ vài chục nghìn trở lên, rồi tính toán đo lường.
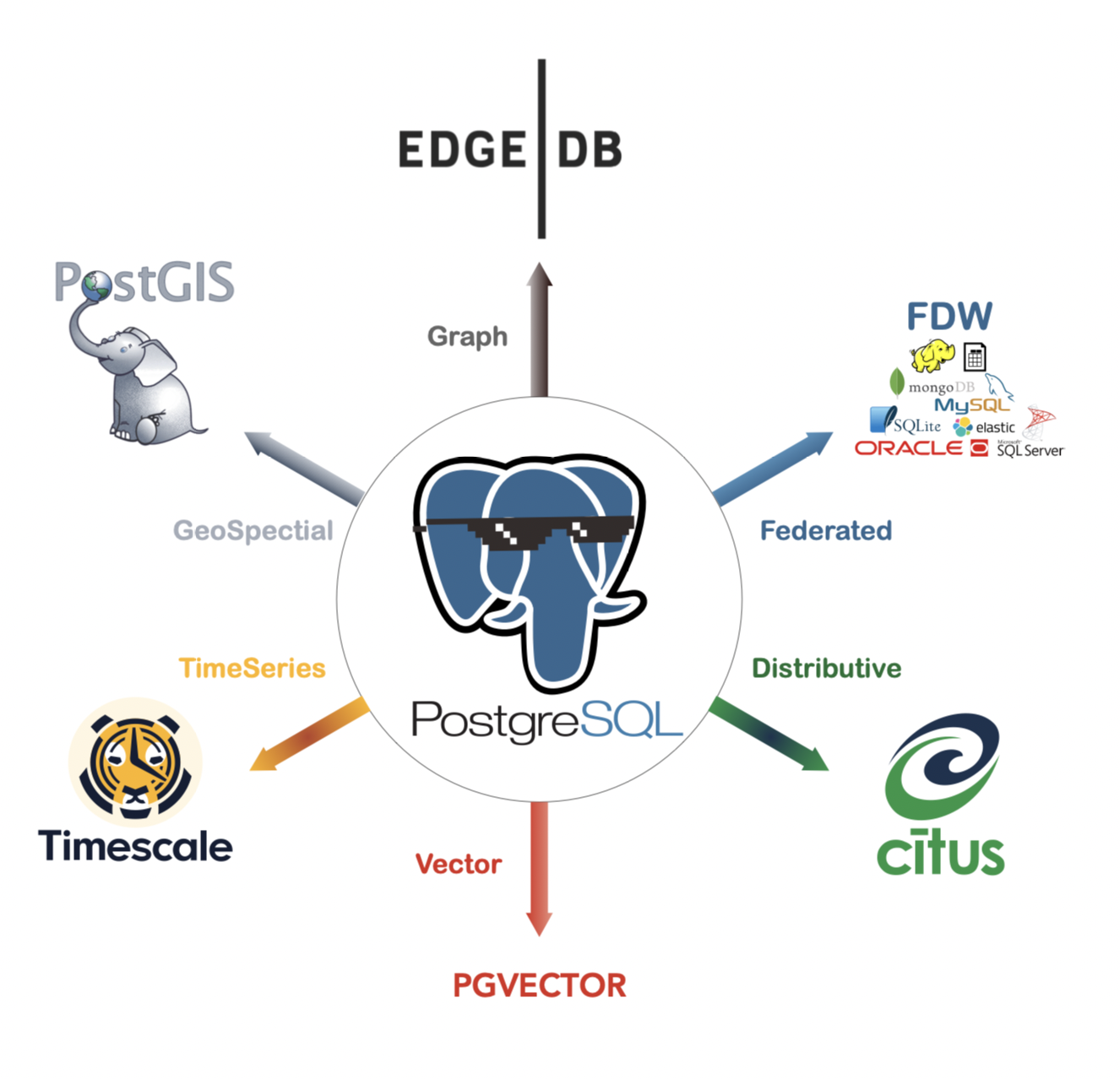
Bổ sung TimeScale Vector
Tìm kiếm sự tương đồng nhanh hơn với hàng triệu lượt xem: Hỗ trợ * DiskAN* * Thuật toán * HNSW* * Thuật toán *
-* TimeScale Vector tối ưu hóa các truy vấn tìm kiếm dựa trên thời gian: * Tự động sử dụng siêu đồng hồ của TimeScale dựa trên các phân vùng và chỉ mục thời gian, tìm ra một cách hiệu quả hơn Embeddings, tìm kiếm thông qua phạm vi thời gian hoặc tài liệu tồn tại theo thời gian và dễ dàng lưu trữ và lấy lại các mô hình ngôn ngữ lớn (LLM) để đáp ứng và tìm kiếm lịch sử cuộc trò chuyện. Tìm kiếm dựa trên nghĩa thời gian cũng cho phép bạn có thể sử dụng * tra cứu sự gia tăng khả năng tìm kiếm * * (Revival Augmented Generation, * RAG*) và tra cứu ngữ cảnh dựa trên thời gian để cung cấp đáp ứng LLM hữu ích hơn cho người dùng. -** Cơ sở hạ tầng AI được đơn giản hóa:** Bằng cách sử dụng * tiên lượng * , * Dữ liệu quan hệ * và * Dữ liệu chuỗi thời gian * trong một cơ sở dữ liệu PostScript SQL, * đã loại bỏ sự phức tạp trong việc quản lý hàng loạt hệ thống cơ sở dữ liệu. - Đơn giản hóa việc xử lý siêu dữ liệu và lọc đa thuộc tính: * Các nhà phát triển có thể sử dụng tất cả các loại dữ liệu Postgre QL để lưu trữ và lọc các siêu dữ liệu và kết nối các kết quả tìm kiếm với dữ liệu quan hệ để có thêm nhiều phản hồi liên quan đến ngữ cảnh. Trong phiên bản sắp tới, TimeScale Vector sẽ được tối ưu thêm lọc đa tính năng phong phú, thực hiện tìm kiếm tương đồng nhanh hơn khi lọc siêu dữ liệu.
Cơ sở dữ liệu đo lường mà Lalama Index đã sắp xếp
-
- Vector Store Option & Feature support* *
| Vector Store | Type | Metadata Filtering | Hybrid Search | Delete | Store Documents | Async |
|---|---|---|---|---|---|---|
| Apache Cassandra® | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Astra DB | cloud | ✓ | ✓ | ✓ | ||
| Azure Cognitive Search | cloud | ✓ | ✓ | ✓ | ||
| Azure CosmosDB MongoDB | cloud | ✓ | ✓ | |||
| ChatGPT Retrieval Plugin | aggregator | ✓ | ✓ | |||
| Chroma | self-hosted | ✓ | ✓ | ✓ | ||
| DashVector | cloud | ✓ | ✓ | ✓ | ✓ | |
| Deeplake | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| DocArray | aggregator | ✓ | ✓ | ✓ | ||
| DynamoDB | cloud | ✓ | ||||
| Elasticsearch | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ |
| FAISS | in-memory | |||||
| txtai | in-memory | |||||
| Jaguar | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | |
| LanceDB | cloud | ✓ | ✓ | ✓ | ||
| Lantern | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ |
| Metal | cloud | ✓ | ✓ | ✓ | ||
| MongoDB Atlas | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| MyScale | cloud | ✓ | ✓ | ✓ | ✓ | |
| Milvus / Zilliz | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Neo4jVector | self-hosted / cloud | ✓ | ✓ | |||
| OpenSearch | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Pinecone | cloud | ✓ | ✓ | ✓ | ✓ | |
| Postgres | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ |
| pgvecto.rs | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | |
| Qdrant | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ |
| Redis | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Simple | in-memory | ✓ | ✓ | |||
| SingleStore | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Supabase | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Tair | cloud | ✓ | ✓ | ✓ | ||
| TencentVectorDB | cloud | ✓ | ✓ | ✓ | ✓ | |
| Timescale | ✓ | ✓ | ✓ | ✓ | ||
| Typesense | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Weaviate | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ |
Phần lớn cơ sở dữ liệu được hỗ trợ
| ector Store | Type | Metadata Filtering | Hybrid Search | Delete | Store Documents | Async | |
|---|---|---|---|---|---|---|---|
| DashVector | cloud | ✓ | ✓ | ✓ | ✓ | ||
| Elasticsearch | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ | 总觉得比较重 |
| Jaguar | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ||
| Lantern | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ | |
| MyScale | cloud | ✓ | ✓ | ✓ | ✓ | ||
| Pinecone | cloud | ✓ | ✓ | ✓ | ✓ | ||
| Postgres | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ | |
| pgvecto.rs | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ||
| Qdrant | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ | 创始人好像出走了 |
| TencentVectorDB | cloud | ✓ | ✓ | ✓ | ✓ | ||
| Weaviate | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ |
Elasticsearch:总觉得比较重
Postgress:先从最简单的开始吧。
Qdrant:创始人好像出走了。
Sự tương phản của Lang Chain đối với cơ sở dữ liệu
| 数据库名称 | 应用场景 |
|---|---|
| HNSWLib, Faiss, LanceDB, CloseVector | 如果你需要一个可以在你的Node.js应用程序中运行的内存数据库,无需其他服务器 |
| MemoryVectorStore, CloseVector | 如果你在寻找一个可以在类似浏览器的环境中内存中运行的东西 |
| HNSWLib, Faiss | 如果你来自Python,并且你在寻找类似于FAISS的东西 |
| Chroma | 如果你在寻找一个开源的、功能全面的向量数据库,可以在docker容器中本地运行 |
| Zep | 如果你在寻找一个开源的向量数据库,提供低延迟、本地嵌入文档支持,并且支持边缘上的应用 |
| Weaviate | 如果你在寻找一个开源的、生产就绪的向量数据库,可以在docker容器中本地运行或在云中托管 |
| Supabase vector store | 如果你已经在使用Supabase,看看Supabase向量存储,使用同一个Postgres数据库来存储你的嵌入 |
| Pinecone | 如果你在寻找一个生产就绪的向量存储,你不必担心自己托管 |
| SingleStore vector store | 如果你已经在使用SingleStore,或者你需要一个分布式、高性能的数据库,你可能会考虑SingleStore向量存储 |
| AnalyticDB vector store | 如果你在寻找一个在线MPP(大规模并行处理)数据仓库服务,你可能会考虑AnalyticDB向量存储 |
| MyScale | 如果你在寻找一个性价比高的向量数据库,允许使用SQL进行向量搜索 |
| CloseVector | 如果你在寻找一个可以从浏览器和服务器端加载的向量数据库,看看CloseVector。它是一个旨在跨平台的向量数据库 |
| ClickHouse | 如果你在寻找一个可扩展的、开源的列式数据库,对于分析查询有着出色的性能 |