Ragas
Hızlı Başlangıç
kavramı
| 概念 | 含义 |
|---|---|
| Question | |
| Contexts | Retrieved contexts:实际找到的Context |
| Answer | 最终生成的答案 |
| Ground truths | 参考答案 |
Veri setleri
from datasets import Dataset
data_samples = {
'question': ['When was the first super bowl?', 'Who won the most super bowls?'],
'answer': ['The first superbowl was held on January 15, 1967', 'The most super bowls have been won by The New England Patriots'],
'contexts' : [['The Super Bowl....season since 1966,','replacing the NFL...in February.'],
['The Green Bay Packers...Green Bay, Wisconsin.','The Packers compete...Football Conference']],
'ground_truth': ['The first superbowl was held on January 15, 1967', 'The New England Patriots have won the Super Bowl a record six times']
}
dataset = Dataset.from_dict(data_samples)
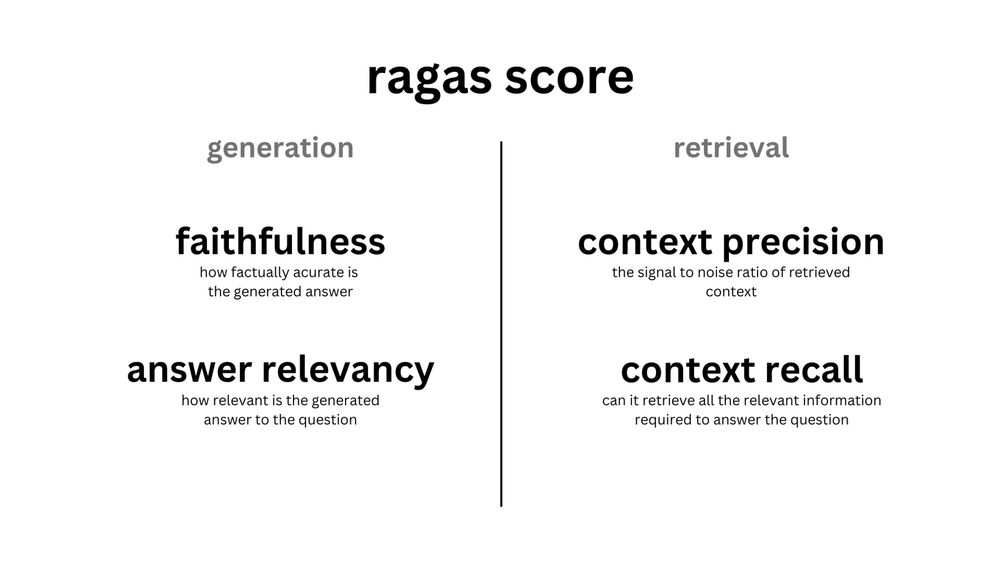
Metrikler
| Metric | |||
|---|---|---|---|
| Context Precision | Retrieval | Question | 是否跑题:检索结果 与 Quesion 是否相关 |
| Answer Relevance | Anwser | Question | 是否跑题:生成的答案 是否与 Question 相关 |
| Faithfulness | Anwser | Retrieval | 是否参考引用:生成的答案 是否忠诚于 检索结果 |
| Context Recall | Retrieval | 参考答案 Ground Truth | 检索的准确性: 检索结果 与 参考答案 是否相关 |
Prompt
Bağlam Hassaslığı
Given question, answer and context verify if the context was useful in arriving at the given answer. Give verdict as "1" if useful and "0" if not with json output.
The output should be a well-formatted JSON instance that conforms to the JSON schema below.
……
Your actual task:
question: 法国的首都是什么?
context: 巴黎是法国的首都。
answer: 巴黎
verification:
Yanıt Relevance
Bu Prompt 'ı anlayamıyorum
Generate a question for the given answer and Identify if answer is noncommittal. Give noncommittal as 1 if the answer is noncommittal and 0 if the answer is committal. A noncommittal answer is one that is evasive, vague, or ambiguous. For example, "I don't know" or "I'm not sure" are noncommittal answers
……
Your actual task:
answer: 巴黎
context: 巴黎是法国的首都。
output:
Sadıklık
Create one or more statements from each sentence in the given answer.
……
Your actual task:
question: 法国的首都是什么?
answer: 巴黎
statements:
Your task is to judge the faithfulness of a series of statements based on a given context. For each statement you must return verdict as 1 if the statement can be verified based on the context or 0 if the statement can not be verified based on the context.
……
Your actual task:
context: 巴黎是法国的首都。
statements: ["\u6cd5\u56fd\u7684\u9996\u90fd\u662f\u5df4\u9ece\u3002"]
answer:
Bağlam hatırlatma
Given a context, and an answer, analyze each sentence in the answer and classify if the sentence can be attributed to the given context or not. Use only "Yes" (1) or "No" (0) as a binary classification. Output json with reason.
……
Your actual task:
question: 法国的首都是什么?
context: 巴黎是法国的首都。
answer: 巴黎
classification:
Bileşik veriler üretm
Motivasyon: Belgeden yüzlerce QA (Soru-Belilim-Cevap) örneğini elle oluşturmak hem zaman alıcı hem de zahmetli olabilir. Otomatik üretimi için LLM kullanın.
Basit, ** reasoning, conditioning, multi-context **
Bu türlerin adı: Evrimler
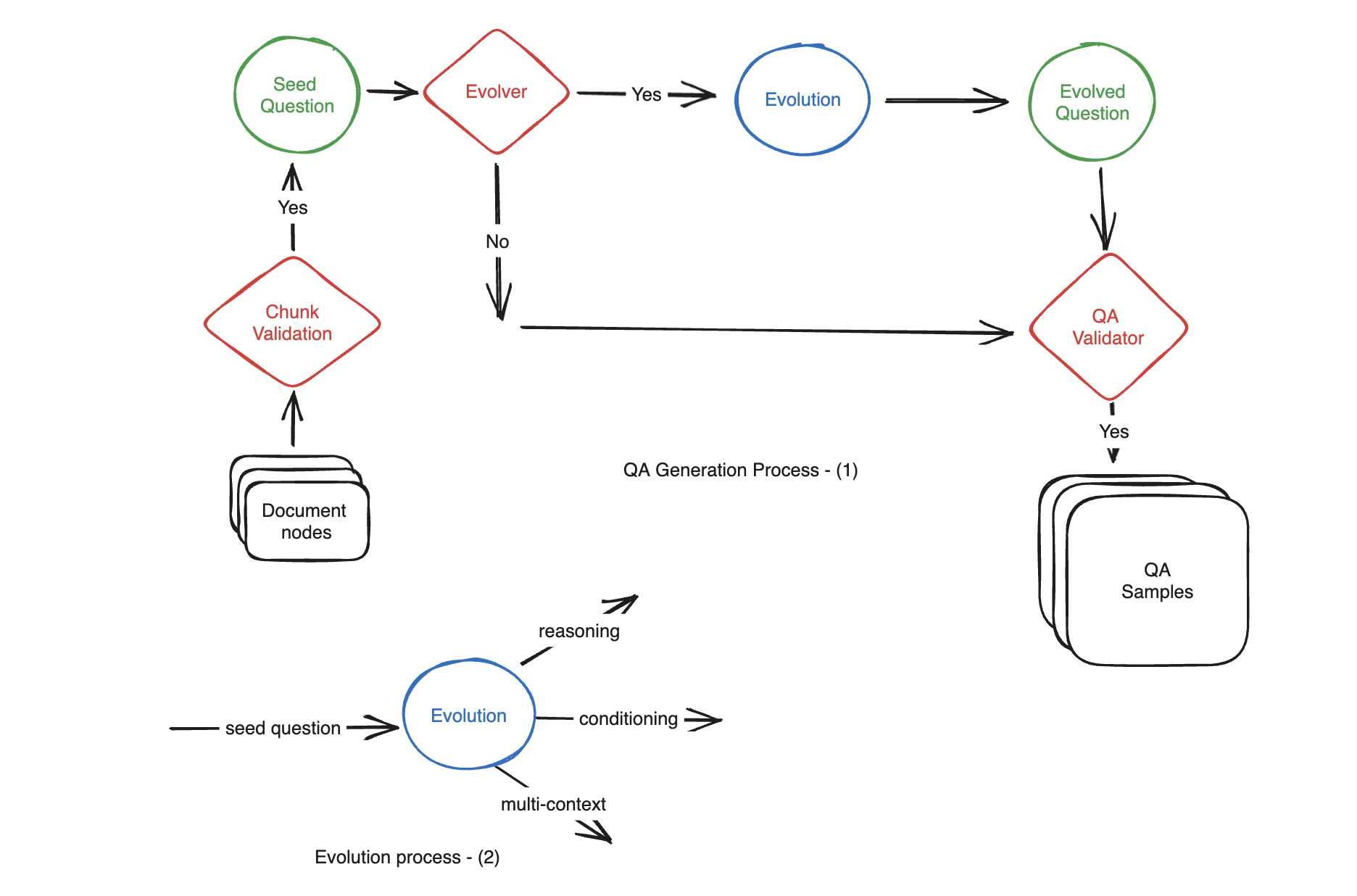
Oluşturulurken bu üç kategorinin oranlarını belirleyin.
from ragas.testset.generator import TestsetGenerator
from ragas.testset.evolutions import simple, reasoning, multi_context
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# documents = load your documents
# generator with openai models
generator_llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
critic_llm = ChatOpenAI(model="gpt-4")
embeddings = OpenAIEmbeddings()
generator = TestsetGenerator.from_langchain(
generator_llm,
critic_llm,
embeddings
)
# Change resulting question type distribution
distributions = {
simple: 0.5,
multi_context: 0.4,
reasoning: 0.1
}
# use generator.generate_with_llamaindex_docs if you use llama-index as document loader
testset = generator.generate_with_langchain_docs(documents, 10, distributions)
testset.to_pandas()
Verileri Oku
Resmi olarak LangChain'i kullanmak, LangChain'i kullanmaya devam etmek, sorunlar yaşamak kolay değil.
Otomatik Dil Uyumları
Değerlendirme
Değerlendirme sırasında kullanılan Prompt'ı gpt-4-turbo-preview modelini kullanarak Çince'ye çevirin; yerel önbelleğe alın.
İlgili metriklere ait istekler artık otomatik olarak hedef diline uyarlanacak.
Kaydetme adımı varsayılan olarak daha sonra yeniden kullanmak için
.cacha/ragasolarak kaydedilir.
# 将Metric中的Prompt翻译成中文
from datasets import Dataset
# from langchain.chat_models import ChatOpenAI
from langchain_openai import ChatOpenAI, OpenAI
from ragas.metrics import (
answer_relevancy,
faithfulness,
context_recall,
context_precision,
answer_correctness,
answer_similarity,
)
from ragas import evaluate
from ragas import adapt
eval_model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
# llm used for adaptation
openai_model = ChatOpenAI(model_name="gpt-4-turbo-preview")
# openai_model = OpenAI(model_name="gpt-4-0125-preview", temperature=0)
adapt(
metrics=[
answer_relevancy,
# faithfulness,
context_recall,
context_precision,
answer_correctness,
# answer_similarity,
],
language="Chinese",
llm=openai_model,
)
# Eval
dataset = Dataset.from_dict(
{
"question": ["法国的首都是什么?"],
"contexts": [["巴黎是法国的首都。"]],
"answer": ["巴黎"],
"ground_truths": [["巴黎"]],
}
)
print(dataset)
results = evaluate(dataset, llm=eval_model)
print(results)
Oluşturulan Önbelleklenmiş Veri
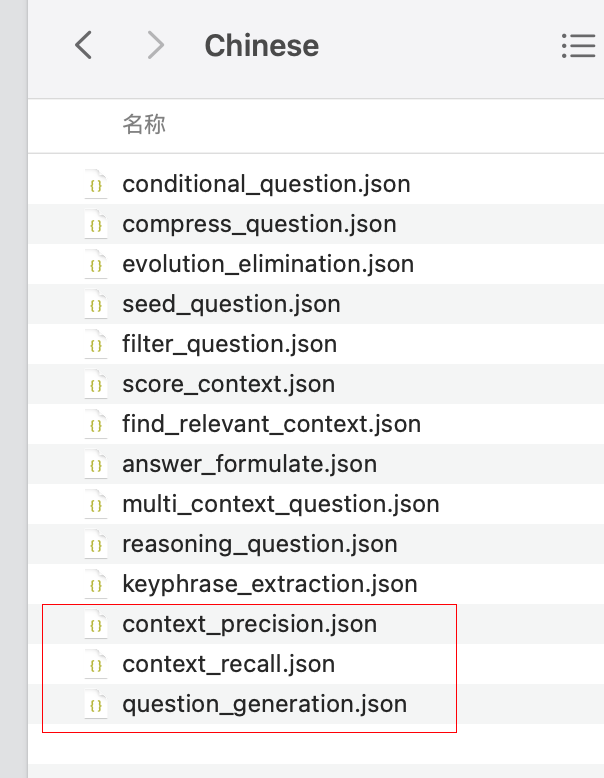
Bileşik veriler üretm
from ragas.testset.generator import TestsetGenerator
from ragas.testset.evolutions import simple, reasoning, multi_context,conditional
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# generator with openai models
generator_llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
critic_llm = ChatOpenAI(model="gpt-4")
embeddings = OpenAIEmbeddings()
generator = TestsetGenerator.from_langchain(
generator_llm,
critic_llm,
embeddings
)
# adapt to language
language = "Chinese"
generator.adapt(language, evolutions=[simple, reasoning,conditional,multi_context])
generator.save(evolutions=[simple, reasoning, multi_context,conditional])
Oluşturulan Önbelleklenmiş Veri
Dataset 'teki alanlar
- Soru
- contexts: alınan bağlam
- ground_truth: Referans Cevabı
- anwser: üretilen yanıtlar
- Question: A set of questions.
- Contexts: Retrieved contexts corresponding to each question. This is a
list[list]since each question can retrieve multiple text chunks. - Answer: Generated answer corresponding to each question.
- Temel gerçekler: Her soruya karşılık gelen temel gerçekler. Bu, her sorunun beklenen cevabına karşılık gelen bir
strdır.
Referans context geçici olarak kullanılmıyor
metrics=[
# 这几个都不需要原始的context
context_precision,
answer_relevancy,
faithfulness,
context_recall,
],
BGE Kullanımı
from ragas.llama_index import evaluate
flag_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-en-v1.5")
query_engine2 = build_query_engine(flag_model)
result = evaluate(query_engine2, metrics, test_questions, test_answers)
LangSmith 'in tümleşmesi
Ortam değişkenlerini ayarlama
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_ENDPOINT=https://api.smith.langchain.com
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
İzleyici Oluşturma
# langsmith
from langchain.callbacks.tracers import LangChainTracer
tracer = LangChainTracer(project_name="callback-experiments")
Değerlendirme sırasında kullanılır
from datasets import load_dataset
from ragas.metrics import context_precision
from ragas import evaluate
dataset = load_dataset("explodinggradients/amnesty_qa","english")
evaluate(dataset["train"],metrics=[context_precision],callbacks=[tracer])
Entegre LlamaIndex
官方文档有问题。