Ragas - Ragas
Bắt đầu nhanh
khái niệm / khái niệm / khái niệm
| 概念 | 含义 |
|---|---|
| Question | |
| Contexts | Retrieved contexts:实际找到的Context |
| Answer | 最终生成的答案 |
| Ground truths | 参考答案 |
Bộ dữ liệu (dataset)
from datasets import Dataset
data_samples = {
'question': ['When was the first super bowl?', 'Who won the most super bowls?'],
'answer': ['The first superbowl was held on January 15, 1967', 'The most super bowls have been won by The New England Patriots'],
'contexts' : [['The Super Bowl....season since 1966,','replacing the NFL...in February.'],
['The Green Bay Packers...Green Bay, Wisconsin.','The Packers compete...Football Conference']],
'ground_truth': ['The first superbowl was held on January 15, 1967', 'The New England Patriots have won the Super Bowl a record six times']
}
dataset = Dataset.from_dict(data_samples)
Số liệu
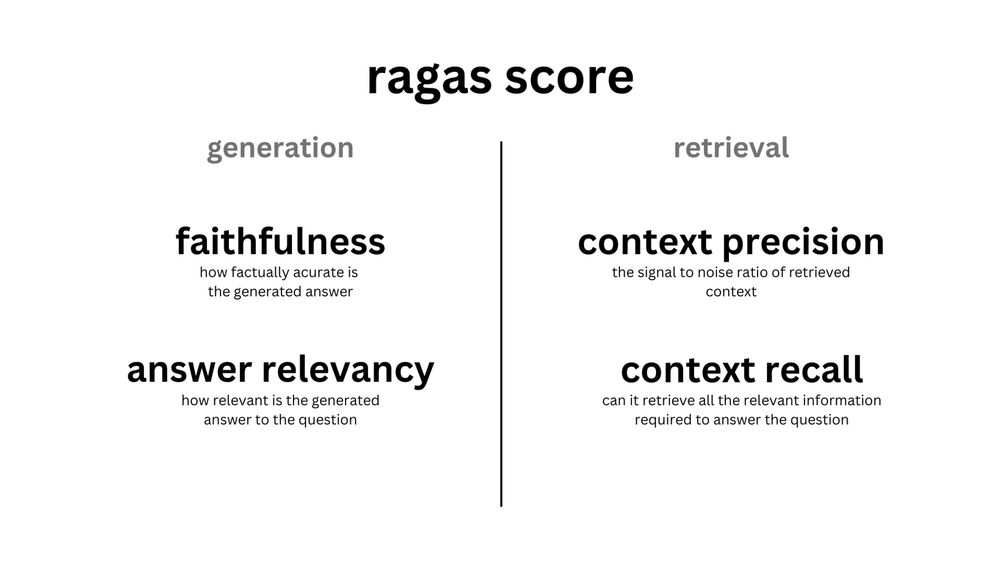
| Metric | |||
|---|---|---|---|
| Context Precision | Retrieval | Question | 是否跑题:检索结果 与 Quesion 是否相关 |
| Answer Relevance | Anwser | Question | 是否跑题:生成的答案 是否与 Question 相关 |
| Faithfulness | Anwser | Retrieval | 是否参考引用:生成的答案 是否忠诚于 检索结果 |
| Context Recall | Retrieval | 参考答案 Ground Truth | 检索的准确性: 检索结果 与 参考答案 是否相关 |
Đề nghị
Chính xác ngữ cảnh
Given question, answer and context verify if the context was useful in arriving at the given answer. Give verdict as "1" if useful and "0" if not with json output.
The output should be a well-formatted JSON instance that conforms to the JSON schema below.
……
Your actual task:
question: 法国的首都是什么?
context: 巴黎是法国的首都。
answer: 巴黎
verification:
Trả lời liên quan
Prompt này không hiểu
Generate a question for the given answer and Identify if answer is noncommittal. Give noncommittal as 1 if the answer is noncommittal and 0 if the answer is committal. A noncommittal answer is one that is evasive, vague, or ambiguous. For example, "I don't know" or "I'm not sure" are noncommittal answers
……
Your actual task:
answer: 巴黎
context: 巴黎是法国的首都。
output:
Lòng trung thành
Create one or more statements from each sentence in the given answer.
……
Your actual task:
question: 法国的首都是什么?
answer: 巴黎
statements:
Your task is to judge the faithfulness of a series of statements based on a given context. For each statement you must return verdict as 1 if the statement can be verified based on the context or 0 if the statement can not be verified based on the context.
……
Your actual task:
context: 巴黎是法国的首都。
statements: ["\u6cd5\u56fd\u7684\u9996\u90fd\u662f\u5df4\u9ece\u3002"]
answer:
Ghi nhớ ngữ cảnh
Given a context, and an answer, analyze each sentence in the answer and classify if the sentence can be attributed to the given context or not. Use only "Yes" (1) or "No" (0) as a binary classification. Output json with reason.
……
Your actual task:
question: 法国的首都是什么?
context: 巴黎是法国的首都。
answer: 巴黎
classification:
Tạo ra dữ liệu tổng hợp
Động cơ: Tạo thủ công hàng trăm mẫu QA (câu hỏi-bối cảnh-trả lời) từ tài liệu có thể tốn thời gian và tốn công sức. Sử dụng LLM để tạo tự động.
Phân loại: đơn giản, ** lý luận, điều kiện, đa ngữ cảnh**
Tên gọi của nó là: Evolutions
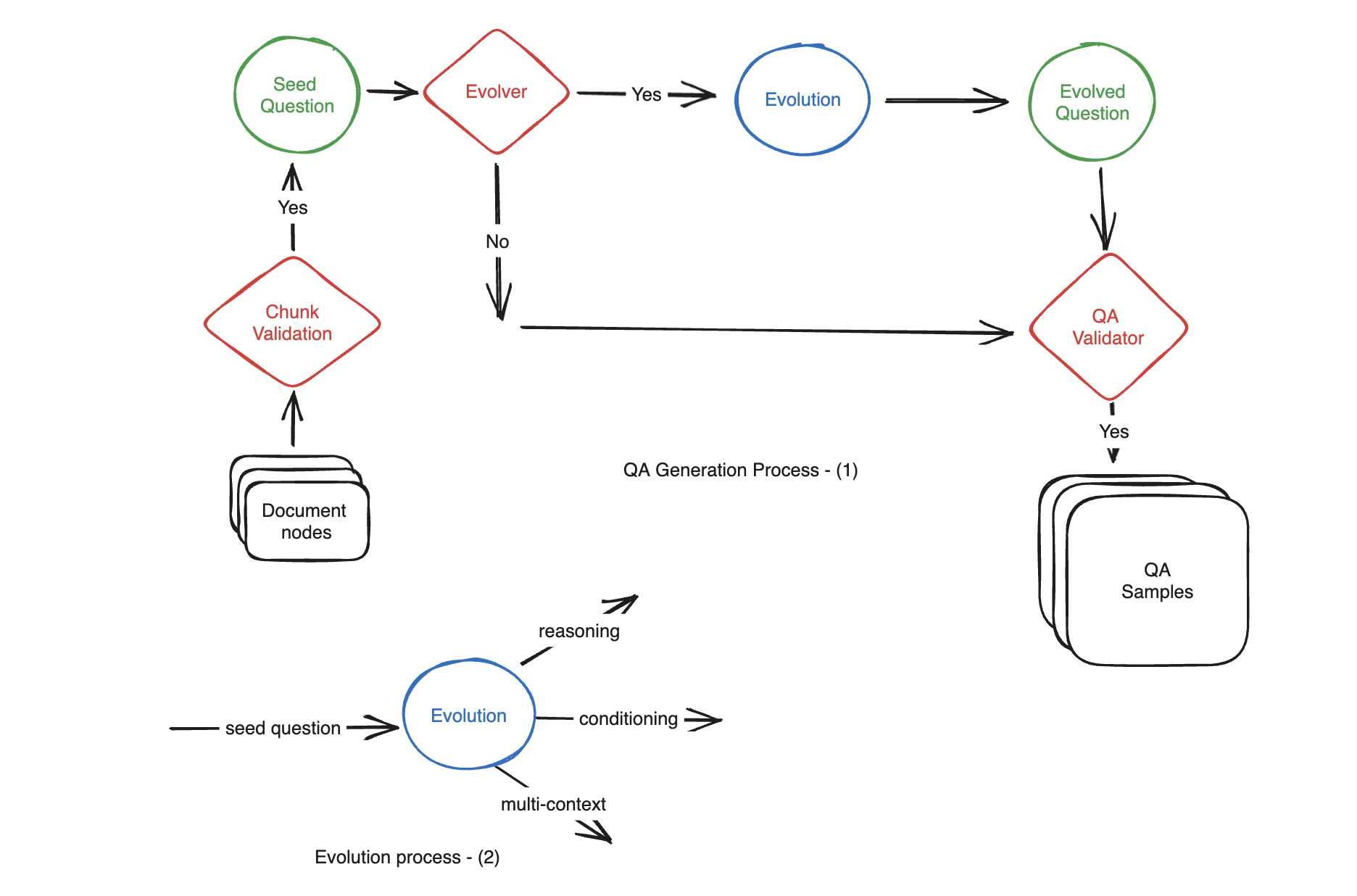
Khi tạo, chỉ định tỷ lệ của ba loại này.
from ragas.testset.generator import TestsetGenerator
from ragas.testset.evolutions import simple, reasoning, multi_context
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# documents = load your documents
# generator with openai models
generator_llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
critic_llm = ChatOpenAI(model="gpt-4")
embeddings = OpenAIEmbeddings()
generator = TestsetGenerator.from_langchain(
generator_llm,
critic_llm,
embeddings
)
# Change resulting question type distribution
distributions = {
simple: 0.5,
multi_context: 0.4,
reasoning: 0.1
}
# use generator.generate_with_llamaindex_docs if you use llama-index as document loader
testset = generator.generate_with_langchain_docs(documents, 10, distributions)
testset.to_pandas()
Đọc dữ liệu
Chính thức sử dụng LangChain, tiếp tục sử dụng LangChain, không dễ gặp vấn đề.
Tự động thích ứng ngôn ngữ
đánh giá / đánh giá / đánh giá
Dịch Prompt được sử dụng trong quá trình đánh giá sang tiếng Trung, sử dụng mô hình gpt-4-turbo-preview; bộ nhớ đệm cục bộ.
Các lời nhắc thuộc về các số liệu tương ứng bây giờ sẽ được tự động thích nghi với ngôn ngữ mục tiêu.
Bước lưu sẽ lưu nó vào
.cacha/ragastheo mặc định để sử dụng lại sau này.
# 将Metric中的Prompt翻译成中文
from datasets import Dataset
# from langchain.chat_models import ChatOpenAI
from langchain_openai import ChatOpenAI, OpenAI
from ragas.metrics import (
answer_relevancy,
faithfulness,
context_recall,
context_precision,
answer_correctness,
answer_similarity,
)
from ragas import evaluate
from ragas import adapt
eval_model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
# llm used for adaptation
openai_model = ChatOpenAI(model_name="gpt-4-turbo-preview")
# openai_model = OpenAI(model_name="gpt-4-0125-preview", temperature=0)
adapt(
metrics=[
answer_relevancy,
# faithfulness,
context_recall,
context_precision,
answer_correctness,
# answer_similarity,
],
language="Chinese",
llm=openai_model,
)
# Eval
dataset = Dataset.from_dict(
{
"question": ["法国的首都是什么?"],
"contexts": [["巴黎是法国的首都。"]],
"answer": ["巴黎"],
"ground_truths": [["巴黎"]],
}
)
print(dataset)
results = evaluate(dataset, llm=eval_model)
print(results)
Dữ liệu bộ nhớ đệm được tạo ra
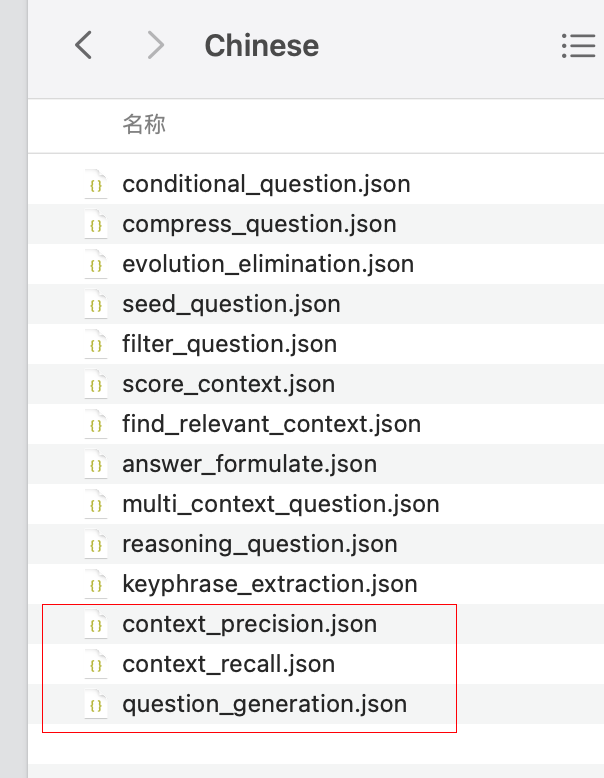
Tạo ra dữ liệu tổng hợp
from ragas.testset.generator import TestsetGenerator
from ragas.testset.evolutions import simple, reasoning, multi_context,conditional
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# generator with openai models
generator_llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
critic_llm = ChatOpenAI(model="gpt-4")
embeddings = OpenAIEmbeddings()
generator = TestsetGenerator.from_langchain(
generator_llm,
critic_llm,
embeddings
)
# adapt to language
language = "Chinese"
generator.adapt(language, evolutions=[simple, reasoning,conditional,multi_context])
generator.save(evolutions=[simple, reasoning, multi_context,conditional])
Dữ liệu bộ nhớ đệm được tạo ra
Các trường trong một tập dữ liệu
- Câu hỏi
- Context: Context được lấy ra
- ground_truth: Trả lời tham khảo
- anwser: câu trả lời được tạo ra
- Question: A set of questions.
- Contexts: Retrieved contexts corresponding to each question. This is a
list[list]since each question can retrieve multiple text chunks. - Answer: Generated answer corresponding to each question.
- Ground truths: Những sự thật cơ bản tương ứng với mỗi câu hỏi.Đây là một 'str' tương ứng với câu trả lời mong đợi cho mỗi câu hỏi.
Tạm thời không được sử dụng để tham chiếu context
metrics=[
# 这几个都不需要原始的context
context_precision,
answer_relevancy,
faithfulness,
context_recall,
],
Sử dụng BGE
from ragas.llama_index import evaluate
flag_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-en-v1.5")
query_engine2 = build_query_engine(flag_model)
result = evaluate(query_engine2, metrics, test_questions, test_answers)
Tích hợp LangSmith
Thiết lập các biến môi trường
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_ENDPOINT=https://api.smith.langchain.com
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"
Tạo một trình theo dõi
# langsmith
from langchain.callbacks.tracers import LangChainTracer
tracer = LangChainTracer(project_name="callback-experiments")
Sử dụng khi đánh giá
from datasets import load_dataset
from ragas.metrics import context_precision
from ragas import evaluate
dataset = load_dataset("explodinggradients/amnesty_qa","english")
evaluate(dataset["train"],metrics=[context_precision],callbacks=[tracer])
Tích hợp LlamaIndex
官方文档有问题。