Deep Eval và Confident AI
giá cả / giá cả
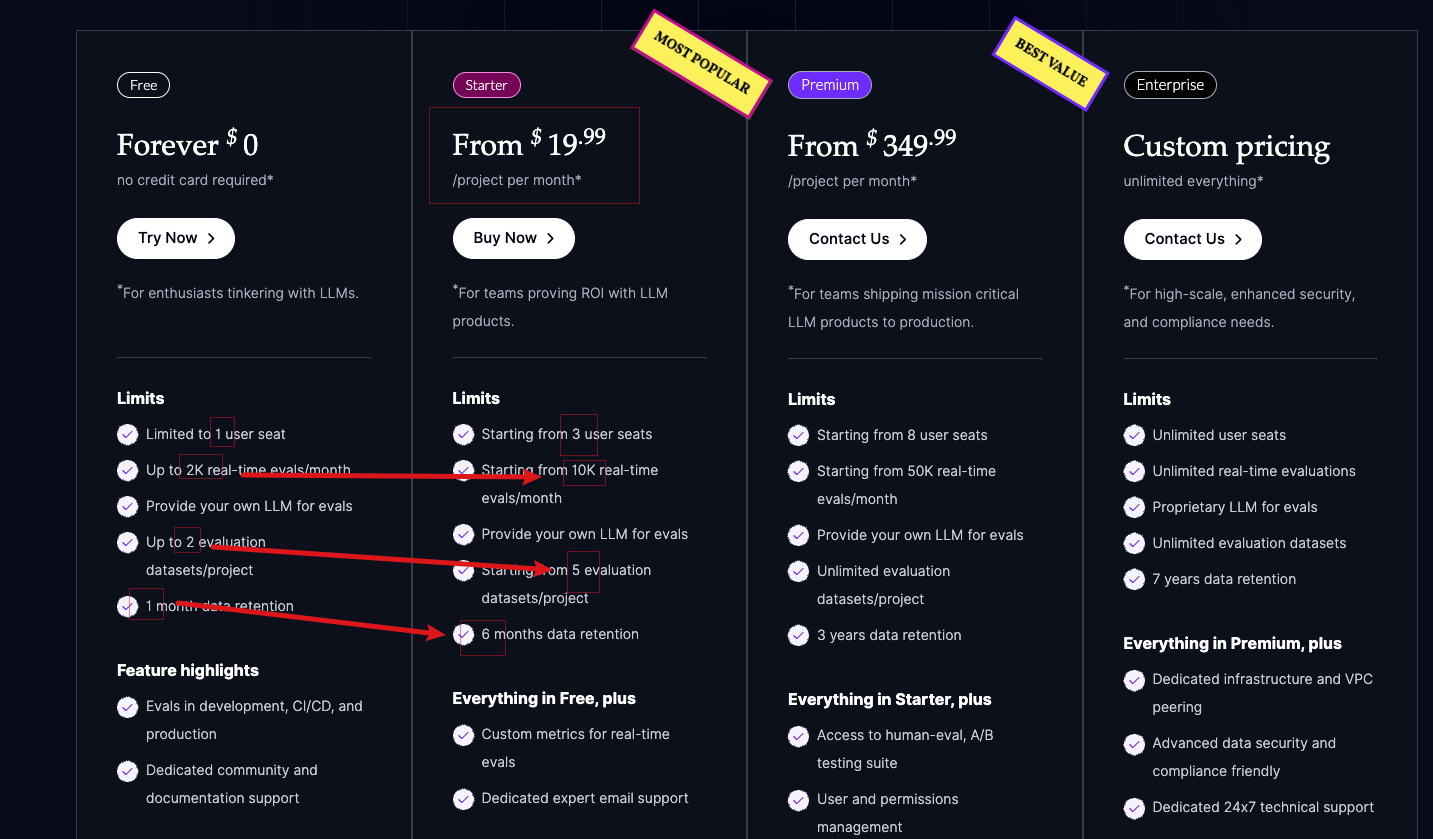
Bữa ăn miễn phí: cơ bản là đủ
Gói Starter: 20 USD / tháng
Bắt đầu nhanh
最新版本
pip install -U deepeval
注册 Confident AI
Nhận được API Key
hạ cánh / hạ cánh
deepeval login --api-key xxxx
Tạo tệp test_example.py
from deepeval import assert_test
from deepeval.test_case import LLMTestCase
from deepeval.metrics import AnswerRelevancyMetric
def test_answer_relevancy():
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.5)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output of your LLM application
actual_output="We offer a 30-day full refund at no extra cost."
)
assert_test(test_case, [answer_relevancy_metric])
Tên tệp phải bắt đầu bằng test_
chạy đi, chạy đi
deepeval test run test_example.py
Đặt thư mục để lưu kết quả
Thiết lập các biến môi trường
export DEEPEVAL_RESULTS_FOLDER="./deep-eval-results"
Các tham số của DeepVal Test Run
song song, song song
deepeval test run test_example.py -n 4
Bộ nhớ đệm (cache)
deepeval test run test_example.py -c
Lặp lại đi
deepeval test run test_example.py -r 2
cái móc / cái móc
...
@deepeval.on_test_run_end
def function_to_be_called_after_test_run():
print("Test finished!")
những khái niệm cơ bản
| Test Case | 包含input/actual_output/retrieval_context | |
| Dataset | Test Case的集合 | |
| Golden | 相比 test case,少了 actual_output |
Một trường hợp thử nghiệm thực tế
test_case = LLMTestCase(
input="Who is the current president of the United States of America?",
actual_output="Joe Biden",
retrieval_context=["Joe Biden serves as the current president of America."]
)
Sử dụng Pytest để đánh giá
from deepeval import assert_test
from deepeval.test_case import LLMTestCase
from deepeval.metrics import AnswerRelevancyMetric
dataset = EvaluationDataset(test_cases=[...])
@pytest.mark.parametrize(
"test_case",
dataset,
)
def test_customer_chatbot(test_case: LLMTestCase):
answer_relevancy_metric = AnswerRelevancyMetric()
assert_test(test_case, [answer_relevancy_metric])
@ pytest.mark.parametrizelà một bộ trang trí được cung cấp bởi Pytest. Nó chỉ là một vòng lặp để đánh giá từng trường hợp thử nghiệm từngEvaluationDatasetmột.
Chạy mà không cần CLI
# A hypothetical LLM application example
import chatbot
from deepeval import evaluate
from deepeval.metrics import HallucinationMetric
from deepeval.test_case import LLMTestCase
# ……
test_cases = [first_test_case, second_test_case]
metric = HallucinationMetric(threshold=0.7)
evaluate(test_cases, [metric])
Trường hợp thử nghiệm
Một trường hợp thử nghiệm tiêu chuẩn
test_case = LLMTestCase(
input="What if these shoes don't fit?", #必选
expected_output="You're eligible for a 30 day refund at no extra cost.", #必选
actual_output="We offer a 30-day full refund at no extra cost.",
context=["All customers are eligible for a 30 day full refund at no extra cost."], # 参考值
retrieval_context=["Only shoes can be refunded."], # 实际检索结果
latency=10.0
)
contextlà kết quả tìm kiếm lý tưởng cho một đầu vào đã cho, thường là từ một tập dữ liệu đánh giá,retrieval_contextKết quả tìm kiếm thực tế cho ứng dụng LLM.
Bộ dữ liệu (dataset)
Tạo bộ dữ liệu bằng tay và đẩy vào Confident AI
from deepeval.test_case import LLMTestCase
from deepeval.dataset import EvaluationDataset
# 原始数据
original_dataset = [
{
"input": "What are your operating hours?",
"actual_output": "...",
"context": [
"Our company operates from 10 AM to 6 PM, Monday to Friday.",
"We are closed on weekends and public holidays.",
"Our customer service is available 24/7.",
],
},
{
"input": "Do you offer free shipping?",
"actual_output": "...",
"expected_output": "Yes, we offer free shipping on orders over $50.",
},
{
"input": "What is your return policy?",
"actual_output": "...",
},
]
# 遍历,将生成 LLMTestCase 实例
test_cases = []
for datapoint in original_dataset:
input = datapoint.get("input", None)
actual_output = datapoint.get("actual_output", None)
expected_output = datapoint.get("expected_output", None)
context = datapoint.get("context", None)
test_case = LLMTestCase(
input=input,
actual_output=actual_output,
expected_output=expected_output,
context=context,
)
test_cases.append(test_case)
# 将 LLMTestCase 数组变成 EvaluationDataset
dataset = EvaluationDataset(test_cases=test_cases)
# 推送到Confident AI
dataset.push(alias="My Confident Dataset")
Xem các kết quả
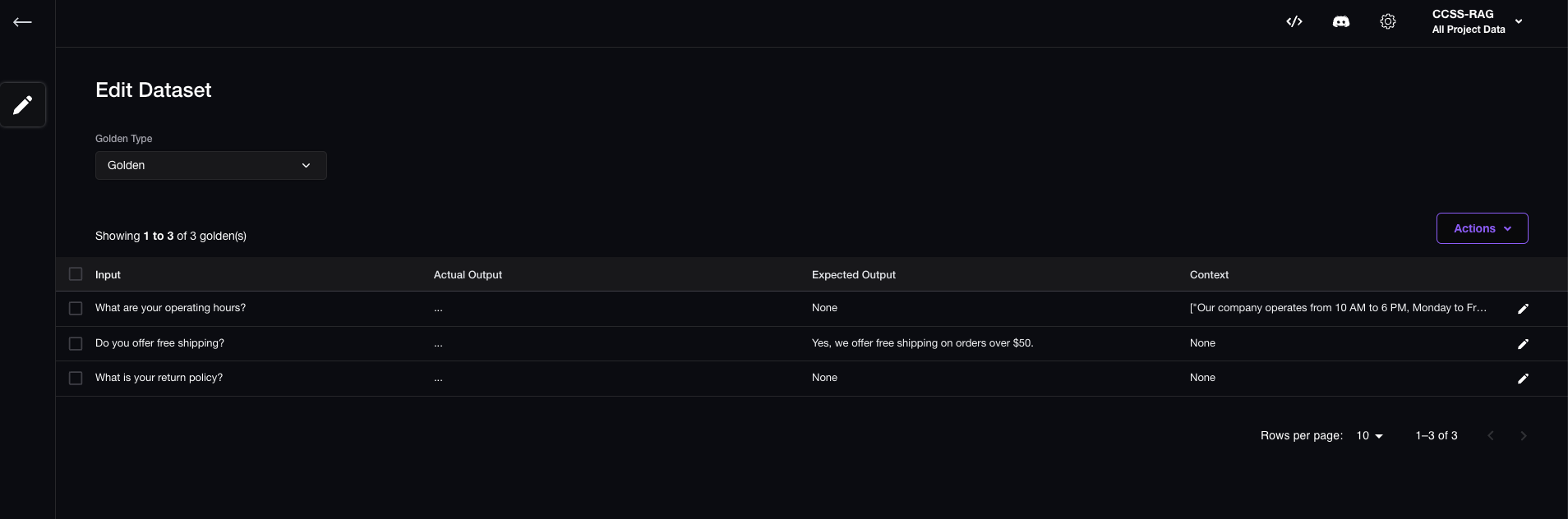
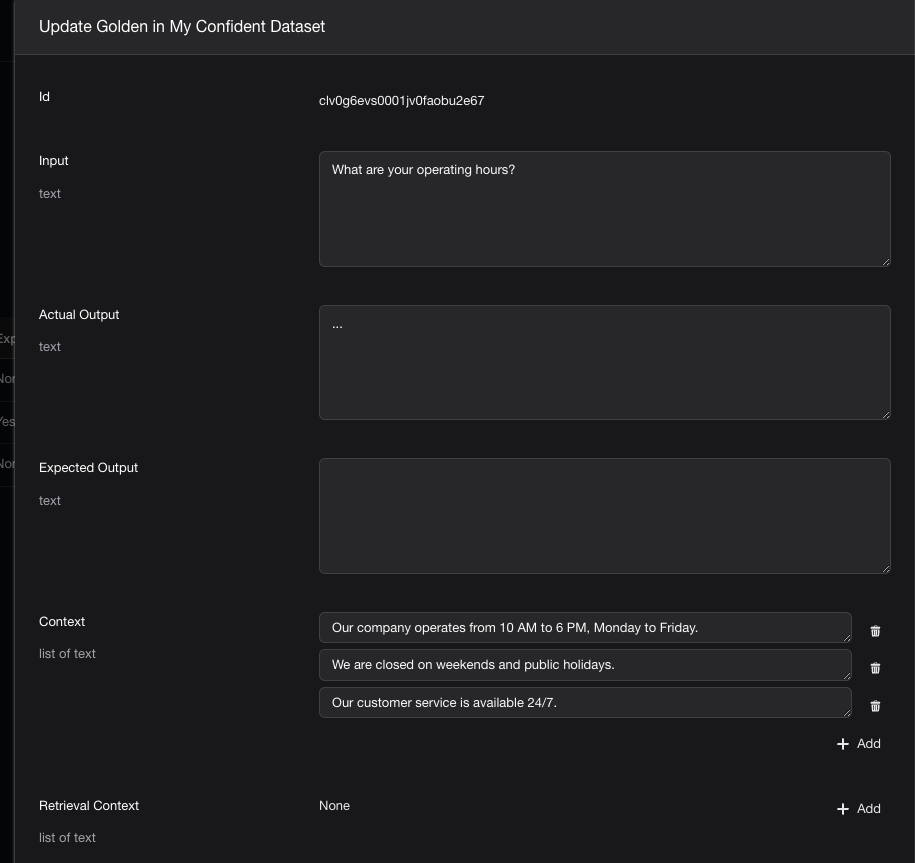
在Confident AI的Web UI手动创建
Hỗ trợ Tiếng Trung
Sửa đổi thủ công tất cả các Prompt dưới / Users/xxx/anaconda3/envs/LI311-b/lib/python3.11/site-packages/deepeval/synthesizer/template.py, thêm
6. `Rewritten Input` should be in Chinse.
Số liệu
kích thước của đánh giá
| 评估指标 | 描述 |
|---|---|
| 正确性和语义相似度 | 生成的答案 与 参考答案 的对比 |
| Context Relevancy | 查询 与 检索到的上下文 的相关性 |
| Faithfulness | 生成的答案 与 检索到的上下文 的一致性 |
| Answer Relevancy | 生成的答案 与 查询 的相关性 |